
In diesem TechUp schaue ich mir Materialize und die damit verbundenen Konzepte genauer an. Materialize wurde 2019 von Frank McSherry (Chief Scientist) und Arjun Narayan (CEO) gegründet und bezeichnet sich als Streaming Database - was das bedeutet schauen wir uns gleich an. Interessanterweise hatte McSherry, der ab etwa 2013 an einem Forschungsprojekt namens Naiad beteiligt war und dort das Konzept von Timely / Differential Dataflow mitentwickelte, welches nun den Kern der Materialize Engine darstellt, anfangs gar kein Interesse daran, diese Technologie in ein kommerzielles, verwendbares Produkt umzuwandeln. Nach langanhaltender Überzeugungsarbeit seitens Narayan, der sich zu dieser Zeit viel mit der Thematik auseinandersetzte und deren Potential sah, taten die beiden sich schlussendlich zusammen und stellten dieses leistungsfähige Produkt auf die Beine.
Neben meinen Recherchen im Internet und in zahlreichen Beiträgen auf Materialize’s Website, hatte ich auch die Möglichkeit das Cloud-Native SaaS-Angebot von Materialize hands-on in der Early Access auszuprobieren. Und um ganz ehrlich zu sein, ich bin ein ziemlicher Fan, denn die Idee hinter Materialize hat mich überzeugt. Bevor wir uns Materialize anschauen, müssen wir wissen, was mit einer Streaming Database überhaupt gemeint ist.
Was ist eine Streaming Database? 🤔
Kurz vorab, mit “Streaming” ist hier nicht das Konsumieren von Video- oder Audiodateien konventioneller Streaminganbieter wie YouTube oder Spotify gemeint, sondern ein kontinuierlicher Fluss generierter Daten, die in Echtzeit entstehen und weiterverarbeitet werden können. Wenn du mehr über dieses Thema erfahren möchtest, ist unser TechUp zu Kafka ein guter Einstiegspunkt in die Welt der Streamingdaten und Message-Brokers.
Bei traditioneller Verarbeitung von Streaming-Daten wird oft ein zusätzlicher Microservice benötigt, um Transformationen vorzunehmen und die Daten in eine Datenbank einzuspeisen:
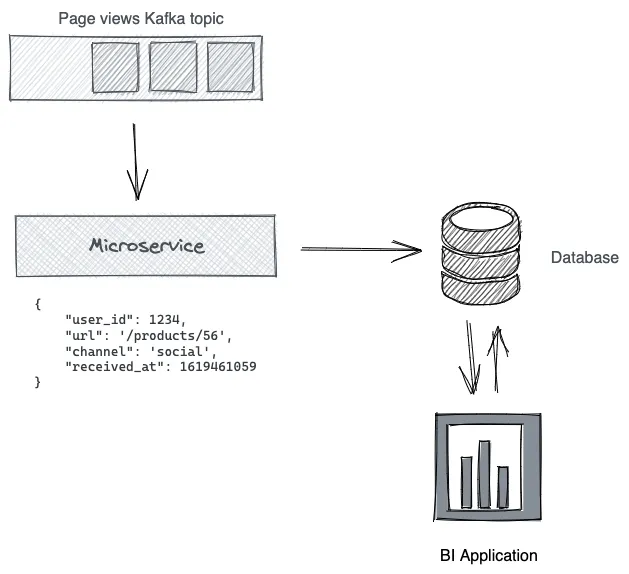
Eine Streaming Database hat die gleichen Abstraktionen (Tabellen, Spalten, Zeilen, Indizes) wie eine traditionelle Database, verwendet aber eine Stream Processing Engine anstatt einer Query Engine. Die Arbeit wird auf Write-Seite, anstatt auf der Read-Seite gemacht, wodurch man grob sagen könnte, dass eine Streaming Database eine Umkehrung einer traditionellen Datenbank darstellt. Dabei fällt der Microservice in der Grafik weg, was die Komplexität verringert.
Auf der Website von Materialize gibt es dazu einen tollen Beitrag, der die Funktionsweise einer Streaming Database sehr gut veranschaulicht.
