
In this TechUp, I take a closer look at Materialize and its key concepts. Materialize was founded 2019 by Frank McSherry (Chief Scientist) and Arjun Narayan (CEO) and calls itself a Streaming Database - we’ll look at what that means in a moment. McSherry was part of a research project called Naiad in 2013 and helped create the concept of Timely/Differential Dataflow, which is now the core of the Materialize Engine. Surprisingly, he didn’t originally want to turn this technology into a commercial product. After several requests from Narayan, who at that time was very interested in the topic and saw its potential, the two finally joined forces and created this powerful product.
In addition to my research online and in numerous posts on Materialize’s website, I also had the opportunity to try out Materialize’s early access cloud native SaaS offering hands-on. And to be honest, I’m quite a fan, as the idea behind Materialize has convinced me. Before we take a look at Materialize, we need to know what’s meant by a streaming database in the first place.
What is a Streaming Database? 🤔
To begin with, the term “streaming” does not refer to the consumption of video or audio files from conventional streaming providers such as YouTube or Spotify, but rather to a continuous flow of freshly generated data that can be created and processed in real time. If you want to learn more about this topic, our TechUp on Kafka is a good entry point into the world of streaming data and message brokers.
Traditional streaming data processing often requires an additional microservice to perform transformations and feed the data into a database:
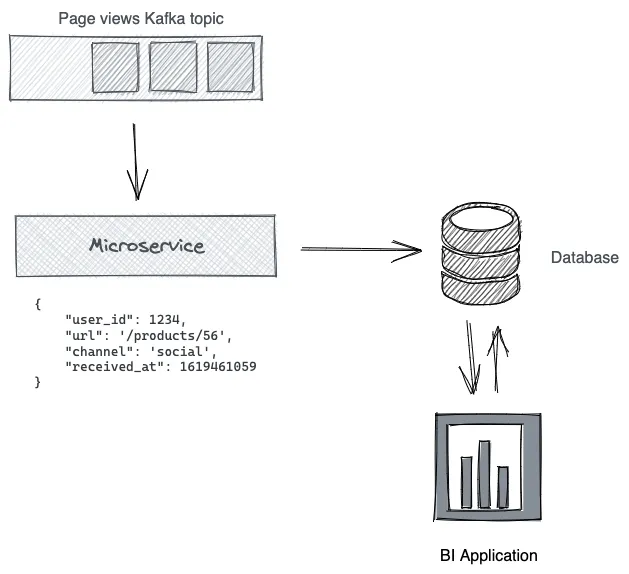
A streaming database has the same abstractions (tables, columns, rows, indexes) as a traditional database, but uses a stream processing engine instead of a query engine. The work is done on the write side, rather than the read side, which means one could argue that a streaming database is in a way an inversion of a traditional database. In this case, the microservice from the illustration is not necessary anymore, which reduces complexity.
There’s a great post about this on Materialize’s website, that does a great job of illustrating how a Streaming Database works.
What’s so special about Materialize? 🤓
Well, the premise of Materialize is to deliver the result of a database query as fast, correct and as a side effect as efficient as possible. For a low barrier to entry, queries are submitted via SQL (ANSI standard). So in usage, there is hardly any difference to conventional relational databases. But this is also (almost) the only thing Materialize has in common with conventional databases.
ℹ️ Streaming SQL: Since we are dealing with the querying of continuously changing data streams with SQL, we mostly use SQL commands that are continuously updated - this is called Streaming SQL.
Materialize offers the highest consistency guarantee
Simply put, this is about how correct the results of a database query are at a specific point in time. Materialize offers the highest consistency guarantee, namely strict serializability. This guarantees that despite the constant addition of new data as well as complex queries applied to it, the resulting table will always be accurate.
That Materialize successfully combines consistency, scalability and low-latency is remarkable. Now, to understand what makes Materialize so much faster, we need to make a small detour to the topic of SQL Views.
Views and materialized views
Essentially, with a query we can request data from a database and at the same time perform operations on it as desired to get the desired information from the data. A query might look like this:
|
|
If this is a query that we want to rerun from time to time, it would make sense to save it as a VIEW.
What is a view?
