
Introduction
Our goal was to move the infrastructure behind our TechHub away from Magnolia CMS and towards Cloud Native. Essentially, this involved re-engineering, or redeveloping, the existing status quo from a conventional CMS-based architecture with Magnolia to a headless CMS architecture that implements the promising Jamstack pattern. Jamstack is a novel architectural pattern for content systems, built on three pillars: JavaScript, APIs, and Markdown. If you’d like to learn more, we have a dedicated TechUp where we take a closer look at the Jamstack pattern and explore the entire solution stack behind it.
This redevelopment towards a headless CMS allows us to automate and simplify the publishing process. Additionally, choosing a Jamstack-enabled architecture enables us to operate Git-based content management, where content is always stored as Markdown in a corresponding Git repository. This Markdown content can then be retrieved via Git by a variety of APIs and transformed into the desired format of a target platform. This also gives us the ability to quickly implement and test new features of our TechUp page, both on the frontend and backend. This means the time-to-market is significantly reduced, allowing us to manage our platforms more flexibly. To achieve this goal, we followed the proven GitOps pattern, which in turn enables lean CI/CD processes. A short time-to-market and lean CI/CD processes, i.e., pipelines, mean more agility, reduced operating costs, better visibility during debugging, and generally the feeling of being able to apply cutting-edge principles and patterns. Plus, we were able to learn a lot in the process. :)
Those were some tasty words. Let’s get a little more concrete here and show what this means for the tooling. Here’s a short and concise list of all the central aspects of the tooling stack:
- The migration of the TechUp page frontend to microfrontends using Angular on AWS Amplify.
- The development of various Golang microservices for the automated preparation of the target formats of all existing and new TechUps, plus the deployment of the containerized workloads of all these microservices on a Kubernetes cluster.
- The development of CI/CD processes using Github Actions (we already host our Git repositories on Github anyway) to review, process, and distribute new TechUps.
- The provisioning of Apache Solr instances and AWS S3 buckets as additional persistence layers alongside Git, making the overall architecture more efficient (keywords: availability, scaling, distributed data).
- Connecting all these components into a functioning overall architecture.
To sum up this overall architecture, we can speak of a Git-based implementation of a Jamstack-enabled headless CMS since we store not only the code but also the content in a Git repository. You can read more about this in our TechUp This is How Headless CMS Works with JAMstack.
Overview of the New Architecture
Developing this architecture to its current state required a lot of trial and error. Often, you want to achieve something but might need a different microservice to achieve the goal, which handles an additional transformation of the content. Ultimately, however, we arrived at a very nice solution, which I will now present in more detail. Let’s first take a quick look at what the whole thing is actually supposed to do.
Additionally, I would like to briefly mention that the term TechUp is equivalent to a blog post. TechHub then refers to the entirety of our TechUps and also the part of our website where our TechUps can be found.
Tasks of the Architecture
As a starting point, we have, as so often, a Github repository as a Single Source of Truth (SSOT), where for each TechUp there is a folder including illustrations and the actual written content in the form of a Markdown file called content.md.
The folder structure of our TechHub repository then looks like this:
|
|
It is important for later understanding to mention that each content.md file has a header with essential metadata. The header for our TechUp called “this-is-a-techup” could look like this:
|
|
The slug, together with the language, which we can read from the file path, is the “ID” of our TechUp and is used throughout the process to handle/identify a specific post. This is because the slug alone is not unique, as the same TechUp with the same slug can exist in both English and German.
