
What is Serverless?
Now that we have already enjoyed a TechUp about serverless, let’s take a step back and look at the whole topic in more detail in theory.

Figure: Source: https://www.reddit.com/r/ProgrammerHumor/comments/ki1uoh/the_room_full_of_serverless/
Opinions are divided on the subject of serverless. Questions such as “Do we still have servers at all?” and “Isn’t that much too expensive?” can inspire hours of discussion.
But what exactly is serverless and how is it defined? Let’s ask ChatGPT: “What is serverless in three sentences?”:
Serverless refers to a method of software development and deployment where the developer does not have to worry about managing or deploying servers. Instead, applications run in the cloud and the infrastructure is automatically provisioned and managed by a cloud provider. The applications are divided into smaller, independent functions that are only executed when they are needed.
Serverless thus describes an architectural pattern, similar to containerisation or container orchestration, with which computing can take place in the cloud environment. Serverless is to be understood as the “highest” level of abstraction, i.e. one is furthest away from the actual server or the physical layer.
A short excursion into the kitchen:
You surely remember my TechUp about Micro in the Frontend, there we got to know the ravioli era, i.e. the microservice idea, in more detail. The picture shows the evolution in software architecture. While preparing this TechUp, I often had the thought: What will actually come after Ravioli? Of course, serverless, but how is that associated?
I’m sure serverless is when you order food from a delivery service. Ideally, you order a lot of small different items and then try to combine them, which can quickly become expensive depending on your hunger and preferences. But the important thing is that you don’t have to worry about the oven, flour or anything like that. You effectively only pay when you get something delivered and then eat it ;-)
Back to the topic: people often associate serverless with “there is no server”, but that is a misconception. Far below, far outside one’s own area of responsibility, usually with a cloud provider, is the actual server. It is simply abstracted to such an extent that one speaks of “serverless”.
Characteristics of a serverless architecture
When does my application or my business domain become serverless, which characteristics must be fulfilled?
- abstraction from servers: In a serverless architecture, developers do not have to worry about provisioning, configuring or managing servers (keyword FaaS, more on this later).
- automatic scaling: serverless functions are automatically scaled to handle peak loads without developers having to intervene manually. Scaling down also occurs, up to and including shutdown.
- billing by usage: serverless platforms only charge for the resources actually used and not for the resources allocated (keyword PAYG, more on this later).
- event-driven execution: serverless functions are only executed when certain events or requirements occur, rather than being active all the time.
If an architecture meets these characteristics, it can be considered serverless.
Differentiation from cloud provider native.
Often the discussion comes up: Is this now cloud-provider-native, such as AWS ECS or similar, or is this already serverless, such as AWS Amplify Serverless platforms such as AWS Amplify and AWS Lambda are specifically designed to deliver functions as a service (FaaS) and offer a highly abstracted and managed infrastructure. With serverless platforms, developers do not have to worry about managing servers, networks or the underlying application stack, as these are automatically provisioned and scaled by the platform.
In contrast, native cloud provider services such as Amazon Elastic Kubernetes Service (EKS) or Amazon Elastic Container Service (ECS) offer greater control and flexibility in managing containers or the underlying application stack. Here, it is necessary for developers to take care of the management and provisioning of servers and networks themselves, which creates more configuration and maintenance work.
While serverless platforms are typically used for smaller, task-oriented applications that can be developed quickly and in an agile manner, native cloud provider services are better suited for larger, complex applications that have specific scalability, performance or customisability requirements.
What is FaaS & PAYG?
FaaS - Function as a Service
After IaaS comes CaaS, then PaaS and finally comes FaaS, logical right?
Figure: FaaS Meme, generated with https://imgflip.com/memegenerator
FaaS stands for “Function as a Service” and refers to a serverless architecture in which applications are divided into small, independent functions that can be executed separately. Each function is executed only when needed and can be scaled automatically. FaaS allows developers to focus on developing code rather than worrying about infrastructure, enabling faster and more agile development cycles.