A view does nothing more than store our SQL query under a name, effectively providing an alias for our query, like so:
|
|
Now we can simply run our original query under my_view as follows: SELECT * FROM my_view.
The problem: If we want to view the results of our query, we have to execute it. In doing so, the calculation has to be re-executed each time. This not only costs time, but also computing power, and therefore money. But there is a solution for this problem as well - materialized views!
Batch processing in conventional databases
For queries that take very long and/or are too costly, it would make sense to run them, say, once a day or every few hours, and save the results, right? In fact, this is widely used and known as batch processing. To intermediately store the results of a query, there also exists the concept of a materialized view in databases. Here, a given query is stored just like a view, with the addition of storing the result in a “virtual” table. We only have to add the keyword MATERIALIZED, the results of our query are now available at any time and can be rapidly accessed:
|
|
Batch processing as well as traditional materialized views have the disadvantage that the resulting virtual table is just a snapshot of the data and as soon as something changes in the underlying data, it is no longer up to date. Another problem is that the implementation of materialized views in traditional databases can differ, and the underlying query has to be completely recalculated for each triggered view update, which can lead to high costs and increased complexity.
This is a problem because the most valuable data is the most current data. As a company, you always want to be able to react to current events, as this image illustrates:
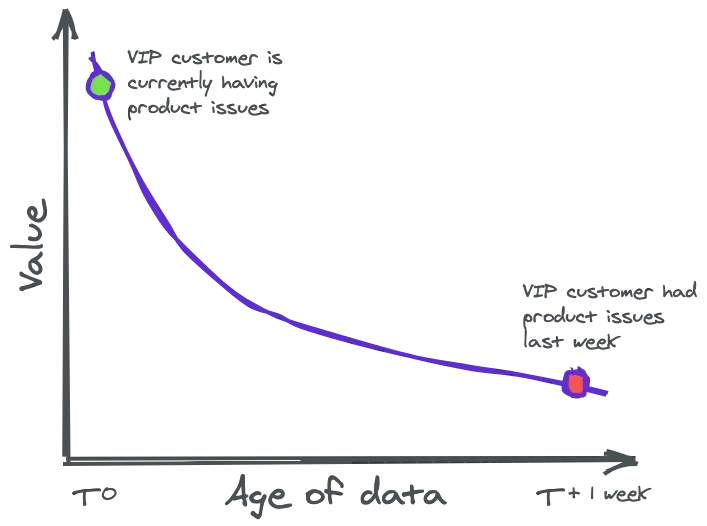
Figure: Source: Materialize
- Example 1: Suppose a user of your web service has problems. Instead of getting a message the following day that a user had problems the day before, it would be much better to get a real-time message and be able directly work on a solution with the customer.
- Example 2: A customer is browsing your e-commerce site and looking at products. The customer seems to be interested in a specific combination of various products, which unfortunately are not part of the currently running special offer. Wouldn’t it be practical to offer that customer a more suitable price or even a customized offer based on their customer profile to help them make a potential purchase decision?
To do this, we need data that is as up-to-date as possible. But how could we get up to date results of a complex and expensive database query?
Incrementally updated materialized views with Materialize
What makes Materialize so special is its ability to incrementally update materialized views. This means that the result of the query is always kept up to date. At the same time, no computational effort is wasted to query information that has been queried before. But how can this be done? This is where the concept of Timely / Differential Dataflow comes into play. The idea is simple: As soon as new data arrives, only the new data is transformed, and the view is updated accordingly. This is the core of Materialize’s magic.
But how does the whole thing work now?
There are many possible use cases for Materialize, but here’s a basic idea:
-
Connect Materialize to one or more data streams, so-called Sources, such as from:
- Kafka Topics
- PostgreSQL Change Data Capture
- Redpanda
-
Use SQL to create complex materialized views that make your data available as you need it for your use case.
- Stop here and use Materialize as a database that keeps the results of your complex SQL transformations up to date in real time and with the highest Consistency Guarantee (Strict Serializability) at all times.
- Create Sinks to output data changes in your materialized views (CDC) as event streams to further “consumers”.