Was ist so besonders an Materialize? 🤓
Nun, die Prämisse von Materialize ist es, das Resultat einer Datenbankabfrage (Query) möglichst schnell, korrekt und als Nebeneffekt auch möglichst effizient zu liefern. Um die Einstiegshürde gering zu halten, werden Queries mit altbewährtem SQL (ANSI-Standard) abgesetzt. Es ist von der Bedienung her also kaum ein Unterschied zu herkömmlichen relationellen Datenbanken zu spüren. Das ist aber auch plump gesagt auch (fast) das einzige, was Materialize mit herkömmlichen Datenbanken gemeinsam hat.
ℹ️ Streaming SQL: Da es sich hier um die Abfrage sich kontinuierlich verändernder Datenströme (Streams) mit SQL handelt, verwenden wir mehrheitlich SQL-Befehle, die sich kontinuierlich aktualisieren - dies wird Streaming SQL genannt.
Materialize bietet die höchste Konsistenzgarantie
Hierbei geht es simpel gesagt darum, wie korrekt die Ergebnisse einer Datenbankabfrage zu einem spezifischen Zeitpunkt sind. Materialize bietet die höchste Konsistenzgarantie, nämlich Strikte Serialisierbarkeit. Das garantiert, dass trotz stets neuer hinzukommender Daten und komplexer Queries, die darauf angewandt werden, das Ergebnis einer Abfrage absolut korrekt ist.
Dass Materialize Konsistenz, Skalierbarkeit und Low-Latency erfolgreich vereint ist bemerkenswert. Um zu verstehen, was Materialize nun so viel schneller macht, müssen wir einen kleinen Exkurs zum Thema SQL Views machen.
Views und materialisierte Views
Grundsätzlich können wir mit einer Query Daten aus einer Datenbank abfragen und gleichzeitig nach Wunsch Operationen darauf ausführen, um aus den Daten die Informationen so zu erhalten, wie wir sie gerne hätten. Eine Query könnte so aussehen:
|
|
Ist dies eine Abfrage, die wir ab und zu wiederholen möchten, würde es Sinn machen diese als VIEW abzuspeichern.
Was ist eine View?
Eine View macht nichts anderes als unsere SQL-Query unter einem Namen abzuspeichern, und bietet sozusagen einen Alias für unsere Query. Das sieht dann so aus:
|
|
Jetzt können wir unsere ursprüngliche Query einfach unter my_view folgendermassen abfragen: SELECT * FROM my_view.
Das Problem: Wenn wir die Resultate unserer Query einsehen möchten, müssen wir sie ausführen. Dabei muss jedes Mal die Berechnung neu ausgeführt werden. Das kostet nicht nur Zeit, sondern auch Rechenleistung - und somit Geld. Aber auch für dieses Problem gibt es eine Lösung - materialisierte Views!
Batch-Processing in herkömmlichen Datenbanken
Für Queries, die zu lange dauern und / oder zu kostenintensiv sind, würde es doch Sinn machen diese beispielsweise ein Mal am Tag oder alle paar Stunden auszuführen, und die Resultate abzuspeichern, nicht? Tatsache, das ist in der Industrie weit verbreitet und als Batch-Processing bekannt. Um die Zwischenergebnisse einer Anfrage zu speichern gibt es in Datenbanken ausserdem das Konzept einer materialisierten View. Dabei wird eine gegebene Query genau wie bei einer View gespeichert und zusätzlich das Ergebnis in einer “virtuellen” Tabelle gespeichert. Wir müssen nur das Keyword MATERIALIZED hinzufügen - die Ergebnisse der Query sind nun jederzeit verfügbar und können schnell ausgelesen werden:
|
|
Eine traditionelle materialisierte View bzw. traditionelles Batch Processing hat den Nachteil, dass die resultierende virtuelle Tabelle eine art Snapshot ist und, sobald sich etwas an den zugrundeliegenden Daten ändert, nicht mehr auf dem neuesten Stand ist. Ein anderer Faktor ist, dass die Implementation materialisierter Views in traditionellen Datenbanken unterschiedlich ist, und die zugrundeliegende Query für jede ausgelöste Aktualisierung der View komplett neu berechnet werden muss, was zu hohen kosten und erhöhter Komplexität führen kann.
