
For this TechUp, I took a closer look at Weaviate, an open-source vector database, and used it hands-on to build a blogpost recommendation system for our TechHub.
What is a vector database?
In a vector database, vectors are stored alongside traditional forms of data (strings, integers, etc.). These vectors are representations of the information stored in the database that can be better understood by computers.
For example, if we have a collection of sentences that we want to store, we could create a multi-dimensional vector for each sentence that represents the sentence. Each dimension of this vector represents a different characteristic of the sentence, for example, the frequency of occurrence of a word in the sentence that can be assigned to a certain category such as “food”. Such a vector is called embedding, more about this in a moment.
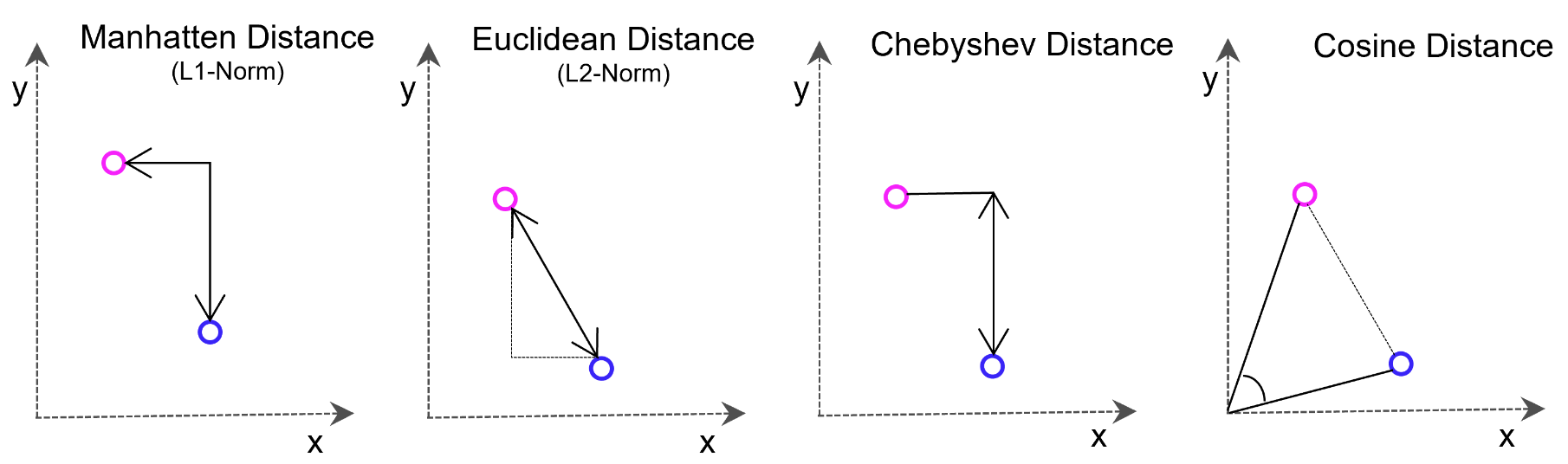
But what can you do with such a vector anyway? The idea is that vectors representing, for example, sentences with related content are closer together in the vector space. These distances can also be determined very quickly with high-dimensional vectors thanks to efficient mathematical methods, which makes vector databases attractive for search functions and deep learning.
Weaviate uses cosine distance measurement here by default, which simply calculates the angle between two vectors.
TLDR
The main advantage of a vector database is that it allows fast and accurate similarity search and data retrieval, based on the vector distance or similarity between individual data elements. This means that instead of using traditional methods to query databases based on exact matches or predefined criteria, a vector database can be used to find the most similar / relevant data based on its semantic or contextual meaning.
What is text embedding and how is it generated?
Text embeddings are vectors created by projecting a text (semantic space) onto a vector space (number space). The idea is to condense the features of a given text and map them into a vector. Such embeddings are generated using machine learning models that have been trained on large amounts of text data. There are several techniques for generating text embeddings, but one of the most common and effective methods is to use so-called “word embedding” or “sentence embedding” models. Here I explain what is behind each:
- Word Embeddings
- Word embeddings are number vectors that assign a unique representation to each word in a text corpus.
