
Figure: PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
With the help of Machine Learning algorithms, a lot of interesting and valuable information can be extracted from large data sets. Depending on the use case, different algorithms are suitable for different scenarios. In previous TechUps, Stefan has already explained the basics of neural networks and we have seen how the Random Forest algorithm can be used to predict the survival probability of passengers on the Titanic ship. In this TechUp, we want to look at another technique that helps us detect patterns in data: Anomaly Detection.
What is Anomaly Detection?
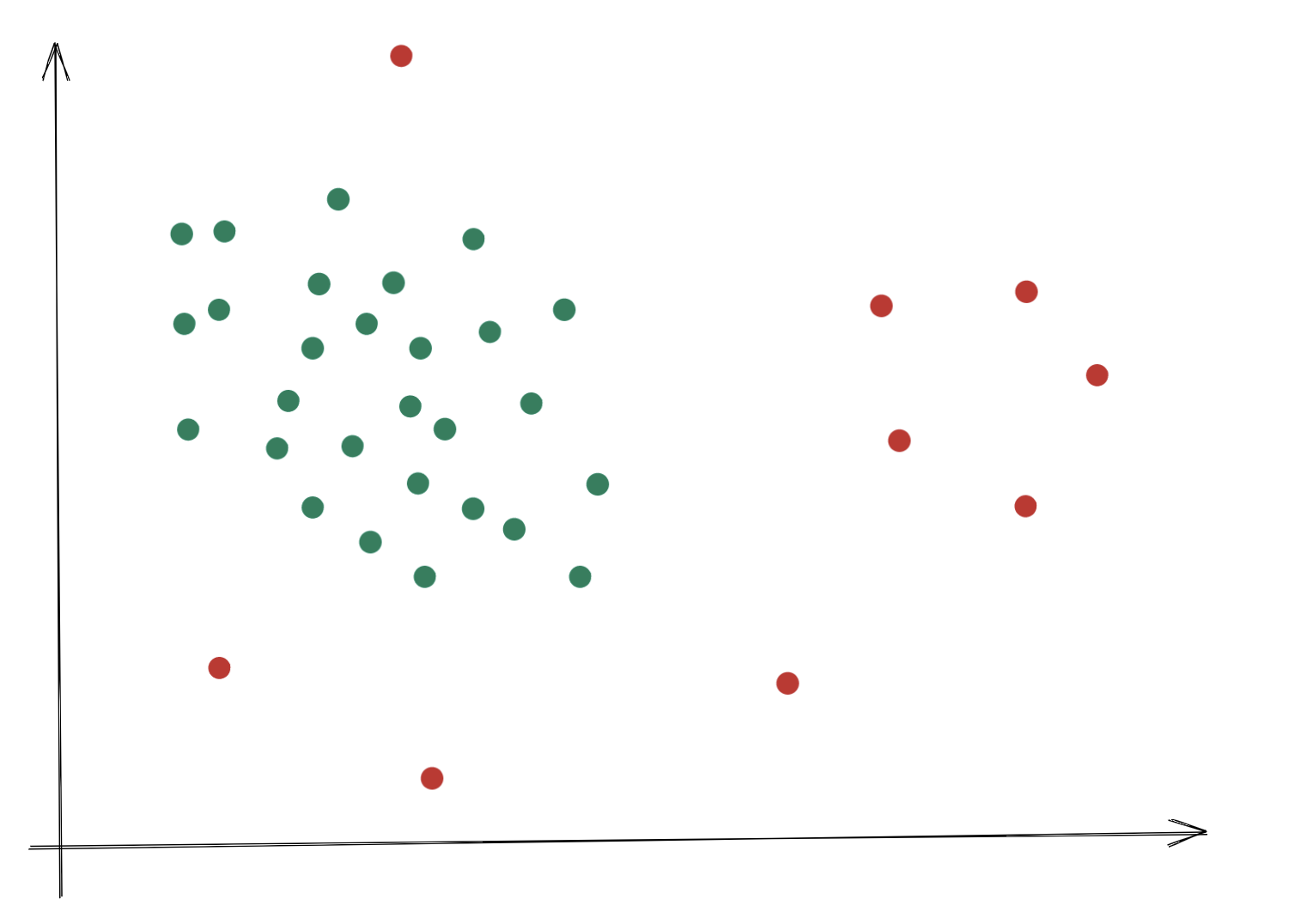
Anomaly Detection is a method we use to find out whether a certain event related to a dataset conforms to the norm or not. There are many use cases that can illustrate this.
Take, for example, the sensor system of a machine that provides data points about vibrations at various measuring points. If we record this data over a longer period of time, we can see patterns that show what kind of vibrations the machine normally exhibits. As soon as data points are measured that deviate from these patterns, we can assume that the machine is no longer in normal condition. This can be an indication that the machine is defective and needs to be repaired.
