
Für dieses TechUp habe ich mir Weaviate, eine Open-Source Vektordatenbank, genauer angeschaut und damit Hands-On ein Blogpost-Empfehlungssystem für unseren TechHub gebaut.
Was ist eine Vektordatenbank?
In einer Vektordatenbank werden neben traditionellen Datenformen (Strings, Integers etc.) auch Vektoren gespeichert. Diese Vektoren sind Repräsentationen der in der Datenbank gespeicherten Informationen, die von Computern besser verstanden werden können.
Haben wir beispielsweise eine Sammlung von Sätzen, die wir speichern möchten, könnten wir für jeden Satz einen mehrdimensionalen Vektor erstellen, der den Satz repräsentiert. Dabei steht jede Dimension dieses Vektors für ein anderes Merkmal des Satzes, vereinfacht gesagt z.B. die Häufigkeit zu der ein Wort im Satz vorkommt, welches einer bestimmten Kategorie wie “Essen” zugeordnet werden kann. Ein solcher Vektor nennt sich Embedding, dazu gleich mehr.
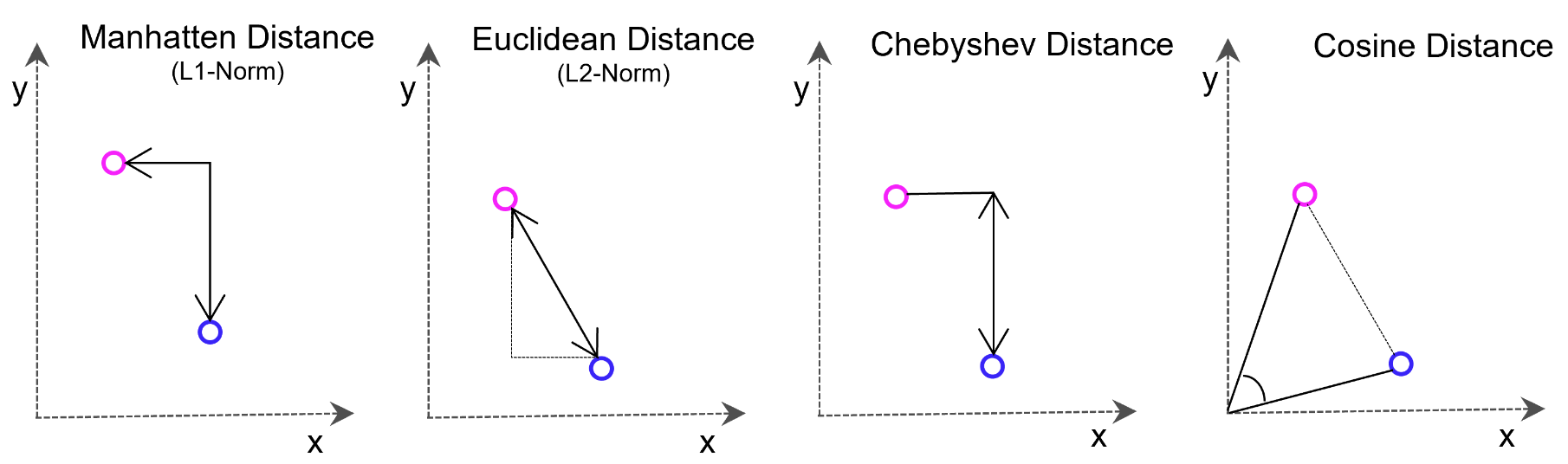
Aber was kann man mit so einem Vektor denn überhaupt machen? Die Idee ist, dass Vektoren, die z.B. Sätze mit verwandten Inhalten repräsentieren, im Vektorraum näher beieinander stehen. Diese Abstände lassen sich auch mit hochdimensionalen Vektoren dank effizienter mathematischer Methoden sehr schnell bestimmen, was Vektordatenbanken attraktiv für Suchfunktionen und Deep Learning macht.
Weaviate verwendet hier per Default die Cosinus-Distanzmessung, welche einfach nur den Winkel zwischen zwei Vektoren berechnet.
