Machine Learning with Tensorflow
My last TechUp was about the basics of deep learning. We got to know key concepts and terms. Today we’re go one step further and deal with the topic of TensorFlow. TensorFlow is an “end-to-end open source machine learning platform”. It was originally developed by Google, but is now available under an open source license. The focus is primarily on speech recognition and image processing. This is possible thanks to neural networks.
Knowing the basics of Python, machine learning concepts and matrix calculation are definitely recommended for using TensorFlow.
Setup 💻
An installation of Python is required for the basic setup. You can check whether you are using the correct version with the python3 --version command. A version between 3.7 and 3.10. is recommended. You also need the Python package manager (pip) in version >19.0 ( or >20.3 for macOS). In addition, you’ll need an IDE, which is where JetBrains’ PyCharm comes in handy. You can download it here.
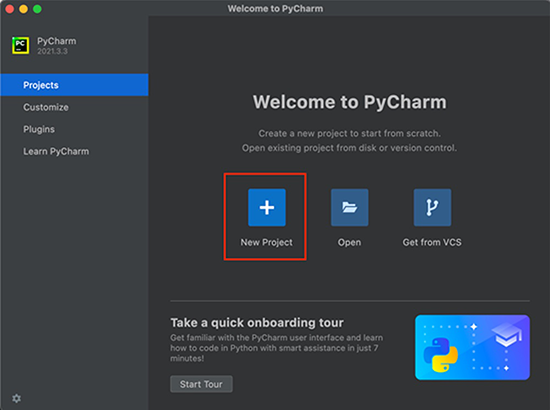
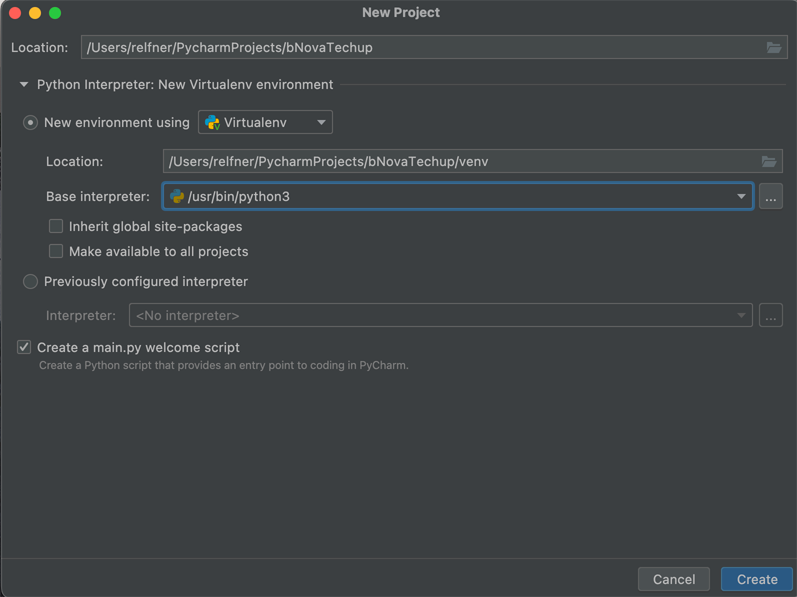
You can then create a new project using PyCharm. The only thing to note here is that you have to specify the desired name and select the correct Python version.
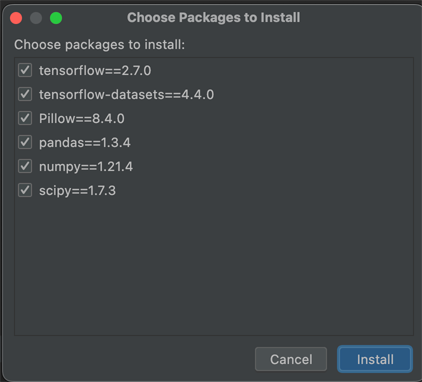
Once the project has been set up, you need a file called requirements.txt, in which you specify which versions of the specified packages should be used. Within the Tensorflow Installation Guide, this is described as follows:
|
|
The IDE will then show you a message for you to install the requirements. If you do it that way, you’ll get this display:
Once the installation is complete, you can open the Python Console.
Unfortunately, in our case, there were issues with the M1 processor. For this reason we have chosen a different variant, which is to use TensorFlow locally. First of all, an installation of Miniforge was necessary. With that, it’s possible to install Python packages, which were compiled natively for the Apple silicon chip.
|
|
After the installation, you can deactivate the standard environment.
|
|
For our example, we created a virtual environment with Python version 3.8. Once created, it still needs to be activated.
|
|
Now you can start installing all the necessary dependencies. This includes all TensorFlow dependencies first, before you install further requirements via pip for TensorFlow.
|
|
You should then be at the same level as when installing within the IDE. Assuming there were no errors. In our case, we then used the console within Jupyter using jupyter notebook.