Other use cases exist in many areas:
- Cybersecurity (e.g. detection of anomalies in network traffic).
- Fraud detection (e.g. credit card fraud or insurance fraud)
- Healthcare (e.g. rare disease detection)
- Road traffic (e.g. detection of accidents)
How does Anomaly Detection work?
As we have seen, there are many use cases where Anomaly Detection can be used. If we want to use Machine Learning algorithms to detect anomalies, there are two different approaches that we will look at below.
However, before we think about training models, we should first think about the data basis. First of all, in order to be able to detect anomalies, data is needed that represents the normal state. Depending on the algorithm, classified data may also be needed that deviates sufficiently from the norm to be classified as an anomaly in the first place. Especially in anomaly detection, the quality of the data basis is crucial. Consider fraud detection, for example: we can assume that the majority of data points are not fraudulent. If the few fraudulent data points are not sufficiently representative or are misclassified, our algorithm may make incorrect predictions. In this case, this can lead to over- or under-classification, which can have severe consequences depending on the field of application.
Now, once the quality of the data basis is assured, we can think about the algorithms. Here we distinguish between two different approaches: Supervised Learning and Unsupervised Learning. If we want to use a Supervised Learning algorithm, our data set must be classified, which means that each data point must be classified as either a normal state or an anomaly. Depending on the use case, it can be difficult to generate such data.
If we look at the example of a machine’s sensors, we would expect few to no anomalies to occur under normal circumstances. However, if we want to take a supervised approach, we would either need to collect data over relatively long periods of time or purposefully damage or disrupt the machine to generate anomaly data points. Classifying the sensor data correctly is also not necessarily easy. In such cases, an Unsupervised Learning Algorithm is better suited, which does not require previously classified data, but uses pattern recognition to detect the anomalies itself.
Example: Anomaly detection based on credit card fraud
To illustrate the two approaches, let’s look at a data set on credit card fraud as an example. The data includes a total of almost 284,000 credit card transactions over two days in September 2013, of which 492 were classified as fraudulent. The dataset can be downloaded from Kaggle.
In total, we have 30 numerical features, 28 of which are the result of a Principal Component Analysis (PCA) transformation of the original data. The other two characteristics are the time and the amount of the transaction. Due to anonymisation measures, no further information on the individual features is known.
Since we have classified data, we can use a supervised learning approach. Here we will use the Random Forest Algorithm, which we already learned about in my TechUp on Decision Trees.
As another approach, we will also introduce Autoencoder after this example to illustrate an Unsupervised Learning algorithm.