Let’s get back to the tasks of the architecture…
So we have our SSOT with the content. Now our microservices come into play. The content.md file of a specific TechUp that we just discussed should now be converted to HTML to be displayed on our website. This HTML can then be stored as JSON in an AWS EC2-hosted Apache Solr in combination with the metadata from the header. Now the illustrations should be extracted from the folder and stored in an AWS S3 bucket. The work of the microservices is already done at this point. Finally, the TechUp can be accessed on our homepage - the data is then read by our Angular frontend from the data layer, i.e., from Solr and the S3 bucket, and displayed clearly. This could look like this:
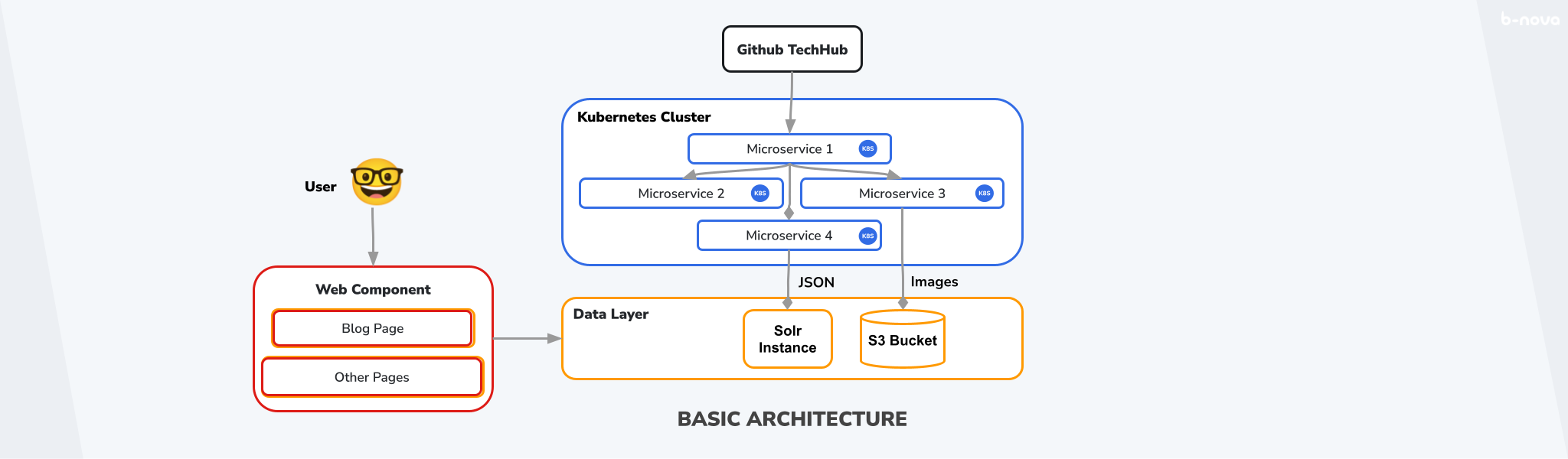
Figure: Basic Architecture
At this point, I would like to briefly mention that this is a micro-frontend approach. A micro-frontend is a single, isolated part of an entire web application. These micro-frontends can be called independently but usually do not contain basic standard components such as a header or footer, but only the specific, functionally limited functionality of a single page. Of course, we have already written an informative TechUp on this topic, which you can read here!
Now we increase the complexity by one level because we wanted to incorporate some features that were important to us.
Preview and Main Flow
The goal was to be able to test the entire process on the one hand and to get a preview of the respective TechUp before it is released for publication on our website.