My experience with Materialize
As soon as I got access to the cloud version of Materialize, I worked through the Getting Started. The process was very easy and in no time, I was able to connect two Kafka sources provided by Materialize to my cluster via CLI, and create a materialized view that combines data from the two sources.
A simple visualization of the data with Metabase
Since the whole thing was a bit too cluttered for me, using the CLI, I set out to find a simple way to display the data so I could actually see the promised incrementally updated materialized view in action. I found what I was looking for on the Integrations Page in the Materialize Docs and decided to connect to Metabase, a business intelligence (BI) tool.
To do this, I downloaded Metabase from the website as a .jar and ran it locally. Then, all I had to do was call the Metabase instance on localhost:3000 and was able to very easily connect my Materialize cloud instance. Metabase automatically read all the views already present in Materialize and displayed them in a dashboard.
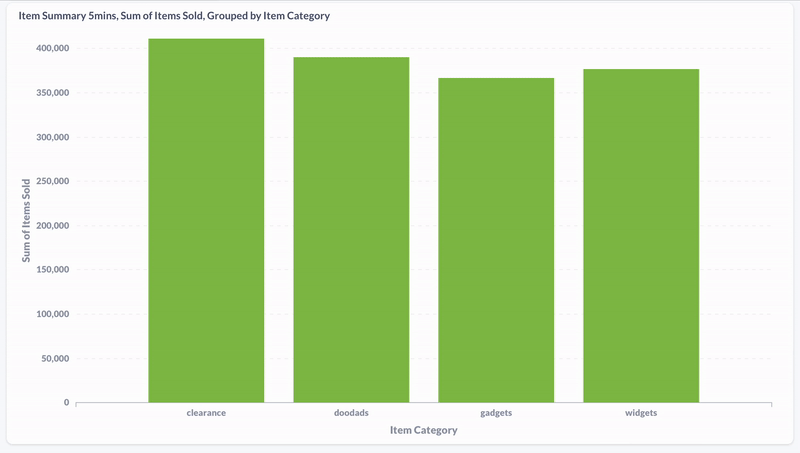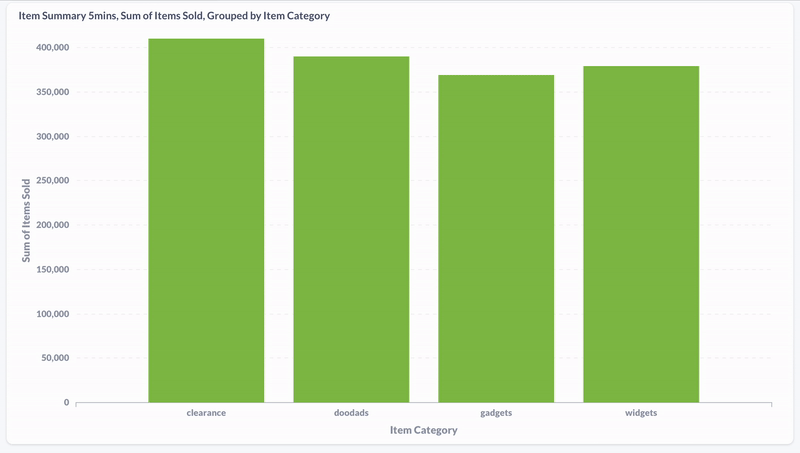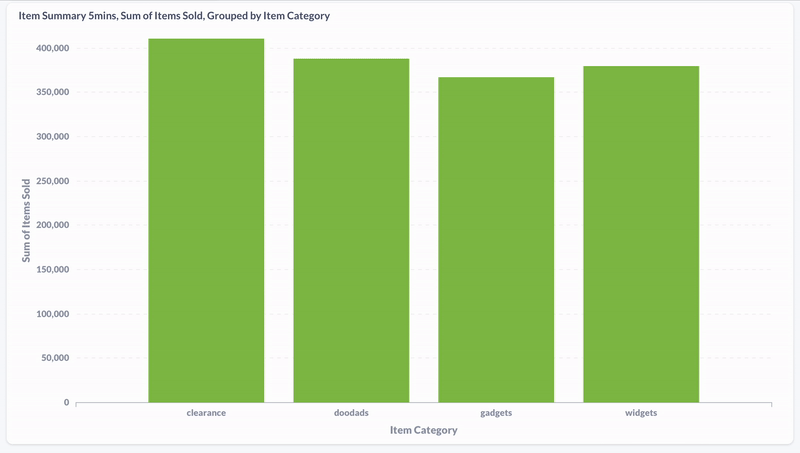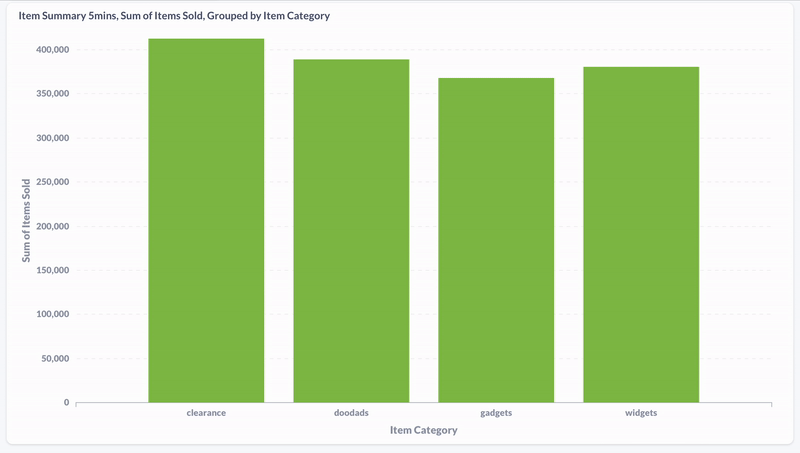
Here, I used Metabase to visualize the distribution of product purchases by category during the last five minutes. We can see that the data is updating in real time.