Anomaly Detection with Random Forest
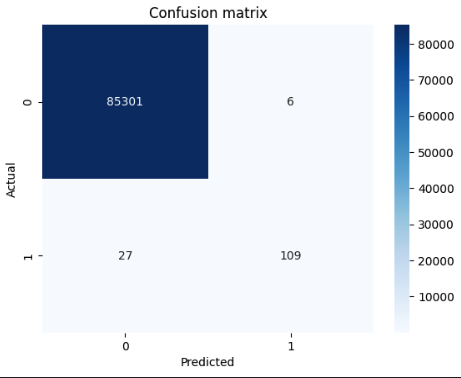
The Random Forest algorithm can be used to train a model that can classify individual data points based on their features. To train the model, we need classified data, which we find in our data set. We will now train the model and then compare the predictions of the model with the actual classifications. 🤓
|
|
The results are quite worth seeing, despite the little effort involved:
Anomaly Detection with Autoencoders
Autoencoders are a special type or architecture of neural networks that are designed to compress data. The idea behind autoencoders is best explained with the help of an illustration:
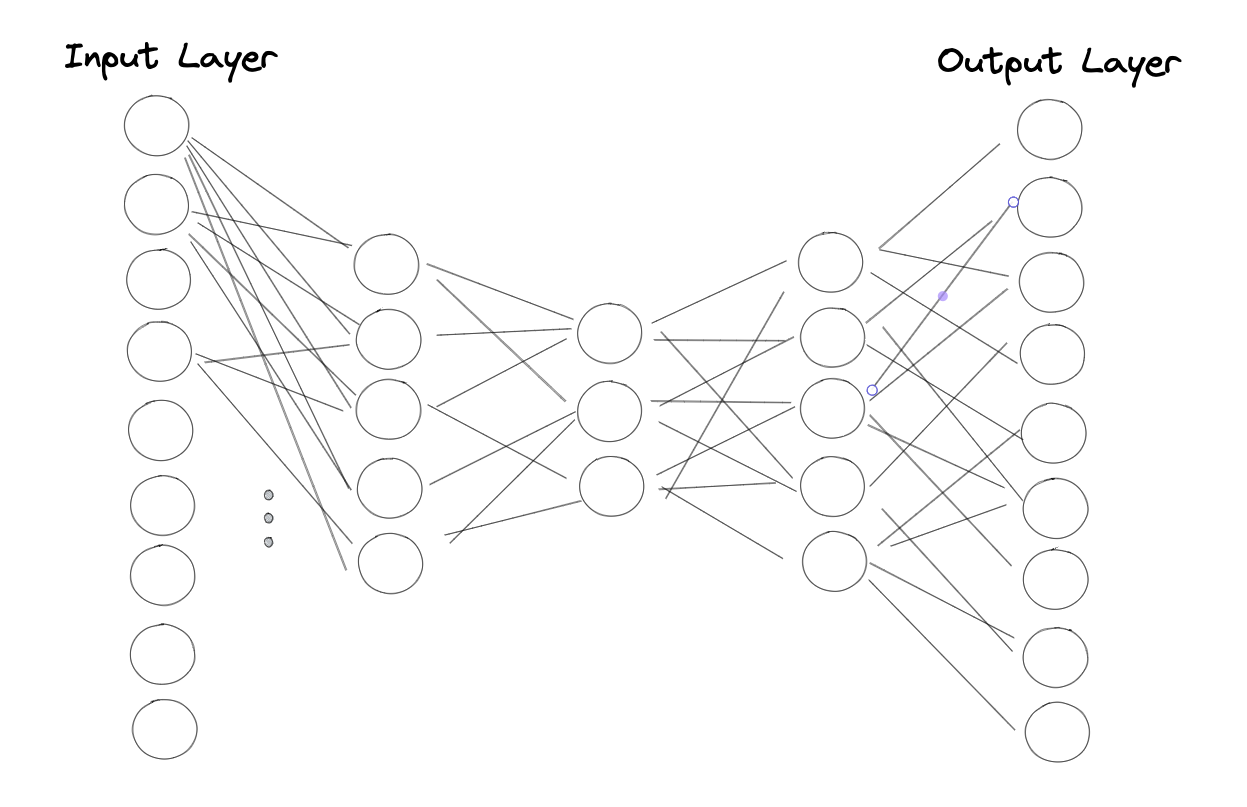
We see a neural network with one input, one output and three hidden layers. All layers are fully interconnected, that is, all neurons are connected to all neurons of the previous and subsequent layers. As you can see, the number of neurons decreases from layer to layer and the network is mirrored in the middle.
What is special about autoencoders is the way they are trained. The network is trained to provide the same output as input. If we take our dataset as an example, we would expect the same values in the output for every feature in every data point. The tapering of the layers means that the network has to compress the input data to the most important features or information in order to reproduce them in the output.
The trained model has now learned the structure of the training data and can classify new data points based on this structure. If one now wants to classify a new data point, it is pushed through the network and the output of the network is compared with the input. The greater the difference between input and output, the more the data point deviates from the structure of the training data and the more likely it is to be an anomaly. Cool, isn’t it? 😎
Below we train an autoencoder with PyTorch and use it to classify new data points.
|
|
We can now evaluate the trained model with the pre-classified data points. To do this, we compare the differences between the input and output of the autoencoder (loss) of a subset of the non-fraud data points with those of the fraud data points. The greater the difference between the two data sets, the better the model is at detecting anomalies.
|
|
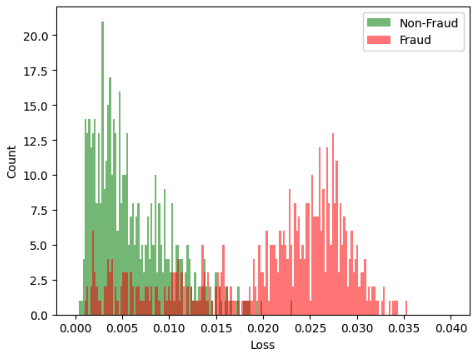
As you can see in the figure, the loss values of the fraud data points differ significantly from those of the non-fraud data points. We can now define a threshold value from which a data point is classified as an anomaly.
Of course, our classification is not optimal, as can be seen from the overlap of the two histograms. Whether autoencoders are the right tool for detecting anomalies depends strongly on the data and must always be evaluated individually.
Conclusion
I hope I could give you an interesting insight into the field of anomaly detection with this TechUp. There are many areas where you can gain valuable information by detecting data points that deviate from the (supposed) norm. Stay tuned! 🙌
Why don’t you read Stefan’s TechUp on the basics of neural networks! 🚀
This TechUp was translated by our automatic Markdown Translator. 🙌