Quick reiteration: cloud is actually quite simple ;-)
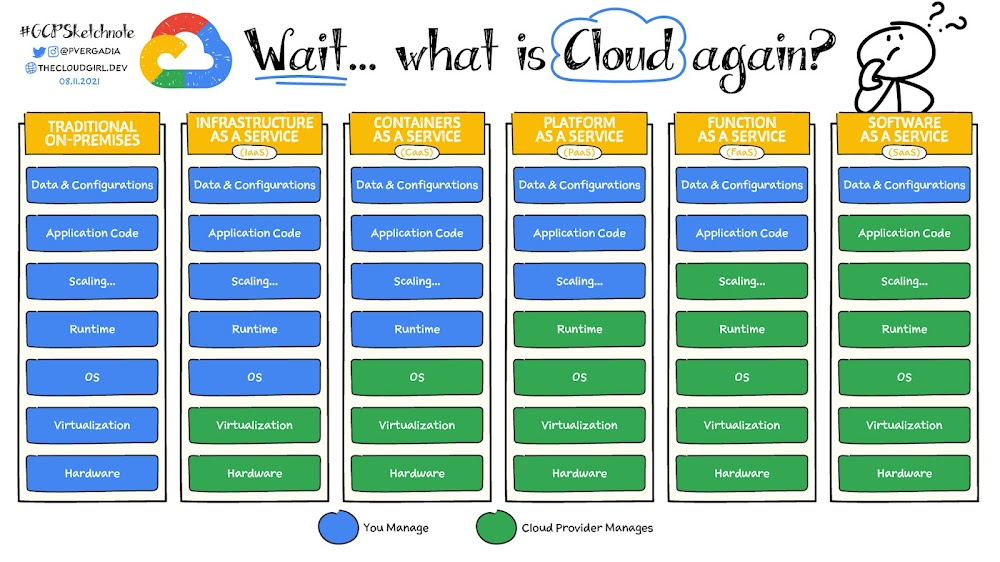
Figure: Source: https://cloud.google.com/learn/paas-vs-iaas-vs-saas?hl=de
It is important to see, however, that FaaS is the last stage before SaaS, i.e. quasi serverless as a service. In concrete terms, one only takes care of the actual code and configuration; everything else is provided and managed by the cloud provider.
PAYG
The so-called Pay as you go model is a billing model in which customers only pay for the services they actually use. In contrast to traditional contract models, PAYG offers greater flexibility and scalability, as billing is based on actual demand. Especially for smaller tasks, CronJobs or similar, this concept often makes sense in interaction with FaaS. Basically, the PAYG concept is often used in the serverless sector in order to be able to offer fast scaling (also of the costs). A big risk with PAYG can be rampant costs due to misconfiguration, DDoS attacks or similar. Appropriate limits and protective mechanisms should always be configured and active!
Serverless Use Cases
Setting up a serverless architecture should be well thought out and planned for a long time! Usually you have to start from scratch, as the complete architecture requires a rethink. In contrast to containerisation, there are hardly any “low hanging fruits” to quickly make an application serverless.
Serverless always makes sense for:
-
Task-based applications: Serverless is ideal for application-independent functions that perform specific tasks, such as image processing, data processing and notifications. An example of this is an application that converts images to different sizes and uploads them to cloud storage.
-
Event-based architectures: Serverless is ideal for applications that are based on events or user input, such as notifications and real-time data processing. An example is an application that sends user notifications based on data from multiple sources.
-
Scalable applications: Serverless provides seamless scalability, allowing applications to automatically and quickly respond to heavy loads. An example of this is an e-commerce application that needs to scale quickly during the Christmas shopping season to handle increased traffic.
-
Cost-effective applications: Serverless can be more cost-effective than traditional server-based architectures, especially for applications with variable workloads. An example of this is an application that is able to use resources only when they are needed.