Das ist ein Problem, denn die wertvollsten Daten sind die aktuellsten Daten. Als Unternehmen möchte man stets auf aktuelle Ereignisse reagieren können, wie diese Grafik veranschaulicht:
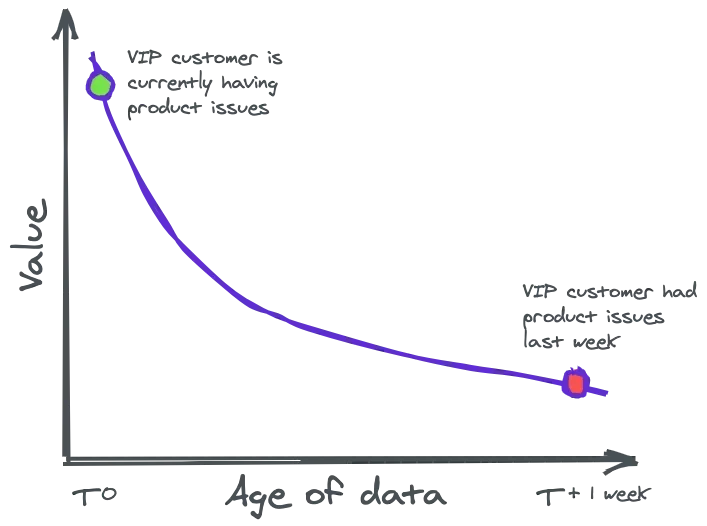
Figure: Quelle: Materialize
- Beispiel 1: Angenommen ein Nutzer deines Webdienstes hat Probleme. Anstatt erst am nächsten Tag die Meldung zu kriegen, dass ein Nutzer am Vortag Probleme hatte, wäre es viel besser eine Echtzeitmeldung zu kriegen und direkt mit dem Kunden an einer Lösung zu arbeiten.
- Beispiel 2: Ein Kunde ist auf deiner E-Commerce-Website unterwegs und schaut sich Produkte an. Der Kunde scheint sich für eine spezifische Kombination diverser Produkte zu interessieren, welche leider nicht Teil des aktuell laufenden Spezialangebots sind. Wäre es nicht praktisch, ihm anhand seines Kundenprofils einen passenderen Preis oder gar ein massgeschneidertes Angebot anzubieten, ihm eine potentielle Kaufentscheidung zu erleichtern?
Dafür benötigen wir Daten, die so aktuell wie möglich sind. Aber wie schaffen die Ergebnisse wir es komplexe und teure Datenbankabfragen auf dem allerneusten Stand zu kriegen?
Inkrementell aktualisierte materialisierte Views in Materialize
Das besondere an Materialize ist die Fähigkeit, Views inkrementell zu aktualisieren. Das heisst: Das Ergebnis der Query wird jederzeit auf dem neuesten Stand gehalten. Zugleich wird kein Rechenaufwand verschwendet, um Informationen abzufragen, die eigentlich bereits abgefragt wurden. Aber wie soll das gehen? Hier kommt das Konzept von Timely / Differential Dataflow ins Spiel, die Idee ist simpel: Sobald neue Daten hinzukommen, wird nur die Transformation der neuen Daten vorgenommen, und die View aktualisiert. Das ist der Kern der Magie von Materialize.
Aber wie funktioniert das ganze nun?
Es sind viele Szenarien einer Nutzung von Materialize denkbar, aber hier mal die Grundidee:
-
Verbinde Materialize mit einem oder mehreren Datenströmen, sogenannte Sources, wie beispielsweise aus:
- Kafka Topics
- PostgreSQL Change Data Capture
- Redpanda
-
Kreiere mit SQL komplexe materialisierte Views, die deine Daten so aufbereitet zu Verfügung stellen, wie es für deinen Usecase nötig ist.
- Stoppe hier und verwende Materialize als Datenbank, die deine komplexen SQL-Transformationen in Echtzeit und mit der höchsten Konsistenzgarantie (Strikte Serialisierbarkeit) allzeit bereit hält.
- Kreiere Sinks, um Änderungen deiner materialisierten Views (CDC) wiederum als Event-Streams an weitere “Konsumenten” auszugeben.
Meine Erfahrungen mit Materialize
Sobald ich den Zugang zur Early-Access Cloud-Version von Materialize erhielt, habe ich das Getting Started durchgearbeitet. Der Prozess war wirklich sehr einfach und ich hatte in kürzester Zeit per CLI zwei von Materialize bereitgestellte Kafka-Sources mit meinem Cluster verbunden und eine materialisierte View erstellt, die die Daten der beiden Sources kombiniert sowie das Ergebnis der Transformation speichert.