- A frequently used method for generating word embeddings is Word2Vec. It uses a neural network to learn the vector representations for words. Word2Vec uses the context of words by analysing neighbouring words in a sentence or document. This embeds similar words in a similar numerical space.
- Another popular model is GloVe (Global Vectors for Word Representation). It uses statistical information from global text statistics to capture semantic relationships between words.
- Sentence Embeddings
- Sentence embeddings are similar to word embeddings, but here complete sentences or paragraphs are converted into number vectors.
- A commonly used model for generating sentence embeddings is the “encoder-decoder model “, in particular the bidirectional encoder-decoder model (e.g. LSTM or GRU). It learns to encode a variable number of words into a vector containing the meaning of the sentence.
- Transformer models, such as the well-known “BERT” (Bidirectional Encoder Representations from Transformers), are also very effective in generating sentence embeddings. These models use attention mechanisms to generate contextual embeddings.
Simple example architecture
!—
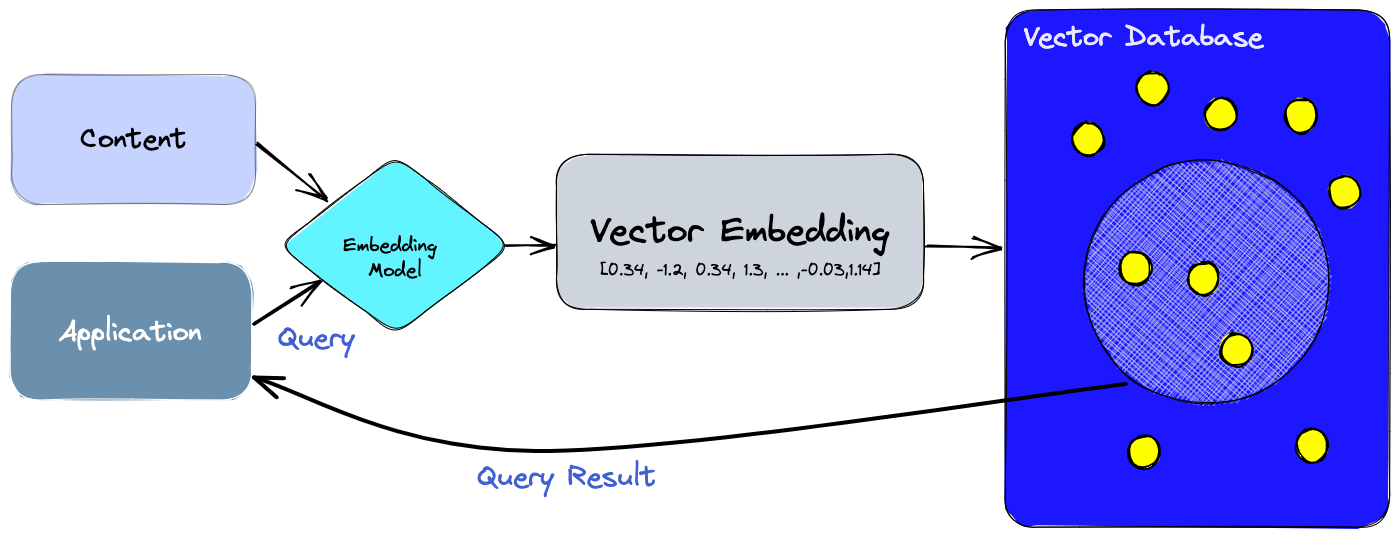 !—
Figure: Source: sanity.io
!—
Figure: Source: sanity.io
Feeding data
When data is fed into the database, it first passes through the embedding model, which returns a vector representation of the data. The original data is then stored in the database along with the corresponding vector.
Query data
Data can be queried in a variety of ways. In addition to exact matches based on fixed input parameters, as is common in traditional databases, there is also the option of entering any text, from which a vector is also created via the embedding model and compared with the other entries (semantic search). From this vector, the distance to other nearby vectors can then be determined and the results returned to the application.
How can Weaviate be used?