-
Experimental applications: Serverless provides an ideal environment for experimental applications or prototypes, as they can be created quickly and easily without the need to set up extensive infrastructure. An example of this is an application that integrates different APIs and automatically reacts to events.
-
Microservices architectures: Serverless is ideal for applications that are divided into microservices, as each function can be scaled independently. An example of this is an application that consists of multiple microservices, each performing a specific function and communicating via an API.
Classic example
The following image shows a classic example of a web application as a serverless architecture. Here, a link is clicked on a web page, which retrieves data from a database and displays it back to the user.
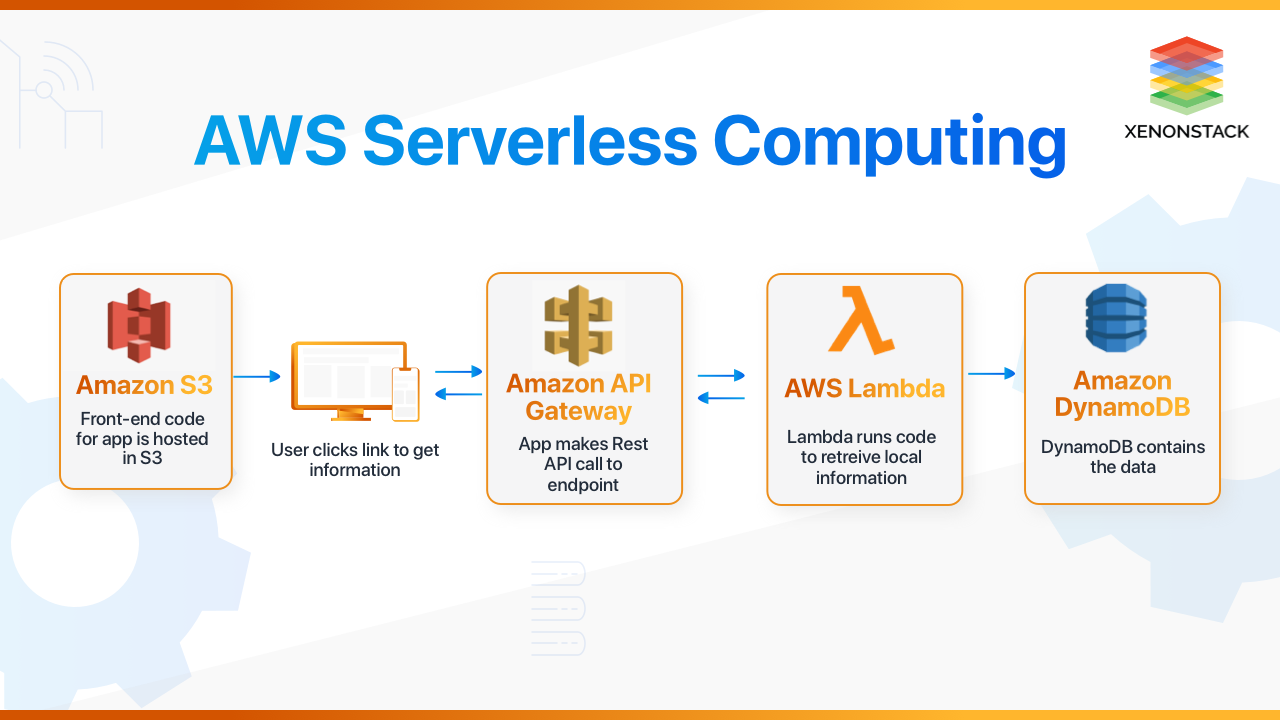
Figure: Source: https://www.xenonstack.com/blog/aws-serverless-computing/
This entire example works without a “server”, i.e. nowhere are resources such as CPU, RAM or similar permanently allocated and started, PAYG is fully used, as all components are serverless or FaaS components. It should be noted that the database is also serverless. It is not run on a server, but offered as a service by AWS. Serverless is therefore not only an architecture of a single application, but also a concept that affects all areas.
When does serverless not make sense?
