Apache Kafka is the first part of our blog series “Event-Driven Systems”. First, we lay the foundation for the further topic so that you know exactly what the use of Kafka will bring you.
Kafka was originally developed by LinkedIn before becoming part of the Apache Software Foundation in 2012. This is an open source project, which has been developed by the Confluent company since 2014. This company grew out of LinkedIn.
What is Kafka?
Apache describes Kafka as an event streaming platform that is comparable to the human nervous system. Since it should mainly be used wherever a service is running continuously. This happens mainly because the business is always shaped by automated software. With Kafka it is possible for you to read and manage data in real time from various event sources such as databases, mobile devices, cloud services or other software applications. This saves you from writing several different integrations between the different systems, because all of them can fall back on Kafka for this. For this reason, it is also possible for you to create a decentralized and resilient system.
What are the possibilities of using Kafka?
With Kafka it is possible for you to create microservices and other applications that offer the possibility of exchanging data with an extremely high throughput and a very low latency. Furthermore, Kafka is able to store the messages in an orderly manner and even use the collected messages to reproduce an application status that has already occurred. By using clusters, Kafka can be scaled horizontally very well. This means that, for example, the number of brokers can easily increase. And although very large amounts of data are quickly saved here, this has no effect on the speed of Kafka.
Kafka can also be used in a wide variety of areas. This includes:
- Event-driven architectures
- Event logging
- Tracking website activity
- Monitoring the operation of applications using various metrics
- Aggregation & Collection of logs
- Manage logs across distributed systems
Kafka concept
If you want to use Kafka, it is always an advantage to know the most important terms and the associated functions.
The basic structure starts with the Kafka cluster. This includes different broker instances.
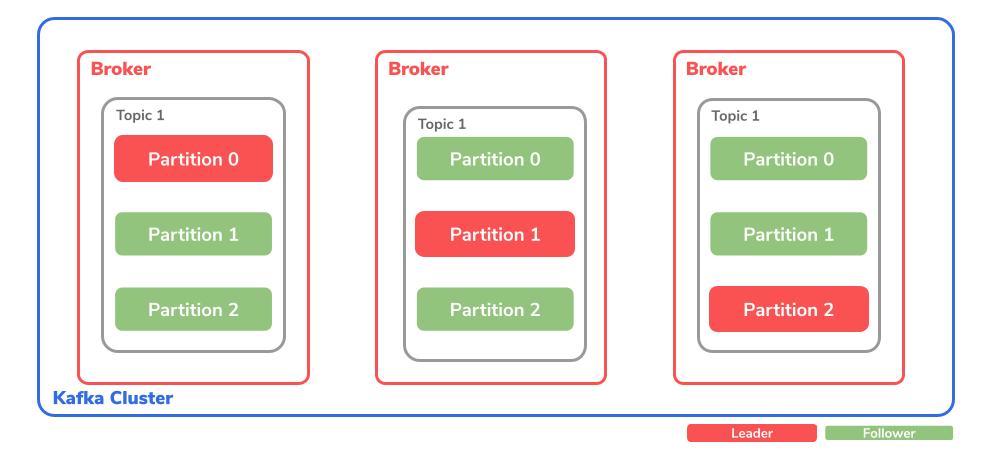
Broker
The broker is responsible for coordinating the storage process and forwarding the data. A broker is often referred to as a server or node.
Topic
The so-called topic, which receives data and stores it within a Kafka cluster, is located within the broker. This is divided into a self-configured number of partitions.
Partitions
This is the actual place where the messages are stored.
It is also possible to replicate the partitions over several topics in order to avoid data loss.
As already mentioned, the number of partitions is defined by the topic partition count itself.
In the case of partitions, a distinction is also made between leader and follower.
The partition leader is responsible for processing all producer requests of a topic.
The partition follower, on the other hand, replicates the leader’s data.
This can also be determined by the replication factor itself. It is also optionally possible for the follower to process consumer requests.
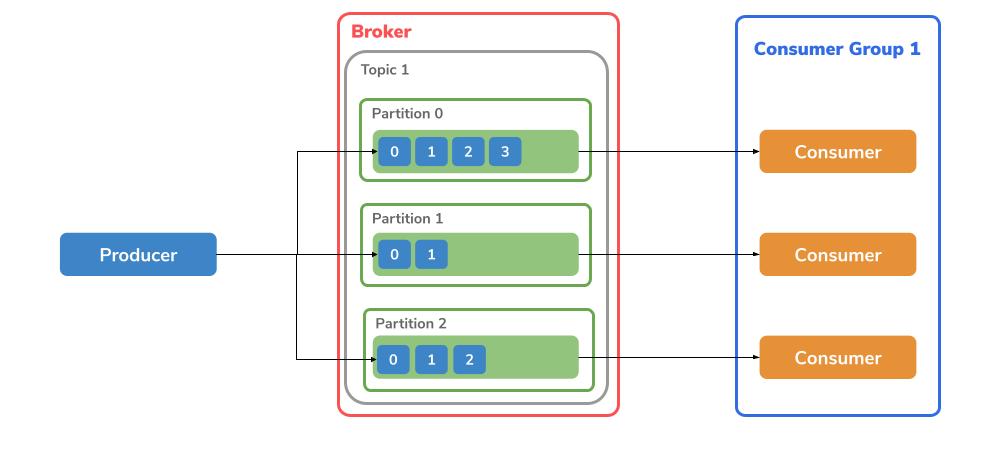
In order for Kafka to have data, someone needs to send the data and one of the data reads.