TLDR
Der Hauptvorteil einer Vektordatenbank besteht darin, dass sie eine schnelle und präzise Ähnlichkeitssuche und Datenabfrage ermöglicht, basierend auf dem Vektorabstand bzw. der Ähnlichkeit zwischen einzelnen Datenelementen. Das bedeutet, dass anstelle von traditionellen Methoden zur Abfrage von Datenbanken auf der Grundlage exakter Übereinstimmungen oder vordefinierter Kriterien, eine Vektordatenbank verwendet werden kann, um die ähnlichsten / relevantesten Daten basierend auf ihrer semantischen oder kontextuellen Bedeutung zu finden.
Was ist ein Text-Embedding und wie wird es generiert?
Text-Embeddings sind Vektoren, die durch die Projektion eines Textes (Semantischer Raum) auf einen Vektorraum (Zahlenraum) entstehen. Dabei geht es darum, die Merkmale eines gegebenen Textes zu kondensieren und in einen Vektor abzubilden. Solche Embeddings werden mithilfe von Machine Learning-Modellen generiert, die auf großen Mengen von Textdaten trainiert wurden. Es gibt verschiedene Techniken zur Erzeugung von Text Embeddings, aber eine der häufigsten und effektivsten Methoden ist die Verwendung von sogenannten “Word Embedding-” oder “Sentence Embedding-“Modellen. Hier erkläre ich, was jeweils dahinter steckt:
- Word Embeddings
- Word Embeddings sind Zahlenvektoren, die jedem Wort in einem Textkorpus eine eindeutige Darstellung zuordnen.
- Ein häufig verwendetes Verfahren zur Erzeugung von Word Embeddings ist Word2Vec. Es verwendet ein neuronales Netz, um die Vektorrepräsentationen für Wörter zu lernen. Word2Vec nutzt den Kontext der Wörter, indem es benachbarte Wörter in einem Satz oder Dokument analysiert. Dadurch werden ähnliche Wörter in einem ähnlichen numerischen Raum eingebettet.
- Ein weiteres beliebtes Modell ist GloVe (Global Vectors for Word Representation). Es nutzt statistische Informationen aus der globalen Textstatistik, um semantische Beziehungen zwischen Wörtern zu erfassen.
- Sentence Embeddings
- Sentence Embeddings sind ähnlich wie Word Embeddings, jedoch werden hier komplette Sätze oder Paragraphen in Zahlenvektoren umgewandelt.
- Ein häufig verwendetes Modell zur Erzeugung von Sentence Embeddings ist das “Encoder-Decoder-Modell”, insbesondere das Bidirektionale Encoder-Decoder-Modell (z. B. LSTM oder GRU). Es lernt, eine variable Anzahl von Wörtern in einen Vektor zu codieren, der die Bedeutung des Satzes enthält.
- Transformer-Modelle, wie der bekannte “BERT” (Bidirectional Encoder Representations from Transformers), sind ebenfalls sehr effektiv bei der Erzeugung von Sentence Embeddings. Diese Modelle verwenden Aufmerksamkeitsmechanismen, um kontextbezogene Embeddings zu erzeugen.