In some cases, it doesn’t really make sense to rely on the Serverless pattern, but rather on “classic” container orchestration. These include:
- Very constant load - if the application is consistently busy, the benefits of a Serverless transition may be less.
- Long-running functions - for example, an AWS Lambda function has a maximum execution time of 5 minutes. So if you have very long running functions, using serverless (function chaining) could become a bit cumbersome
- Not supported environment / language etc.
- Cost reasons can also be a clear no to the serverless approach.
At this point I would like to emphasise that this does not mean that the old monolith should just stand still! There are always possibilities to modernise and optimise an application using containerisation with microservices and the like, even if serverless is not the right solution in this case.
Requirements
Going serverless is not just a “lift & shift”! The application, even the entire business domain, must be fully designed for the Serverless pattern. Therefore, there are different requirements:
- stateless function design: functions should be independent of each other and have no dependencies on other functions or resources.
- event-driven architecture: the application should react to events and be able to orchestrate the processing of events and start the corresponding functions.
- scalability: the application should be able to adapt to user requirements and allow easy scaling.
- modularity: the application should be modular and divided into small, independent functions to allow each function to be scaled and managed separately.
- Lightweight: Fast start-up and shutdown times, small resource consumption.
- Standardised: Use of modern technologies that are fully supported.
- cloud-native design: the application should be based on cloud-native technologies and run in the cloud environment.
Advantages & disadvantages of serverless
Advantages
- Scalability and automatic resource management
- Lower costs and payment only for resources actually used (PAYG)
- Reduced time for infrastructure management and maintenance
- Focus on application development instead of server management
- Full focus on the actual task, event-based