Messages
Messages are a technical transfer unit that Kafka manages. These messages consist of the following points:
- Timestamp: can be set by the producer himself or automatically by the broker
- Key: identifies the target partition
- Value: payload defined by the producer
- Header: contains further key-value pairs
Offset
The offset determines the position of a message within a partition. Each message has a unique offset. That is why it can be monitored at which position the consumer is and how many entries have been read so far.
Producer
The producer is responsible for the publish process. This means it sends messages to a broker topic. The sent message is always written after the last offset of a partition. If there are several partitions within a topic, either the Round-Robin principle is used or the key is used to decide which topic is to be written to.
Consumer
Where messages are stored, there must also be an opportunity to read the data.
This is done through a subscribe operation.
This means that a consumer ‘subscribes’ to a topic from which he can read the messages based on the partition and the offset.
Consumer Group
Consumers can be divided into groups using a group.id.
However, two consumers cannot read from the same Topic partition.
However, it is possible for a consumer to read from several partitions.
These are used to share large data streams that are generated by several producers.
Architecture
Now that we have looked at the basics of the Kafka Cluster, we now continue with the next parts, which complete Kafka.
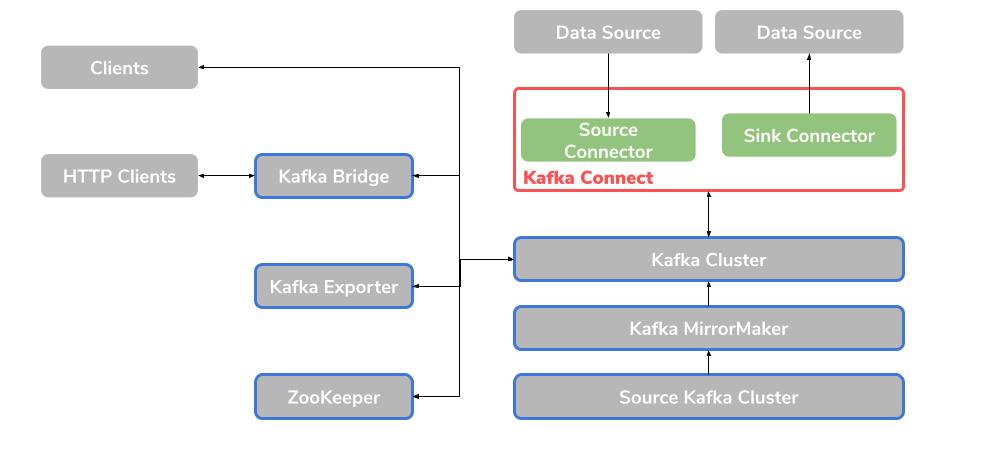
Apache ZooKeeper
ZooKeeper is a core dependency, which is itself from Apache. This is a cluster that contains replicated ZooKeeper instances. As a coordination service, ZooKeeper is responsible for tracking and storing the status of brokers and consumers. It also takes care of the leader election of the various partitions.
Kafka Connect
Apache offers an integration toolkit so that you can exchange data between Kafka brokers and other systems. You can do this with the help of so-called connector plugins. Kafka Connect provides a framework so that you can integrate Kafka into external data sources such as databases. The advantage here is that external data is translated and transformed directly into the appropriate format.
There is the Source Connector, which sends external data to Kafka. And there is also the Sink Connector, which extracts data from Kafka.
Kafka MirrorMaker
The MirrorMaker is responsible for ensuring that the data is replicated between two Kafka clusters. A distinction is made between a source Kafka cluster and a target Kafka cluster.
Kafka exporter
This enables you to extract data as Prometheus metrics for analysis purposes. This includes information about offsets, consumer groups, and consumer lags. The latter is the delay time between the last message within a partition and the message that is currently being fetched from this partition by a consumer.
Kafka Bridge
The Kafka Bridge offers an API for integrating HTTP-based clients into a Kafka cluster.
Kafka Bridge Interface
A RESTful interface is offered via the bridge so that HTTP-based clients can communicate with Kafka. This saves the clients having to translate the Kafka Protocol There are two main resources through the API, Consumers & Topics. These are made accessible from ‘outside’ via endpoints so that communication with consumers and producers within the Kafka cluster can take place.
HTTP requests
The following requests are made available:
- Send messages in a topic
- Received messages from a top
- Get a list of partitions from a topic
- Create & delete consumers
- Subscribing to topics in order to receive messages from them
- Get a list of topics to which a consumer subscribes
- Unsubscribe from topics
- Assign partitions to a consumer
The messages can either be sent in JSON format or in Binary format. This allows clients to create and read messages, produce & consume, without having to use the Kafka protocol.
Stay tuned!
This text was automatically translated with our golang markdown translator.