Einfache Beispielarchitektur
!—
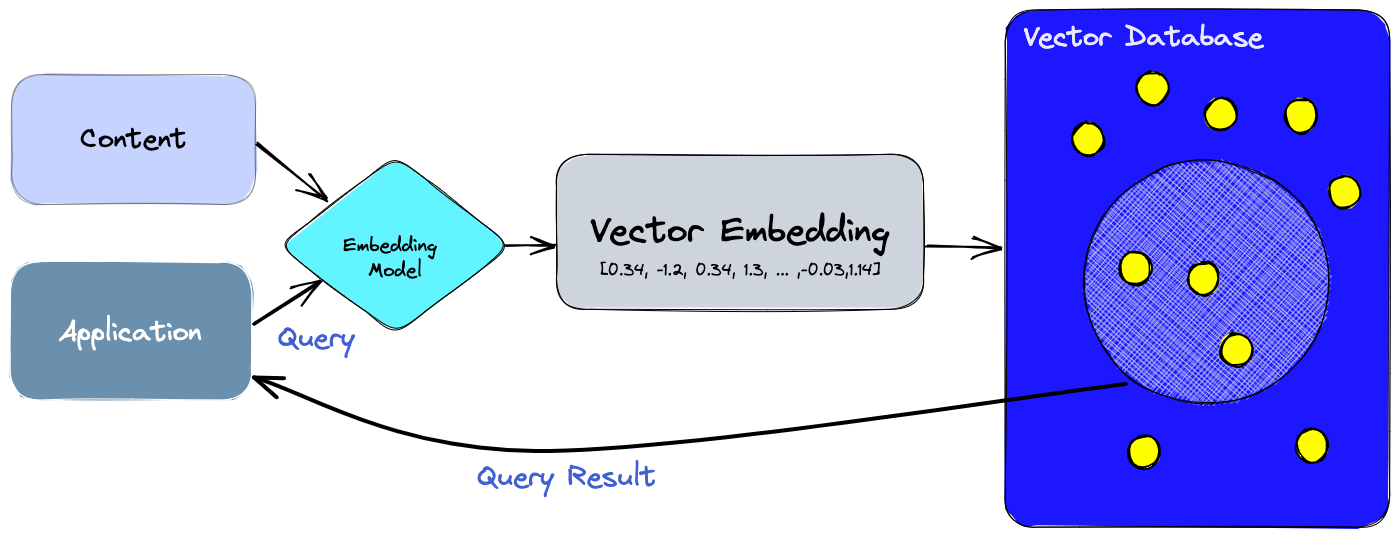 !—
Figure: Source: sanity.io
!—
Figure: Source: sanity.io
Daten einspeisen
Wenn Daten in die Datenbank eingespeist werden, wandern diese erst durch das Embedding-Modell, welches eine Vektorrepresentation der Daten zurückgibt. Die Originaldaten werden dann zusammen mit dem entsprechenden Vektor in die Datenbank gespeichert.
Daten abfragen
Daten können auf verschiedenste Weise abgefragt werden. Neben exakten Matches anhand von fixen Eingabeparametern, wie in traditionellen Datenbanken üblich, gibt es hier auch die Möglichkeit, einen beliebigen Text einzugeben, aus dem ebenfalls via Embedding Model ein Vektor erstellt und mit den anderen Einträgen verglichen wird (Semantische Suche). Von diesem Vektor aus lässt sich dann die Distanz zu anderen naheliegenden Vektoren bestimmen, und die Ergebnisse an die Applikation zurückgegeben werden.
Wie lässt sich Weaviate nutzen?
- Weaviate Cloud Services: Ein SaaS angebot, praktisch für Entwicklung und produktiven Einsatz.
- Docker Compose: Praktisch für lokale Entwicklung.
- Kubernetes: Typischerweise für den produktiven Einsatz verwendet.
- Embedded Weaviate: Experimentelles Feature.
Hands-On Blogpost Recommendation mit Weaviate
Um Weaviate besser kennenzulernen, hatte ich einfach mal das Getting started angefangen, erkannte aber recht schnell das Potenzial, damit etwas umzusetzen, was ich schon länger auf dem Schirm hatte: TechUp-Empfehlungen, und zwar nicht nur auf Tags des aktuellen TechUps basierend, sondern intelligent und verspielt, idealerweise basierend auf dem gesamten Text.
Da das hier verwendete Embeddings-Modell von HuggingFace nur maximal 256 Wörter akzeptiert und auf einzelne Sätze trainiert wurde, liefern wir hier für das erstellen der Vektoren nicht den ganzen Text mit, sondern nur titel, tags, url, description.
Setup
Für das lokale Setup bin ich vorgegangen wie im Quickstart von Weaviate. In diesem Tutorial nutze ich Python 3.11 in einem Jupyter Notebook. Als erstes müssen wir den Weaviate Client installieren.
|
|
Nun können wir eine kostenfreie Sandbox Instanz von Weaviate erstellen, deren API Schlüssel sowie die URL holen und uns mit der Instanz verbinden. Wir importieren hier zusätzlich noch eine Bibliothek requests für HTTP Requests, die wir später brauchen.
|
|
Daten importieren
Nun kreieren wir eine Klasse namens Techup, die unsere Daten beherbergen wird.
|
|
In diesem Fall verwenden wir für die Erstellung der Embeddings dieses Modell von HuggingFace: sentence-transformers/all-MiniLM-L6-v2.