- Weaviate Cloud Services: A SaaS offering, handy for development and production use.
- Docker Compose: Practical for local development.
- Kubernetes: Typically used for productive deployment.
- Embedded Weaviate: Experimental Feature.
Hands-On Blogpost Recommendation with Weaviate
To get to know Weaviate better, I had just started Getting started, but realised quite quickly the potential to use it to implement something I had had on my radar for a while: TechUp recommendations, and not just based on tags of the current TechUp, but intelligent and playful, ideally based on the whole text.
Since the embeddings model of HuggingFace used here only accepts a maximum of 256 words and has been trained on single sentences, we do not provide the whole text here for creating the vectors, but only title, tags, url, description.
Setup
For the local setup I proceeded as in the Quickstart of Weaviate. In this tutorial I use Python 3.11 in a Jupyter Notebook. First we need to install the Weaviate client.
|
|
Now we can create a free sandbox instance of Weaviate, get its API key and URL and connect to the instance. We also import a library requests for HTTP requests, which we will need later.
|
|
Import data
Now we create a class called Techup that will host our data.
|
|
In this case, we use this model from HuggingFace to create the embeddings: sentence-transformers/all-MiniLM-L6-v2.
Next, let’s get some data that we want to use. In this case, the goal is to recommend other blogposts based on a given blogpost.
|
|
If we look at one of these blogposts with print(data[2]), we get, for example:
|
|
So we have stored our data in data. For each TechUp, we now want to import title, tags, url and description into our Weaviate instance into the Techup object and to do this we run the following code in our Jupyter Notebook:
|
|
We see how the import goes through successfully at best. Now let’s run a database query on Weaviate.
Semantic search
The aemantic search allows us to search Weaviate for entries that have something to do with the input text, but do not necessarily contain exactly the given text 1:1.
We define with .get() the object Techup, from which we want to get only the url of each blog entry. With .with_near_text() we define our search query "Serverless", for which we want to get the most appropriate blog posts (can be a sentence or more instead of a word). As already seen, this search query is first processed into an embedding (vector) and then the vector distance between this and all other vectors is calculated. .with_limit() is the number of results we want to get back and with .with_additional() we set that we also want to get back the vector distance of each entry relative to the vector to the search query “Serverless” and the ID. The whole thing then looks like this:
|
|
And we get this response back when we run print(json.dumps(response, indent=2)).
|
|
Blog recommendations
Now I want to get five matching blog posts based on a given blog post URL. To do this, I have defined the following two methods:
|
|
To get the object ID of a blog post, I defined a filter in getID() that looks for exactly those entries in Weaviate that contain the same ID. This is a small workaround, as there would also be the possibility to assign an ID to each object when sending it to Weaviate, and we could then call the object directly, without the code in getID().
Now we can call getRecommendations() with the URL of one of our blogposts and the number of results we want to get back:
|
|
|
|
It works! 🤩
Visualisation of the data
The high-dimensional vectors assigned to each object in our database can also be projected onto the two-dimensional plane, among other things. This allows us to visualise the relationship between our database entries.
We get the data we need for this from our weaviate by passing in the arguments featureProjection and dimensions:
|
|
Now we get back a 2D vector in the json response for each blogpost, for example: {'featureProjection': {'vector': [81.65559, -31.689371]}}, 'title': 'Increase your productivity with Alfred'}.
To visualise this, I had some code generated using ChatGPT 3.5, which returns us a descriptive graph:
|
|
Conclusion
All in all, I was pleasantly surprised by Weaviate. The focus on developer experience is noticeable, because even while I was working through Getting Started, it made me want to do more with it right away. Taking advantage of vector databases has become extremely easy thanks to providers like Weaviate - there are of course other players on the market that you should also take a closer look at before making a decision, but Weaviate is already very attractive due to the fact that it is open source.
Now I have fed the title of this blog post to our specially built Recommendation Engine and recommend the following TechUps for further reading (we only have one other TechUp on databases, so there is no great correlation here):
Try it out and stay tuned! 🚀
This TechUp has been automatically translated by our Markdown Translator. 🔥