And here’s a screenshot of a materialized view showing the most recently purchased products in the past five minutes:
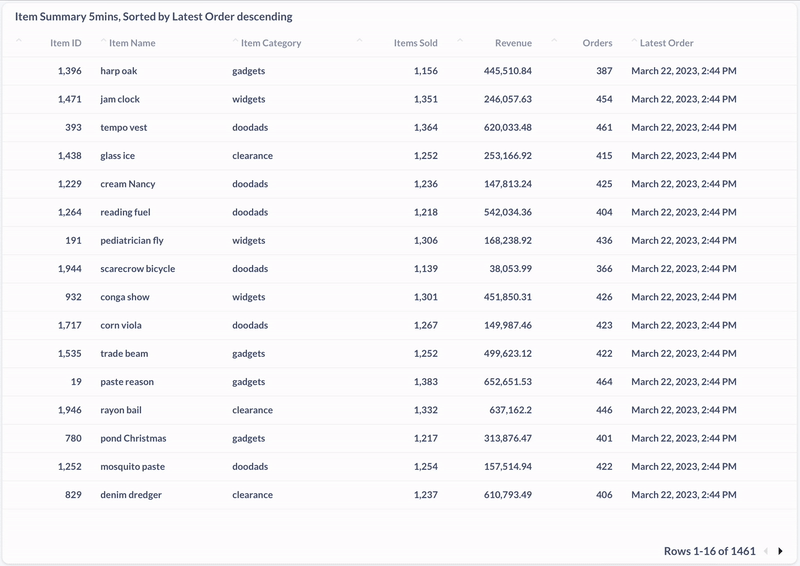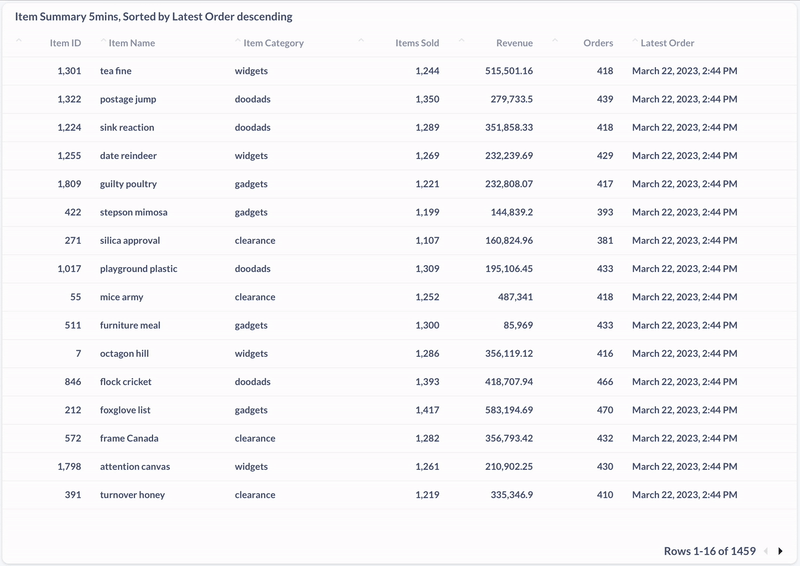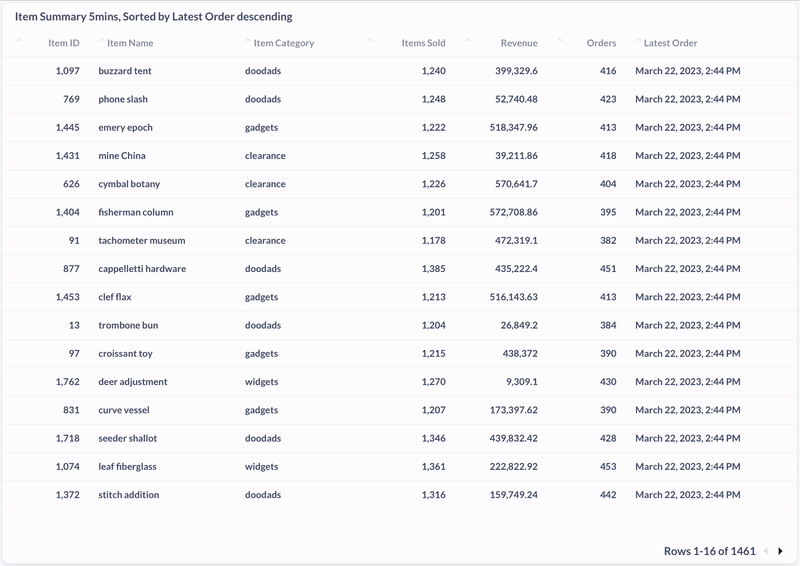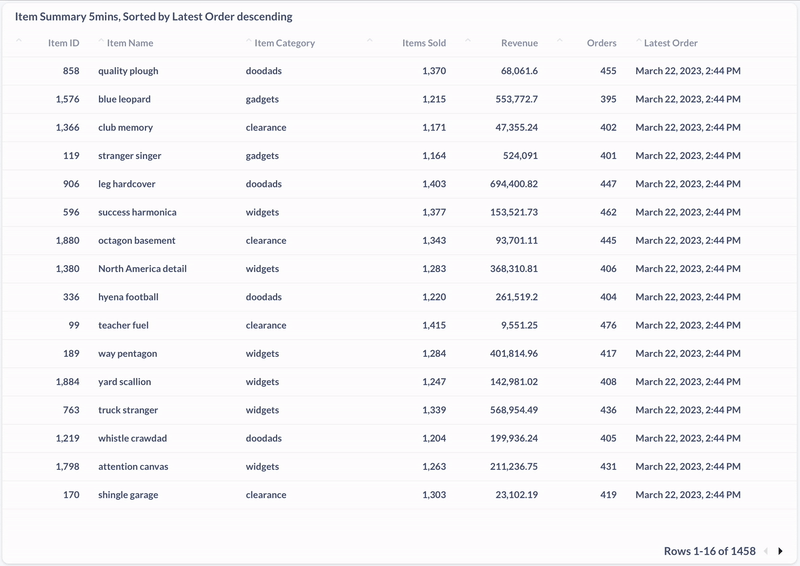
Conclusion
I really like the idea of fast and efficient processing of real-time data, and the use cases seem very versatile. The docs are well written and the community behind Materialize is very helpful, so much so that even McSherry himself answered one of my questions in their Slack channel. The relatively new SaaS version of Materialize works well and I look forward to follow the development of Materialize in the coming time. Stay tuned! 🚀