Apache Kafka ist der erste Teil unserer Blogreihe “Event-Driven Systems”. Dabei legen wir zunächst einmal den Grundstein für das weitere Thema, damit Sie genau wissen, was Ihnen die Verwendung von Kafka bringt.
Kafka wurde ursprünglich von LinkedIn entwickelt, bevor es 2012 Teil der Apache Software Foundation wurde. Dabei handelt es sich um ein Open-Source-Projekt, welches jedoch seit 2014 von dem Unternehmen Confluent entwickelt wird. Dieses Unternehmen entstand aus LinkedIn heraus.
Was ist Kafka?
Apache beschreibt Kafka selbst als eine Event-Streaming Platform, die mit dem menschlichen Nervensystem vergleichbar ist. Da es vor allem überall verwendet werden sollte, wo ein Service durchgehend läuft. Dies geschieht vor allem dadurch, dass das Business immer von automatisierter Software geprägt wird. Mit Kafka ist es ihnen möglich Daten in Echtzeit aus verschiedenen Event-Quellen, wie Datenbanken, Mobile Devices, Cloud Services oder anderen Software-Applikationen zu lesen und verwalten. Deswegen ersparen Sie sich mehrere unterschiedliche Integrationen zwischen den unterschiedlichen Systemen zu schreiben, denn alle können hierfür auf Kafka zurückgreifen. Aus diesem Grund ist es Ihnen auch möglich ein dezentralisiertes und belastbares System zu erstellen.
Welche Möglichkeiten ergeben sich durch die Verwendung von Kafka?
Mit Kafka ist es Ihnen möglich, Microservices und andere Applikationen zu erstellen, welche die Möglichkeit bieten, Daten mit einem extrem hohen Durchsatz, sowie einer sehr geringen Latenzzeit auszutauschen. Des Weiteren ist Kafka in der Lage, die Messages geordnet abzuspeichern und sogar anhand der gesammelten Messages einen bereits eingetretenen Applikationsstatus wieder nachzustellen. Durch die Verwendung von Clustern lässt sich Kafka sehr gut horizontal skalieren. Dies bedeutet, dass sich beispielsweise die Anzahl der Broker ohne Weiteres vergrössern können. Und obwohl hier schnell sehr grosse Datenmenge gespeichert werden (können), hat dies kein Einfluss auf die Geschwindigkeit von Kafka.
Ebenfalls lässt sich Kafka in unterschiedlichsten Bereichen verwenden. Dazu gehören:
- Event-driven Architekturen
- Event-Logging
- Tracken von Webseiten Aktivitäten
- Überwachung des Betriebs von Applikationen durch verschiedene Metriken
- Aggregation & Sammlung von Logs
- Verwalten von Protokollen über verteilte Systeme
Kafka Konzept
Falls Sie Kafka verwenden wollen ist es immer von Vorteil die wichtigsten Begriffe und die dazugehörige Funktion zu kennen.
Dabei fängt das Grundgerüst mit dem Kafka-Cluster an. Dieses beinhaltet verschiedene Broker Instanzen.
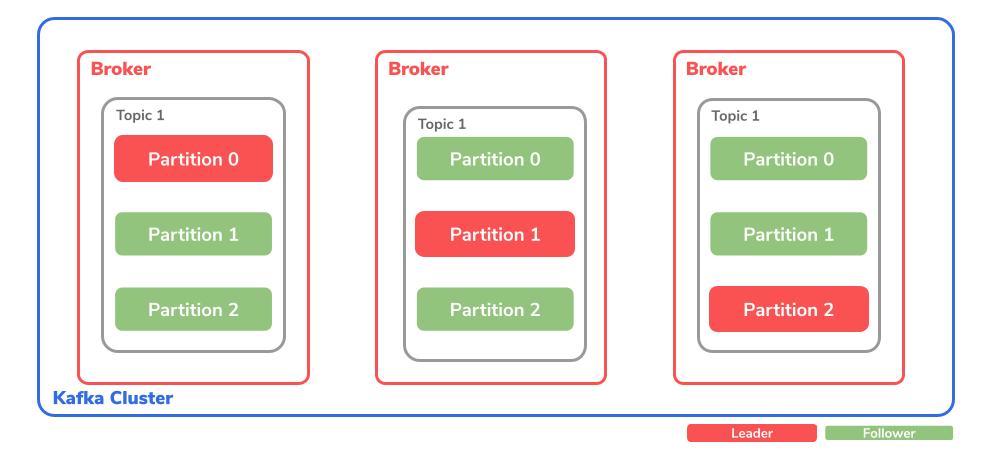
Broker
Der Broker ist dabei für die Koordination des Speichervorgangs sowie das Weiterleiten der Daten zuständig. Dabei wird ein Broker oft auch als Server oder Node bezeichnet.