Holen wir uns als nächstes Daten, die wir nutzen wollen. In diesem Fall ist das Ziel, basierend auf einem gegebenen Blogpost, andere Blogposts zu empfehlen.
|
|
Schauen wir einen dieser Blogposts mit print(data[2]) an, erhalten wir beispielsweise:
|
|
Wir haben unsere Daten also in data gespeichert. Für jedes TechUp möchten wir jetzt title, tags, url und description in unsere Weaviate Instanz ins Techup-Objekt importieren und führen dazu folgenden Code in unserem Jupyter Notebook aus:
|
|
Wir sehen, wie der Import bestenfalls erfolgreich durchläuft. Lass uns jetzt eine Datenbankabfrage auf Weaviate absetzen.
Semantische Suche
Die semantische Suche erlaubt es uns, in Weaviate nach Einträgen zu suchen, die etwas mit dem Eingabetext zu tun haben, aber nicht zwingend genau den gegebenen Text 1:1 enthalten.
Wir definieren mit .get() das Objekt Techup, aus dem wir jeweils nur die url jedes Blogbeitrages herauskriegen möchten. Mit .with_near_text() definieren wir unsere Suchanfrage "Serverless", zu der wir die entsprechend passendsten Blogbeiträge erhalten wollen (kann statt einem Wort auch ein Satz oder mehr sein). Wie bereits angeschaut, wird diese Suchanfrage erst zu einem Embedding (Vektor) verarbeitet und dann wird die Vektordistanz zwischen diesem und allen anderen Vektoren berechnet. .with_limit() ist die Anzahl Ergebnisse, die wir zurück erhalten wollen und mit .with_additional() stellen wir ein, dass wir zusätzlich die Vektordistanz jedes Eintrages relativ zum Vektor zur Suchabfrage “Serverless” und die ID zurück erhalten wollen. Das ganze sieht dann so aus:
|
|
Und wir kriegen diese Response zurück, wenn wir print(json.dumps(response, indent=2)) ausführen.
|
|
Blog-Empfehlungen
Nun möchte ich anhand einer gegebenen Blogpost-URL fünf passende Blogbeiträge erhalten. Dazu habe ich folgende zwei Methoden definiert:
|
|
Um die Objekt-ID eines Blogposts zu erhalten, habe ich in getID() einen Filter definiert, der genau die Einträge in Weaviate sucht, die dieselbe ID enthalten. Dies ist ein kleiner Workaround, da es auch die Möglichkeit gäbe, jedem Objekt beim senden an Weaviate eine ID zu assignen, und wir dann direkt das Objekt aufrufen könnten, ohne den Code in getID().
Nun können wir getRecommendations() mit der URL eines unserer Blogposts und der Anzahl Ergebnisse, die wir zurück erhalten wollen, aufrufen:
|
|
|
|
Es funktioniert! 🤩
Visualisierung der Daten
Die hochdimensionalen Vektoren, die jedem Objekt unserer Datenbank zugeordnet sind, lassen sich unter anderem auch auf die zweidimensionale Ebene Projezieren. Das erlaubt uns, die Beziehung zwischen unseren Datenbankeinträgen anschaulich darzustellen.
Die dazu benötigten Daten holen wir aus unserer Weaviate raus, indem wir die Argumente featureProjection und dimensions mitgeben:
|
|
Nun kriegen wir für jeden Blogpost einen 2D-Vektor in der Json-Response zurück, beispielsweise: {'featureProjection': {'vector': [81.65559, -31.689371]}}, 'title': 'Steigere deine Produktivität mit Alfred'}.
Um das zu visualisieren, habe ich mir mit ChatGPT 3.5 etwas Code generieren lassen, der uns eine anschauliche Grafik zurückliefert:
|
|
Fazit
Alles in Allem hat mich Weaviate positiv überrascht. Der Fokus auf Developer Experience macht sich bemerkbar, denn schon während ich das Getting Started durcharbeitete, bekam ich Lust darauf, direkt mehr damit zu machen. Die Vorteile von Vektordatenbanken zu nutzen ist dank Anbietern wie Weaviate extrem einfach geworden - es gibt natürlich auch andere Player auf dem Markt, die man sich vor einer Entscheidung ebenfalls genauer anschauen sollte, aber Weaviate ist dadurch, dass es OpenSource ist, schon sehr attraktiv.
Nun habe ich unserer eigens gebauten Recommendation Engine einmal den Titel dieses Blogposts gefüttert und empfehle dir somit diese folgenden TechUps zum weiterlesen (Wir haben nur ein weiteres TechUp zu Databases daher hier keine grosse Korrelation):
Probier’s aus und bleib dran! 🚀