How to set up Kafka on Kubernetes with Strimzi in 5 minutes
Strimzi is a tool with which a full fledged Apache Kafka-cluster including Apache ZooKeeper can be set up on Kubernetes or OpenShift. Strimzi is an open-source project that Jakub Scholz and Paolo Patierno, both Red Hat employees at the time of writing, are contributing to. In addition, Strimzi is a CNCF Sandbox Project. Today we look at how Strimzi works under the hood and how you can put Kafka on in 5 minutes.
This is the second part in our Event-driven systems series. In the first part we looked at Apache Kafka and what Kafka is particularly suitable for. Here is a short recap of the most important points:
-
Kafka makes data streams, simply called streams, available in a network of computers called cluster
-
Microservices can use such a stream efficiently and thus keep throughput and latency low
-
Streams uses ordering, rewinds, compaction and replication
-
Resilience through robust architecture, distributed system
-
Horizontal scaling thanks to clusters, ideal for distributed, event-based system architectures
Kafka configuration with Kubernetes operator pattern
Strimzi takes on the configuration and continuous deployment of the Kafka infrastructure in your Kubernetes cluster. With the Operator Pattern Kubernetes offers the possibility to define your own resources, so-called Custom Resources. Strimzi uses the operator pattern to configure the desired Kafka cluster. The idea is that all Kafka settings are set in different operators and that these operators are played on the Kubernetes cluster.
Strimzi provides 3 operators: a cluster operator and two entity operators. The Entity Operators are divided into the Topic Operator and the User Operator. The whole specification is on the offiziellen Dokumentations-Webseite definiert.
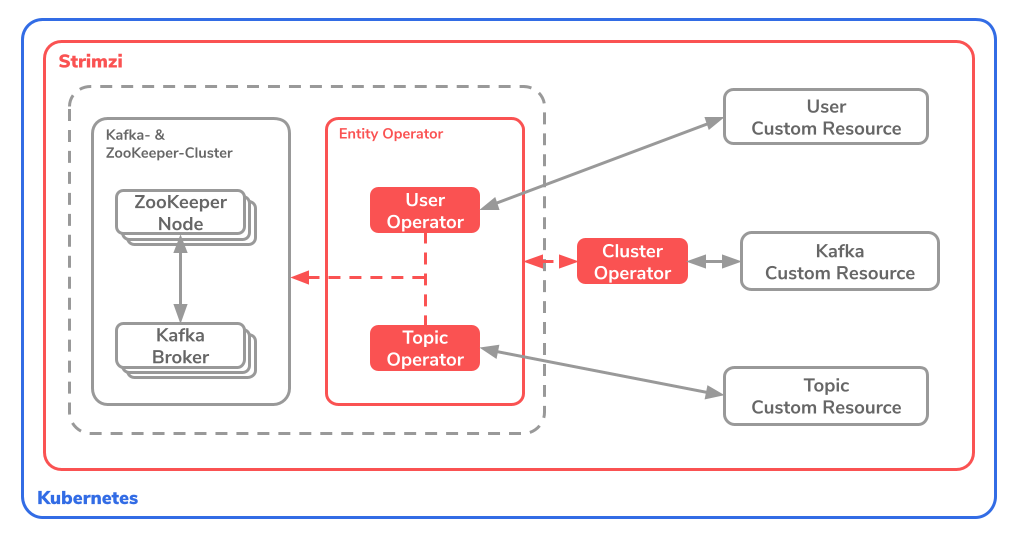
The idea is that Strimzi can use the operators (in red above) to control the ZooKeeper nodes, the Kafka brokers and the entire Kafka cluster via the {bnova} bold-End0} {bnova} boldEnd0 }0 Manage Resources (rechts im Bild) * * .
Cluster operator
The cluster operator is used to configure the * * Kafka and ZooKeeper cluster * *, as well as the two entity operators. The cluster operator is therefore responsible for deploying the user and topic operators. Kubernetes Custom Resources are used for this.