To achieve this, we duplicate the components, i.e., the cluster, the instances in our data layer, and the web component, and get a copy of our system. Both systems have the same Github repository as SSOT and basically do the same things. We call the system that we use for testing and previewing the “Preview Flow” and its components “dev” for development. We call the system that creates the publicly visible TechUp page the “Main Flow” and its components “prod” for production. The whole thing looks like this:
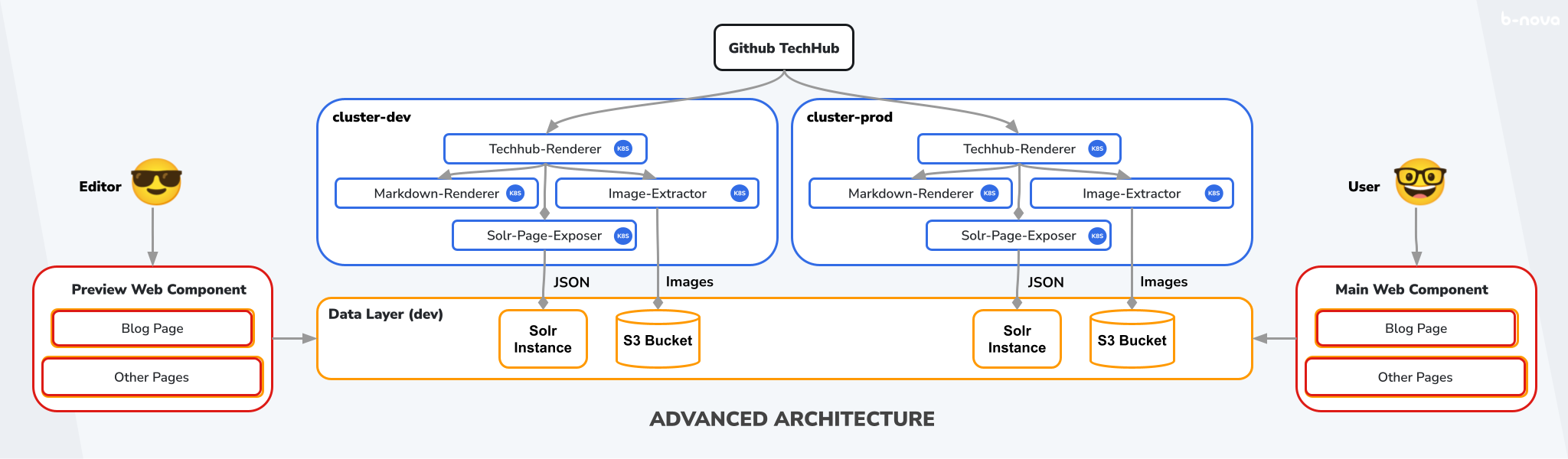
Figure: Advanced Architecture
Since all components are exact copies of each other, we need to use environment variables to ensure that dev components, i.e., the microservices in cluster-dev and the preview web component, also use the corresponding dev Solr instance and the dev S3 bucket so that the systems remain separate.
But how should our architecture know when to use the Preview Flow and when to use the Main Flow? This is where Github Actions come into play.
Github Actions
With Github Actions, you can create workflows to automate software workflows. You can learn more about Github Actions here.
To visualize this, let’s take a look at the full illustration right away. Here is a summary of the components that we will look at in more detail:
- Github Actions (Black)
- Kubernetes Microservices (Blue)
- Data Layer: AWS-hosted Apache Solr and AWS S3 (Orange)
- Angular Web Components on AWS Amplify (Red)
The following illustration shows the individual components and their relationship to each other. The arrow color indicates whether it is a write operation (red), read operation (green), or an activation (gray). Here is an illustration of the entire architecture as it is currently in use:
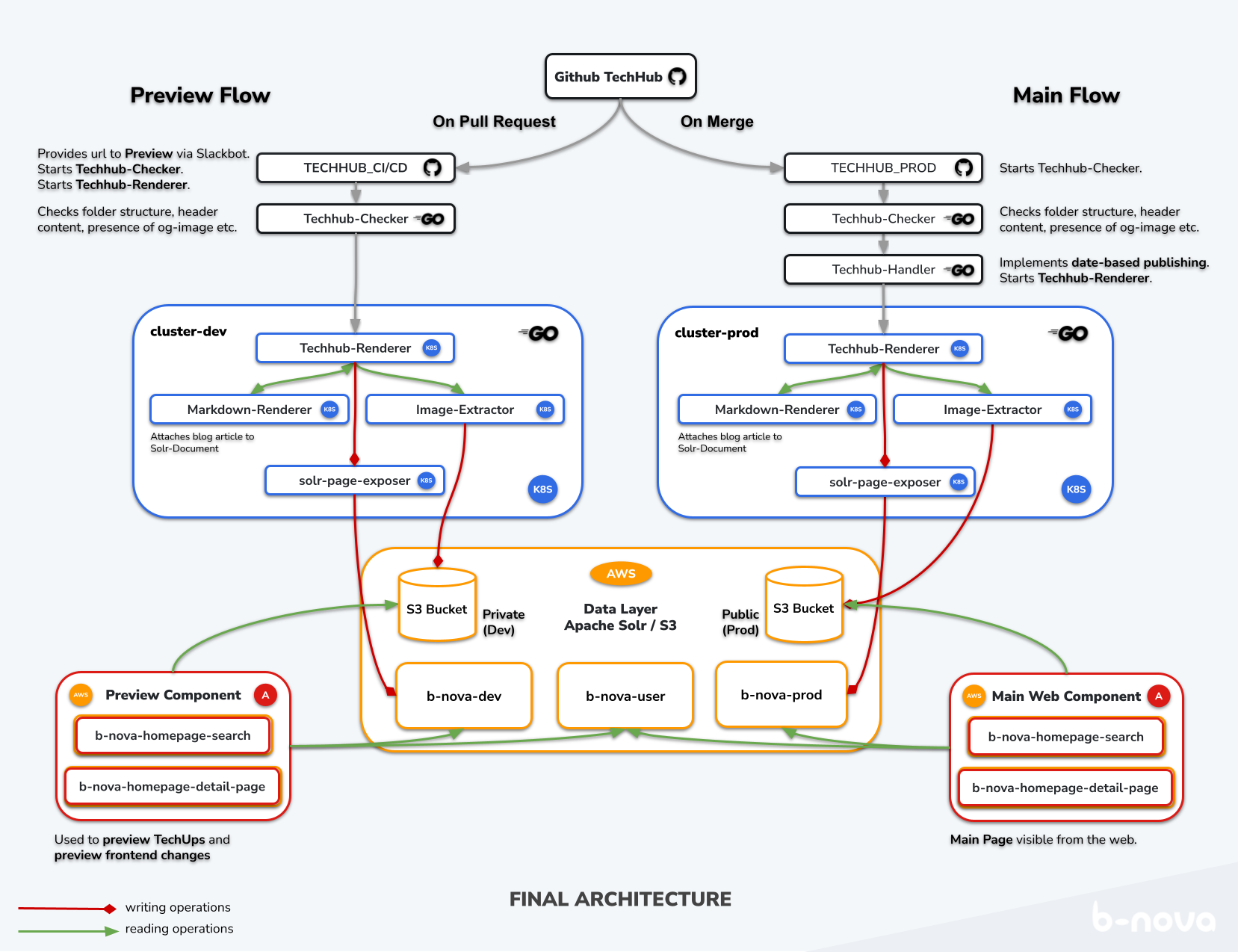
Figure: Current Architecture
Now let’s take a closer look at the individual components. 😁
Preview Flow: TECHHUB_CI/CD
This action starts automatically as soon as a pull request is created and directly calls the Techhub Renderer Service with appropriate parameters, which generates the page for us - provided the Techhub check was successful! Here, the corresponding environment variables are also passed, which clarify that the services from the cluster-dev should be used.
A pull request signals that a branch has already been created and data is available for which we want to generate a preview, which is why we use the PR as a starting mechanism here.
This is what the trigger of this action looks like in the cicd.yml file:
|
|
Techhub-Checker
Regardless of whether the Preview or Main Flow is to be used, the Techhub-Checker action is always executed. Let’s first take a brief look at what the Techhub-Checker does.
The Techhub-Checker is a Golang program that is executed by the action and checks the integrity of our repository. Since we have our Single Source of Truth here and this is the last point where humans are involved, we want to ensure that every new TechUp meets certain schematic requirements. This is particularly important so that no problems arise during further processing by the microservices.
These schematic requirements include rules regarding:
- Folder names
- File names
- Information in the header of the Markdown file
If one of these checks fails, a corresponding error message is output directly in the pull request. If this action runs successfully, the Techhub-Handler (prod) or the Techhub-Renderer (dev) is started.