Topic
Innerhalb des Brokers befindet sich das sogenannte Topic, welches Daten empfängt und innerhalb eines Kafka Clusters speichert. Dabei wird dieses in eine selbst konfigurierte Anzahl von Partitionen unterteilt.
Partitionen
Dies ist der eigentliche Ort, an dem die Messages gespeichert werden. Zudem ist es möglich, die Partitionen über mehrere Topics zu replizieren, um einen Datenverlust zu vermeiden. Wie bereits erwähnt, wird die Anzahl an Partitionen über den topic partition count selbst definiert.
Bei den Partitionen wird zusätzlich zwischen Leader und Follower unterschieden. Der Partition Leader ist für die Verarbeitung aller Producer Requests eines Topics zuständig. Der Partition Follower dagegen repliziert die Daten des Leaders. Auch dies kann über den replication factor selbst bestimmt werden. Optional ist es auch noch möglich, dass der Follower Consumer Requests verarbeiten kann.
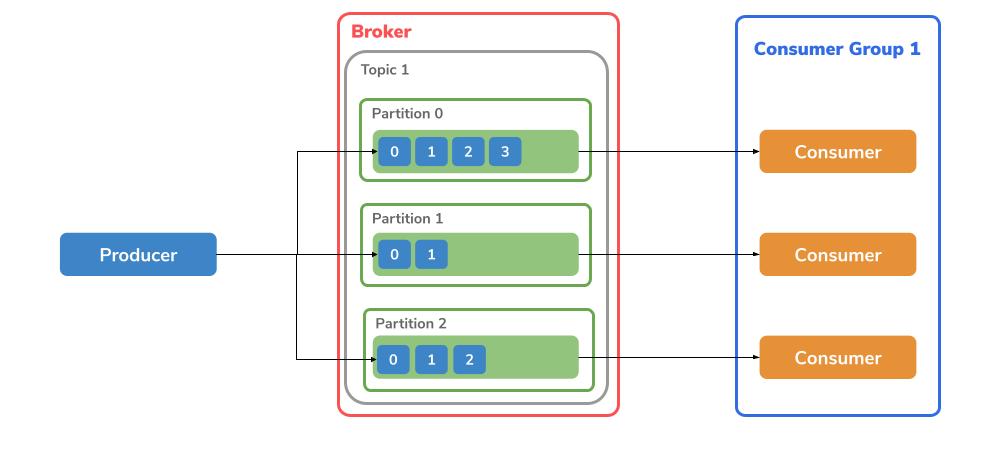
Damit Kafka auch Daten hat, braucht es jemand der Daten sendet und einer der Daten liest.
Messages
Bei Messages handelt es sich um eine fachliche Transfereinheit, die Kafka verwaltet. Dabei bestehen diese Messages aus folgenden Punkten:
- Timestamp: kann selbst durch den Producer gesetzt werden oder automatisch durch den Broker
- Key: identifiziert die Ziel Partition
- Value: durch den Producer definierten Payload
- Header: enthält weitere Key-Value Paare
Offset
Das Offset bestimmt die Position einer Message innerhalb einer Partition. Dabei hat jede Message ein eindeutiges Offset. Deswegen kann überwacht werden, an welcher Position sich der Consumer befindet und wie viele Einträge bisher gelesen wurden.
Producer
Der Producer ist für den publish-Vorgang zuständig. Dies bedeutet er sendet Messages zu einem Broker Topic. Dabei wird die gesendete Nachricht immer nach dem letzten Offset einer Partition geschrieben. Wenn es mehrere Partitionen innerhalb eines Topics gibt, findet entweder das Round-Robin-Prinzip Anwendung oder anhand des Keys wird entschieden, in welches Topic geschrieben werden soll.
Consumer
Wo Nachrichten gespeichert werden, muss es auch die Möglichkeit bestehen, die Daten zu lesen. Dies geschieht durch einen subscribe-Vorgang. Das bedeutet ein Consumer ‘abonniert’ ein Topic aus dem er anhand der Partition und des Offsets die Nachrichten lesen kann.
Consumer Group
Consumer können mithilfe einer group.id in Gruppen unterteilt werden. Dabei können jedoch zwei Consumer nicht aus derselben Topic-Partition lesen. Dafür ist es jedoch möglich, dass ein Consumer aus mehreren Partitionen liest. Diese werden genutzt, um grosse Data-Streams zu teilen, welche durch mehrere Producers generiert werden.
Architektur
Nachdem wir uns nun die Grundlagen des Kafka Clusters angeschaut haben, geht es nun mit den nächsten Teilen weiter, welche Kafka vervollständigen.