The cluster operator also takes on the configuration and deployment of other Kafka components such as, but not limited to:
-
Kafka Connect
-
Kafka Connector
-
Kafka MirrorMaker
-
Kafka Bridge
-
and other Kafka resources
The custom resource for the * * cluster operator * * looks like this:
|
|
A Kafka cluster with the designation my-cluster and 3 replicas is configured here.
Topic operator
The topic operator offers the possibility to manage KafkaTopics in the Kafka cluster. This is done through Kubernetes Custom Resources.

The operator allows 3 basic operations:
-
Create: Create KafkaTopic
-
Delete: Delete KafkaTopic
-
Change: Modify KafkaTopic
The custom resource for a topic operator looks like this:
|
|
A KafkaTopic named my-topic with a Partitions and Replica set of 1 is configured.
User operator
The user operator, like the topic operator, offers the option of KafkaUser in the Kafka cluster. This is also done through Kubernetes Custom Resources.
This operator also allows 3 basic operations:
-
Create: Create KafkaUser
-
Delete: Delete KafkaUser
-
Change: Modify KafkaUser
The custom resource, CR for short, for a user operator looks like this:
|
|
It is important to note the operation field on the topic resource with the name connect-cluster-offsets.
The my-user user is given the right to write in the above mentioned topic via the CR.
One more word about storage
Since Kafka and ZooKeeper are state-dependent (stateful) applications, the state must be able to be saved. The _
Kubernetes Custom Resources_ that can receive a storage property are the Kafka cluster Kafka.spec.kafka and the
ZooKeeper cluster Kafka.spec.zookeeper. Strimzi supports 3 storage types:
- Ephemeral: In German, the Ephemeral Storage Type saves the data only as long as the instance of the application is running. Volumes are used as the storage destination. Thus, the data is lost as soon as the pod has to restart. This storage type is suitable for development, but not for productive use. In particular if the Replication value of KafkaTopics is 1 and/or if single-node ZooKeeper instances.
In the resource definition for a development environment it could look something like this:
|
|
- Persistent: The Persistent Storage Type, as the name suggests, allows permanent, cross-instance storage of runtime data. This is done using Kubernetes’ own Persistent Volume Claims, or PVCs for short. It is important to note here that changing the assigned storage units can only be changed if the Kubernetes cluster supports Persistent Volume Resizing.
In the resource definition of an unchangeable persistence it could look something like this:
|
|
- JBOD: The last storage type is an acronym for Just a Bunch Of Disks and is only suitable for the Kafka cluster and not for the ZooKeeper instance. In short, JBOD abstracts both of the above storage types and can thus be enlarged or reduced as required. This is certainly the most suitable storage type for a scalable Kafka cluster, as it can be adapted as required at runtime.
In a JBOD specification, the resource definition could look like this:
|
|
When setting up a Kafka cluster with Strimzi, you can easily and conveniently define the storage types as required using Kubernetes’ own CRDs. First of all, it must be taken into account which requirements the application has on the Kafka cluster and thus decide which Storages Types are suitable for the cluster.
Set up a Kafka cluster
Now it’s getting serious. In order to create a Kafka infrastructure on the Kubernetes cluster with Strimzi, we first need an executable cluster. This can be done directly on one in the cloud gehosteten Cluster erfolgen oder alternativ auch lokal mit minikube .
First, connect to your Kubernetes cluster. Make sure you are connected to your Kubernetes cluster via kubectl. Then
create a kafka namspace on the cluster. This can be done very easily from the terminal with the kubectl-CLI.
|
|
So now we have a namespace called kafka. Then we would like to import the Custom Resource Definition, or CRD for
short, from Strimzi. This CRD enables the syntax of Kubernetes-native custom resources to be extended to include
Strimzi-specific definitions. If you are interested, you can examine this CRD
at https://strimzi.io/install/latest.
The installation file officially made available by Strimzi, which ClusterRoles, ClusterRoleBinding and other Custom
Resource Definitions created via the CRD, is the heart of the Strimzi installation.
|
|
Then apply the ready-made manifest that carries out the Kafka cluster with all the configurations of the Kafka topic / users.
|
|
This is a exemplary configuration, which would have to be adjusted in your Real-World project. The Custom
Resource used here for the Kafka cluster is defined in the kafka-persistent-single.yaml manifest.
|
|
Explanation: as can be seen from the above manifest, a Kafka cluster my-cluster with Kafka version 2.7.0, two ports
9092 and 9093 is configured here. Certain Kafka-specific configs are defined in the _config _ \ field, the Storage
Type here is jbod with a persistent claim of 100Gi. ZooKeeper with an instance is also specified. The _topic_and user
operators are initialized empty.