Disadvantages
- Constraints on runtime environment and underlying infrastructure
- Limitations in the size of executable functions and storage capacity
- Complexity in integrating applications and dependencies
- Difficulties in debugging and testing functions
- Possible vendor lock-in effects and limited portability
- Security, no possibility for hardening, etc.
- And again, as the following picture shows, complexity due to many individual, small parts.
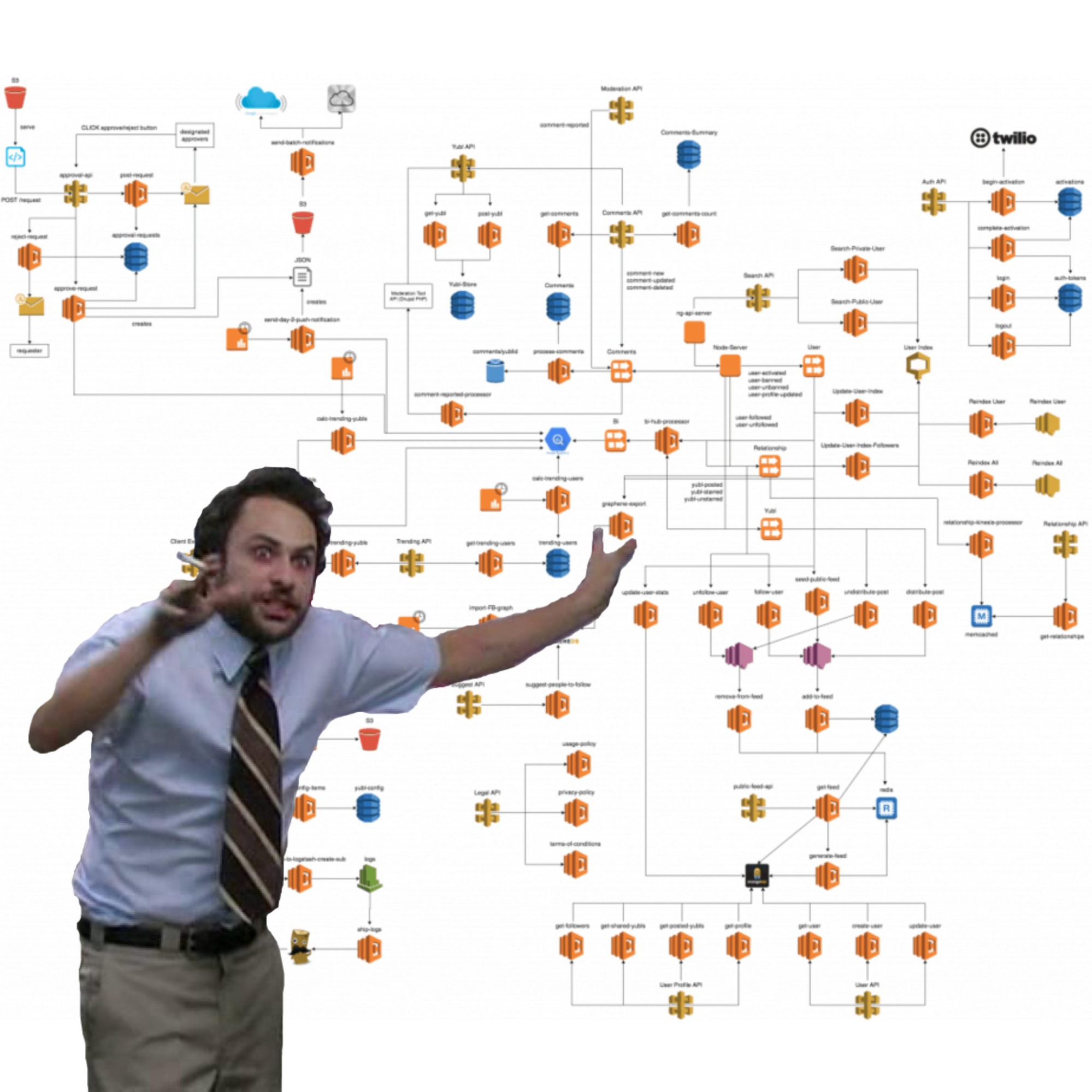
Figure: Source: https://docs.momentohq.com/develop/tutorials/serverless-cache-walkthrough/deploying-a-basic-serverless-application
CNCF landscape
There is a serverless landscape, which was created by the CNCF (Cloud Native Computing Foundation). This landscape shows the different serverless technologies and their strengths and weaknesses.
What comes after Serverless?
Serverless is currently one of the most advanced architectural approaches to create scalable, flexible and cost-effective applications. However, it is important to note that technology and innovation in the IT industry are constantly advancing and there is always room for improvement. Some experts in the industry believe that Functions as a Service (FaaS) could be the next stage of development after Serverless. FaaS builds on the Serverless architecture and offers even finer granularity by splitting function calls into smaller units and offering the ability to execute functions faster and with lower latency. There are also approaches such as Event-Driven Architecture (EDA), which focus on processing events to orchestrate and execute applications. EDA is particularly useful for applications that rely on real-time events, such as IoT applications.
However, it is difficult to say what will come in the future, as the IT industry is very dynamic and innovative. However, it is certain that there will always be new approaches and technologies to make applications more effective, efficient and scalable. What is certain: Serverless will continue to grow! And we at b-nova are part of it! This is also shown by the State of Serverless Report from DataDog, which shows the most important trends and developments in the serverless sector.