Now we must do the following steps:
import tensorflow as tf
Here it can happen that you get some warnings, if you have a GPU setup on your machine. However, this is not relevant for our case.
To check whether tensorflow is in the correct version, you can output the version in the console: print(tf.__version__).
These are all the necessary imports:
|
|
Hands-on 🙏
Example MNIST database
Now we want to use the MNIST database as a first example, which is used as a Hello World program compared to other programming languages. The goal is to use a machine learning model that recognizes handwritten digits.
To do this, we first create a new Python file and import all the necessary libraries. The remaining requirements have already been loaded via the requirements file. With the import of os, it’s possible to set environment variables, as can be seen from the log level.
As a third step, a main block is created into which we load the training data from the MNIST database, including some information. The training data is defined as mnist_train and the loaded information is stored in the variable info. In addition, the training data must be loaded.
|
|
As soon as you run this file, you’ll get the following output in the console.
|
|
Now that you have defined the variable info, you can simply print it in the console by calling it up. You can now also visualize your training data. In the example of the MNIST database, these are images of handwritten numbers. To do this, use this command:
|
|
Once you have executed this command, you will see the following image:

Now you need a method that brings the data into the desired form. In our case, the images are represented as pixel numbers from 1 to 255. However, if you use machine learning, the data should ideally be between 0 and 1. A map function containing a lambda is now used for this. The image that is to be normalized and the label are passed as parameters. However, the label should remain the same. In order to gain performance, the data is loaded into the cache. In the case of the database, this does not have a major impact on the rest of the system.
If the dataset is the training data, the numbers should be randomised. The data set can then be returned.
|
|
This method can be defined before the main block. It can then be called within the main block and reassigned to the variable.
|
|
Now it’s still necessary to create a model. A new function named create_model is created for this. This is where Keras is used for the first time. The first layer has a “shape” of 28 pixels x 28 pixels x 1 color channel. With the function Flatten(), the layer becomes a single layer. During that process, the content of the shape is multiplied (28x28x1 = 784). With the function Dense(), the model is “fed”, it learns the the differences and finds out how to classify the data.
Finally, another function is called, which is created in the next step.
|
|
This function must be called inside the main block:
|
|
Now another function is necessary for compiling the model, which is defined as an input parameter. The function compile() defines the optimizer, the loss function and the metrics for further information.
|
|
As soon as this function is finished, you can run your program again. You will receive some information as an output. You can see how many parameters are processed per layer and how correctness improves per pass.
|
|
To check how well the model has been trained, you can use the test data from the first step and use the evaluate() function. You can see the accuracy that has been achieved using data that the model has not yet known.
|
|
If you now want to save your work, you can do so with model.save('mnist.h5'). Within your project, you will now find that file.
Example online data
If you want to use a model with data from the internet, check out the Machine Learning Repository. The most used data set is the Iris Dataset.
To do this, you first need a function that loads the relevant data from the Internet. For this, you need the corresponding Url and the desired storage location must be defined.
|
|
This function can now be called within a main block so that the data is loaded.
|
|
As soon as you run the file for the first time, the data is available to you. In any case, it’s recommended to look at the data for the model first, to check whether it corresponds to the desired format or needs to be adjusted.
|
|
In this case we are missing the names of the columns. Therefore, you’ll have to add them so that the data can be assigned. To do this, you first create an array with the appropriate name. Instead of names, numbers should be used so that the model can handle them better. For this, we create a map which assigns the corresponding types to a number.
|
|
This function can now also be called within the main block iris_data = parse_iris_data(iris_filepath). To check your result, you can compare the number of “species”. There should be 50 of each species.
|
|
Finally, the data needs to be loaded into a TensorFlow dataset. You now create another function for this. To define this set, you must first determine the features. These correspond to the column names. In this example, iris_columsn can be used directly. The labels must then also be read from the dataframe.
|
|
This function must also be called in the main block.
|
|
The end result would now look like this:
|
|
Once this code is executed, the appropriate data is downloaded, prepared, and loaded into the dateset.
Conclusion ✨
In this TechUp we were able to go one step further, since we already laid the foundations for the topic last time. That’s why we’ve dedicated ourselves to the practical part today, using the most well-known database in the field of machine learning. Furthermore, we were able to show how easy it is to create an ML model with the help of TensorFlow and how to train and test it directly. We were also able to go one step further and use data from the Internet. This means that we are now able to use existing data, since you can save a lot of time here if you don’t have to collect your own data. But at this point it’s important to say that these are very simple basics in the area of TensorFlow. So there are many more exciting topics in this area that we will look at.
Stay tuned! 🚀