You can watch the pods start up in real time:
|
|
Check whether the Kafka cluster has started up correctly:
|
|
Congratulation! Hopefully you have successfully set up a Kafka instance with ZooKeeper on your Kubernetes cluster with Strimzi in less than 5 minutes.
Testing the Kafka stream
Since the Kafka cluster is now executable with Strimzi, we would like to write one or more messages in a topic via
Kafka stream and receive them somewhere as a consumer. There is a useful Docker image from
Strimzi, quay.io/strimzi/kafka, which a producer or consumer can provide as a service.
Let’s first create a generic producer service with the following expression:
|
|
The consumer executes the shell script bin/kafka-console-producer.sh and creates a KafkaTopic with the name my-topic
. In an interactive prompt you can write any value into the stream of the topic.
In the next step, we create a second, generic consumer with the same Docker image in a second terminal window using the following command:
|
|
As before, this producer executes a shell script bin/kafka-console-consumer.sh, whereby the topic my-topic is
addressed. All messages are received and processed from the beginning (--from-beginning als Parameter).
If you have already written values to the producer, they should be logged out at the consumer prompt. If not, write some in the producer and then look in the consumer. If everything works correctly, the typed messages should be transferred via the Kafka cluster in the stream. Congratulation ! It wasn’t that difficult, was it?
Custom configuration of the Kafka cluster
In their offiziellen GitHub Strimzi provides a full-fledged repo in which templates of various Custom Resources Definitions and configuration manifests are available. The best thing to do is to download the repo via Git or via .zip.
Define custom resource definition
There is a install/cluster-operator \ directory in the repo. It contains different yaml files with which the custom
resource definition can be configured. If you want to import the custom resource definition into your own namespace
again, it is sufficient to make the configurations in this directory, replace the value STRIMZI_NAMESPACE with the
namespace name used in the file install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml and the
following kubectl command against your Kubernetes -Run cluster:
|
|
Examples for Kafka resources
As already described above, there are basically 3 different resources that we want to configure for Kafka:
-
Kafka
-
KafkaTopic
-
KafkaUser
In the directory examples/ you will find, among other things, 3 subdirectories with example manifests for exactly
these 3 resources, which you can import via kubectl \ - CLI. The directories are respectively examples/kafka/
, examples/topic/ and examples/user/. Simply search for it, configure it, import it and ideally install it in the
cluster with GitOps patterns so that the Kafka cluster can run as transparently and robustly as possible.
Kubernetes-enabled extensions
Strimzi provides the use of Kubernetes-native features. Strimzi uses the following well-known cloud-native projects:
Kafka in the cloud with Amazon MSK
One more word about alternative solutions to Strimzi: Cloud providers such as AWS also offer the option of using a Kafka cluster via an in-house service. At AWS this service is called MSK, short for Managed Streaming for Apache Kafka. MSK runs a prefabricated, completely configurable Kafka cluster on an EC2 instance.
Basically you can set up a Kafka cluster with AWS CLI and import the desired configuration with JSON files.
Conclusion
Strimzi greatly simplifies setting up a full-fledged Kafka infrastructure on a Kubernetes cluster. All configurations can be summarized in a Git repository and ideally rolled out again on the respective cluster using a GitOps pattern. Strimzi greatly reduces the abstraction of managing a Kafka cluster in the cloud. Thumbs up and stay tuned!
Further resources and sources
https://strimzi.io/documentation/
https://itnext.io/kafka-on-kubernetes-the-strimzi-way-part-1-bdff3e451788
https://www.youtube.com/watch?v=RyJqt139I94&feature=youtu.be&t=17066
https://www.youtube.com/watch?v=GSh9aHvdZco
This text was automatically translated with our golang markdown translator.