Einfache Visualisierung der Daten mit Metabase
Da mir das Ganze in der CLI etwas zu unübersichtlich war, machte ich mich auf die Suche nach einer einfachen Möglichkeit die Daten anzuzeigen, um die versprochene inkrementell aktualisierte materialisierte View auch wirklich in Aktion zu sehen. Ich wurde auf der Integrations-Page in der Materialize Docs fündig und entschied mich, Materialize mit Metabase, einem Business Intelligence (BI) Tool, zu verbinden.
Dazu habe ich Metabase von der Website als .jar runtergeladen und lokal ausgeführt. Dann musste ich nur die Metabase-Instanz unter localhost:3000 aufrufen und konnte direkt meine Materialize Cloud-Instanz verbinden. Metabase hat automatisch alle bereits erstellten Views aus Materialize ausgelesen und anschaulich dargestellt.
Hier habe ich mit Metabase die Verteilung der Produktkäufe nach Kategorie während den letzten fünf Minuten visualisiert. Wir sehen, dass sich die Daten in Realzeit aktualisieren.
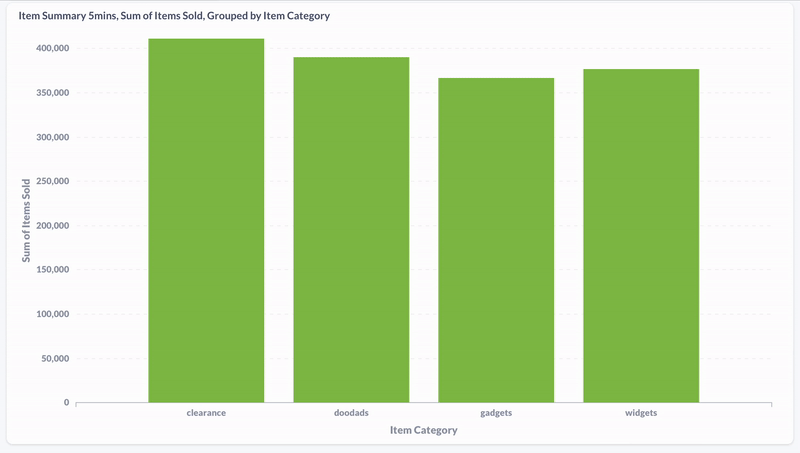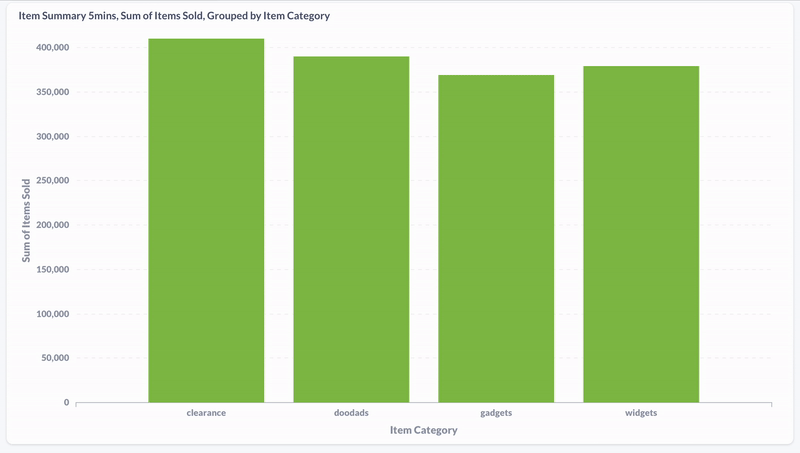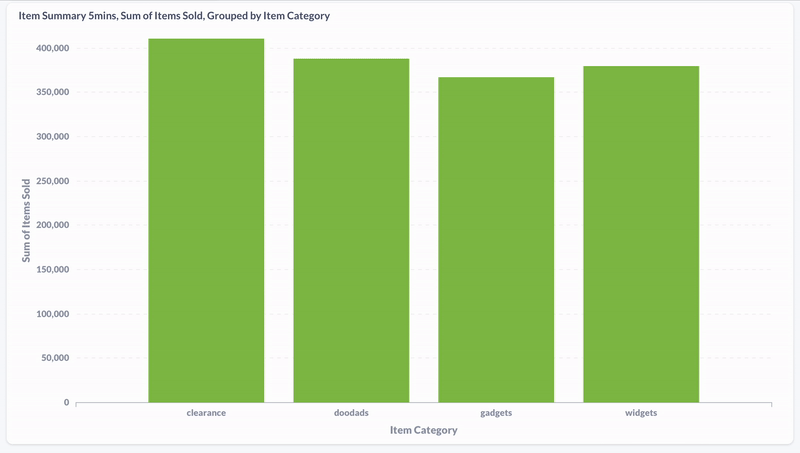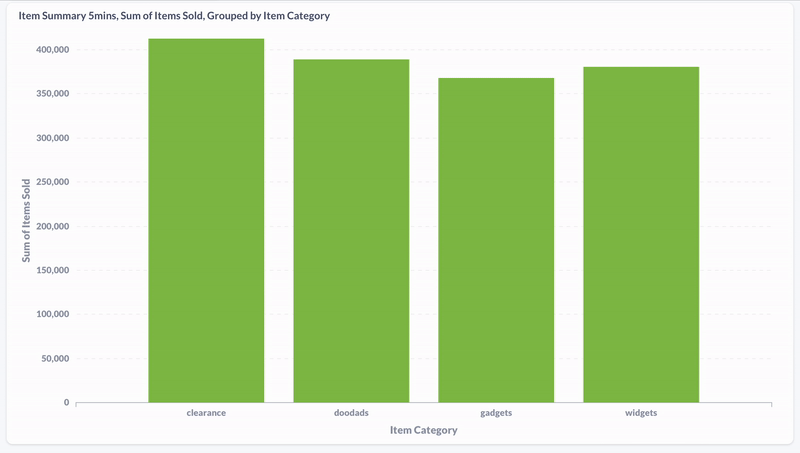
Und hier die Aufnahme einer materialisierten View, die die zuletzt gekauften Produkte der vergangenen fünf Minuten anzeigt:
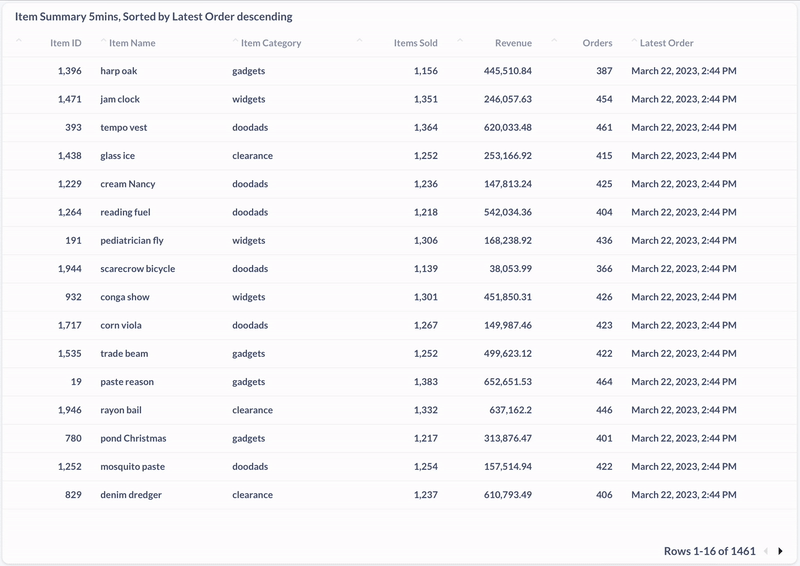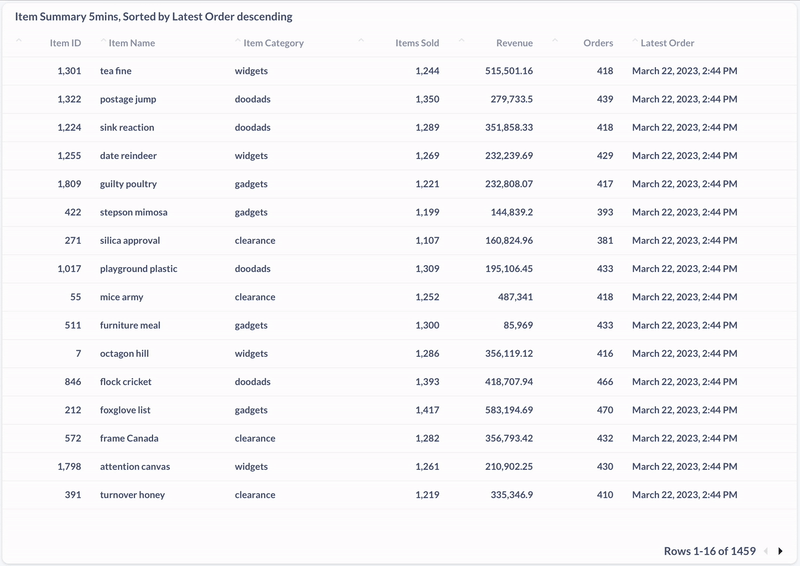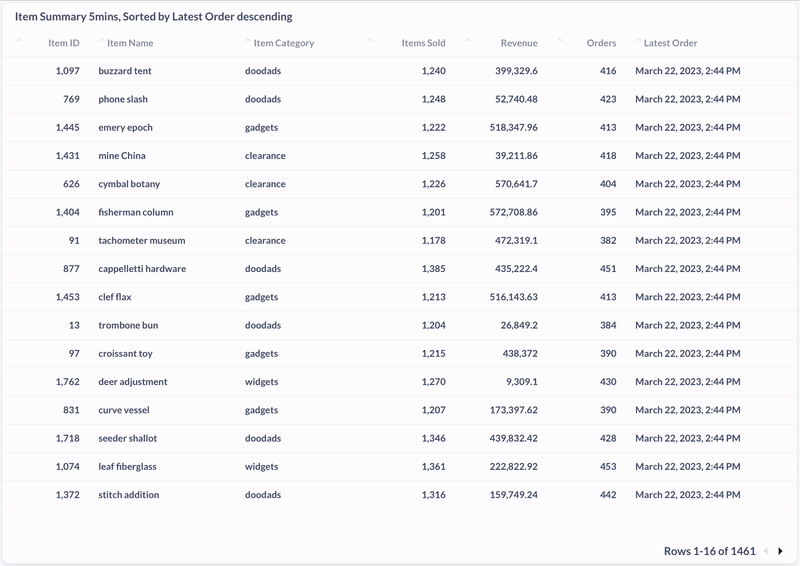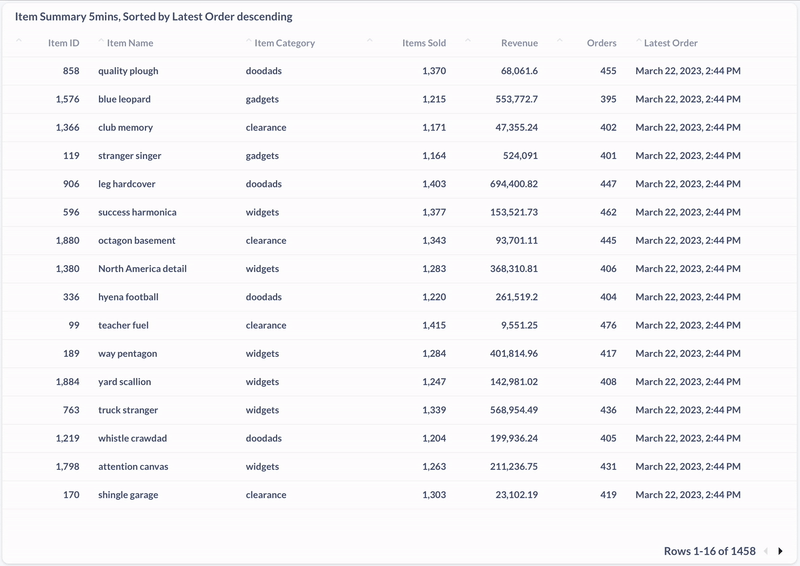
Fazit
Die Grundidee, nämlich das effiziente Verarbeiten von real-time Daten finde ich sehr spannend und relevant, die Usecases scheinen mir vielseitig. Die Docs sind gut geschrieben und die Community hinter Materialize ist sehr hilfreich, sodass sogar McSherry selbst eine meiner Fragen im Slack-Channel beantwortet hat. Die neue Cloud-Native Version von Materialize scheint ein weiterer Schritt in die richtige Richtung zu sein und ich freue mich darauf, Materialize in der kommenden Zeit weiter zu verfolgen. Bleib dran! 🚀