Main Flow: TECHHUB_PROD
This action starts automatically as soon as a pull request is closed, or every four hours, and - provided the Techhub check was successful - starts another Golang program, namely the Techhub-Handler. Again, environment variables are passed, in this case for the cluster-prod.
|
|
You might be wondering why this action is executed every morning at four o’clock and why this additional step via the Techhub-Handler is necessary. This has to do with the fact that it should also be possible to post TechUps automatically. We will now look at how this works.
Techhub Handler
The Techhub-Handler is responsible for the automated publication of TechUps and distinguishes between two cases:
-
Closed Pull Request: If it is a closed PR, the date of the corresponding TechUp is checked, and if it is not in the future, i.e., it can be published, the Techhub Renderer Service is called.
-
Main Branch: If the handler is not called by closing a PR but by the four-hour cron job, there is no specific TechUp whose date can be checked. The date of each individual post must be checked, and HTTP requests are made to the
b-nova-prodSolr to see if the post already exists. If the post does not yet exist, the Techhub-Renderer Service is also called for publication.This case is there to discover TechUps that were ignored in case 1 but whose publication date is no longer in the past.
The Microservice Cluster
The Golang microservices are responsible for important backend tasks and together form a Kubernetes cluster. Whether we are in the Preview or Main Flow is only determined at this point (via environment variables) by which cluster the data is processed from and then written to which instances of our data layer. The functionality of the services does not otherwise differ between cluster-dev and cluster-prod.
Let’s take a look at what these four services actually do.
Techhub-Renderer
The Techhub-Renderer is our entry point. We can start it for our example TechUp with this HTTP request: http://localhost:8080/getpage?slug=this-is-a-techup&lang=de.
The getPage method is thus called with parameters slug = this-is-a-techup and lang = de, fetches and stores the repository locally, and searches for the correct file by comparing the given slug with the respective slugs from the headers of all .md files.
If this file is found, a StaticPage object is created, which is filled with metadata extracted from the header and later sent to the corresponding Solr as part of our JSON document. The object looks like this:
|
|
Next, the content of the body of the .md file, i.e., everything after the header, is sent to the Markdown Renderer Service, converted from Markdown to HTML there, and stored in our StaticPage under Article.
Now we still have to take care of the illustrations. To do this, the aforementioned HTML body is searched for HTML image tags (e.g., <img src="image1.png">) using a regex, and the file names extracted from the tags are stored in an array. For each file name in this array, a request is made to the Image Extractor Service, which returns the corresponding URL to the image on the AWS S3 bucket. The src of each image tag is now replaced with the corresponding URL that leads to the same illustration, but this time on the S3 bucket.
The finished “filled” StaticPage object is now sent as an HTTP post to the Solr-Page-Exposer service for further processing in the form of JSON.
As you can see, the Techhub-Renderer does most of the work and is the heart of our cluster. I will only briefly highlight the other services, as their function is trivial.
Markdown Renderer
The Markdown Renderer is simple and can be called under http://localhost:8081/md. It receives Markdown text and returns HTML.
Image Extractor
We use the Image Extractor by sending an HTTP post to the following address and including the respective illustration: http://localhost:8082/upload?name="<ImageName>"&bucketName="<bucketName>"&imgPath="<imgPath>"&lang="<language>". So it gets the name of the S3 bucket defined with environment variables depending on the flow, including other parameters and of course the illustration itself, uploads it to the bucket in the right place, and returns the corresponding URL to the image.
Solr Page Exposer
The Solr Page Exposer can be used by making an HTTP post with the finished StaticPage JSON object to http://localhost:8083/expose. The task of the Page Exposer is to feed the finished page in the form of a JSON object into the correct Solr instance.
Done!
Frontend - Amplify Component
Since all data is now available on our data layer, the Angular web component can display the TechUp flawlessly when called with the appropriate parameters (slug and language). Hooray!
Conclusion
I hope that I was able to give you a better understanding of our implementation of a Jamstack-enabled headless CMS and that the advantages of such an architecture as well as the concrete functionality of our publishing and preview system are now a little clearer. If you’re interested in more TechUps, feel free to check out our TechHub - now you know what’s behind it. And as always, stay tuned! 🔥
This techup has been translated automatically by Gemini