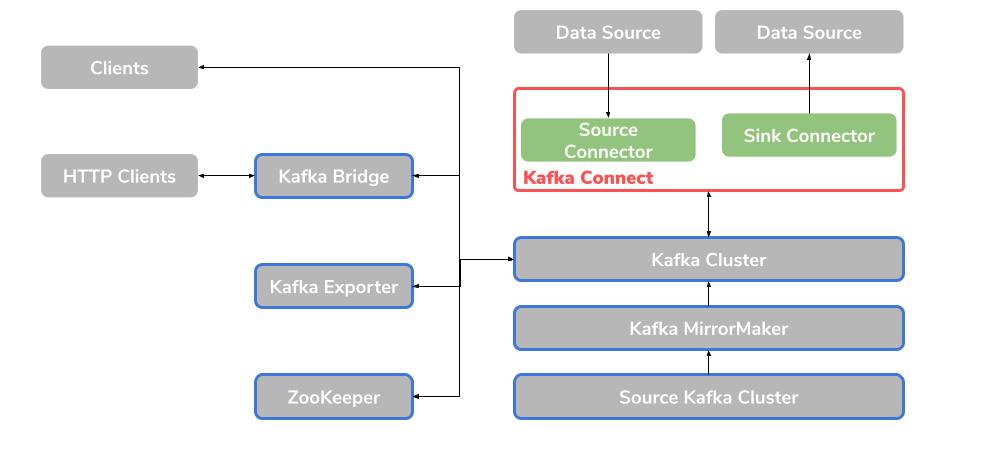
Apache ZooKeeper
Bei ZooKeeper handelt es sich um eine Core-Dependency, welches selbst von Apache ist. Dabei handelt es sich um ein Cluster, welches replizierte ZooKeeper-Instanzen enthält. Als ein Koordinationsservice ist ZooKeeper dafür zuständig, den Status von Brokern und Consumer zu tracken und aber auch zu speichern. Ebenfalls kümmert es sich um die Leader Election der verschiedenen Partitionen.
Kafka Connect
Damit Sie Daten zwischen Kafka-Brokern und anderen Systemen austauschen können, bietet Apache hier ein Integrations Toolkit an. Dies können Sie mithilfe von sogenannten Connector-Plugins umsetzen. Dabei stellt Kafka Connect ein Framework zur Verfügung, damit Sie Kafka in externen Datenquellen wie beispielsweise in Datenbanken integrieren können. Dabei ist der Vorteil, dass externe Daten direkt in das passende Format übersetzt und transformiert werden.
Dabei gibt es den Source Connector, welcher externe Daten zu Kafka sendet. Und ebenso gibt es den Sink Connector, welcher Daten aus Kafka heraus extrahiert.
Kafka MirrorMaker
Der MirrorMaker ist verantwortlich, dass die Daten zwischen zwei Kafka-Clustern repliziert werden. Dabei wird zwischen einem Source-Kafka Cluster und einem Target-Kafka Cluster unterschieden.
Kafka Exporter
Dies ermöglicht Ihnen Daten als Prometheus Metriken zu Analyse zwecken zu extrahieren. Dazu gehören Informationen zu Offsets, Consumer-Gruppen und Consumer-Lags. Bei Letzterem handelt es sich um die Verzögerungszeit zwischen der letzten Nachricht innerhalb einer Partition und der Nachricht, die gerade von einem Consumer von dieser Partition abgeholt wird.
Kafka Bridge
Die Kafka Bridge bietet eine API zur Integration von HTTP-basierten Clients in ein Kafka Cluster.
Kafka Bridge Interface
Über die Bridge wird ein RESTful-Interface angeboten damit HTTP basierende Clients mit Kafka kommunizieren können. Dies erspart den Clients das Kafka Protocol übersetzen zu müssen. Dabei gibt es durch die API zwei Hauptresourcen, Consumers & Topics. Diese werden von ‘aussen’ über Endpunkte zugänglich gemacht, damit mit den Consumern und Producers innerhalb des Kafka Clusters kommuniziert werden kann.
HTTP Requests
Dabei werden die folgenden Request zur Verfügung gestellt:
- Nachrichten in ein Topic senden
- Nachrichten von einem Top erhalten
- Erhalten einer Liste von Partitionen von einem Topic
- Erstellen & löschen von Consumern
- Abonnieren von Topics, um davon Nachrichten zu empfangen
- Erhalten einer Liste von Topics, die ein Consumer abonniert
- Abmelden von Topics
- Partitionen einem Consumer zuweisen
Dabei können die Nachrichten entweder im JSON-Format oder im Binary-Format gesendet werden. Dadurch können Clients Nachrichten erstellen und lesen, produce & consume, ohne das Kafka-Protokoll verwenden zu müssen.
Stay tuned!