Conclusion
Should I use serverless? This is the central question! If you look at a decision tree, the answer is easy, isn’t it? ;-)
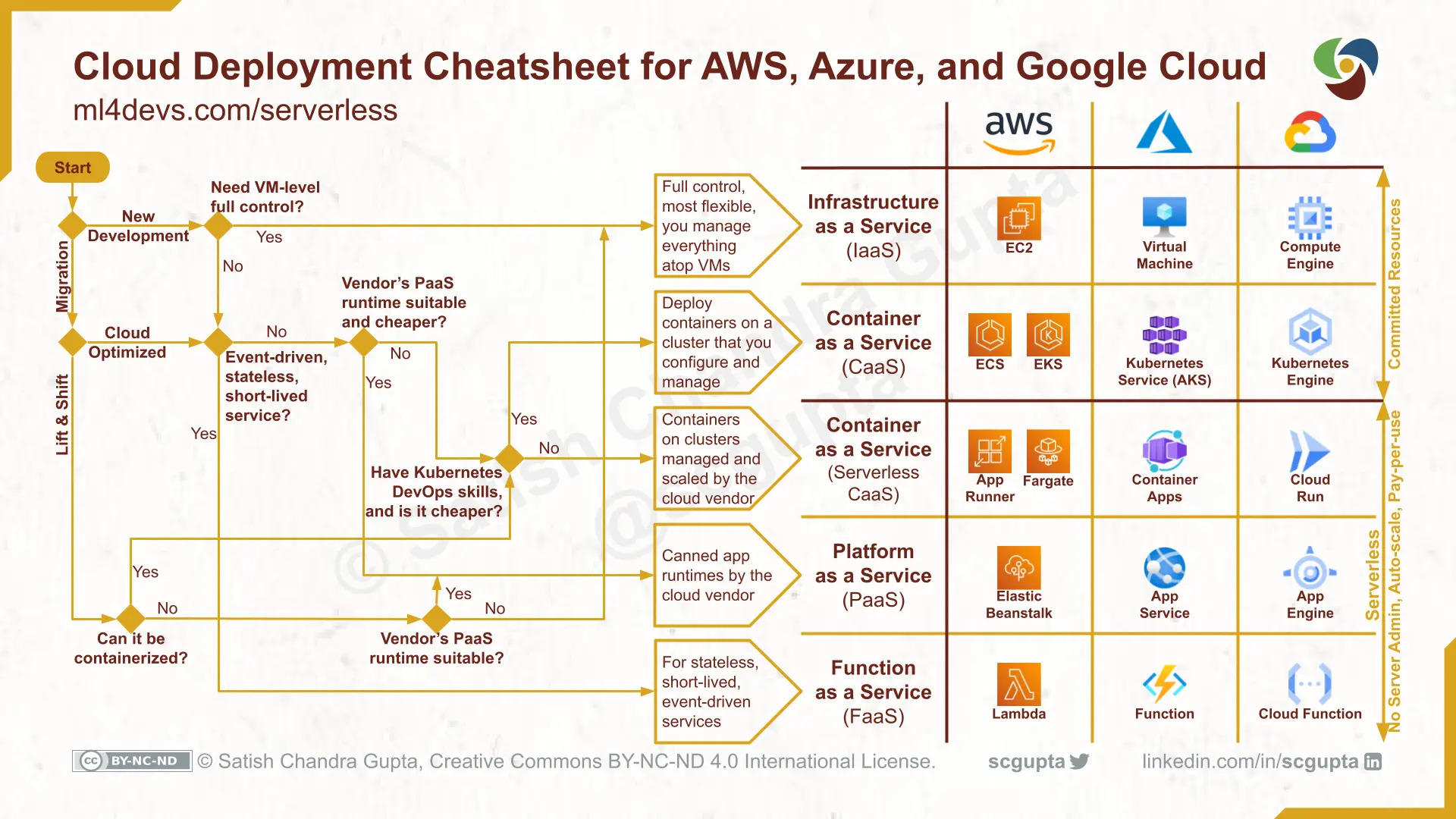
Figure: Source: https://www.ml4devs.com/articles/serverless-architecture-for-microservices-on-aws-vs-google-cloud-vs-azure-as-iaas-caas-paas-faas/
From my personal point of view, it definitely makes sense for new developments or outsourcing of individual parts! Smaller functions, websites with no permanent high load or CronJobs or similar are very easy and also cost-effective to operate with serverless, because PAYG. Simply migrating a large online shop to a serverless architecture overnight requires a bit more planning and ideally a new development “on the green field”.
We at b-nova remain fully convinced of serverless and stay on the topic! Look forward to more TechUp and decodify episodes! Stay tuned!
✨ This TechUp has been automatically translated by our markdown translator ✨