Neben Neuronalen Netzen ist die Verwendung von Entscheidungsbäumen eine weitere Möglichkeit, Schlüsse aus komplexen Daten mittels Machine Learning zu ziehen. Entscheidungsbäume sind eine Art Baumstruktur, die aus Knoten und Kanten besteht. An jedem Knoten wird eine Frage gestellt, deren Antwort entscheidet über welche Kante man dem Baum weiter folgt. Am Ende des Pfades steht dann ein Output, der die Entscheidung des Baumes darstellt.
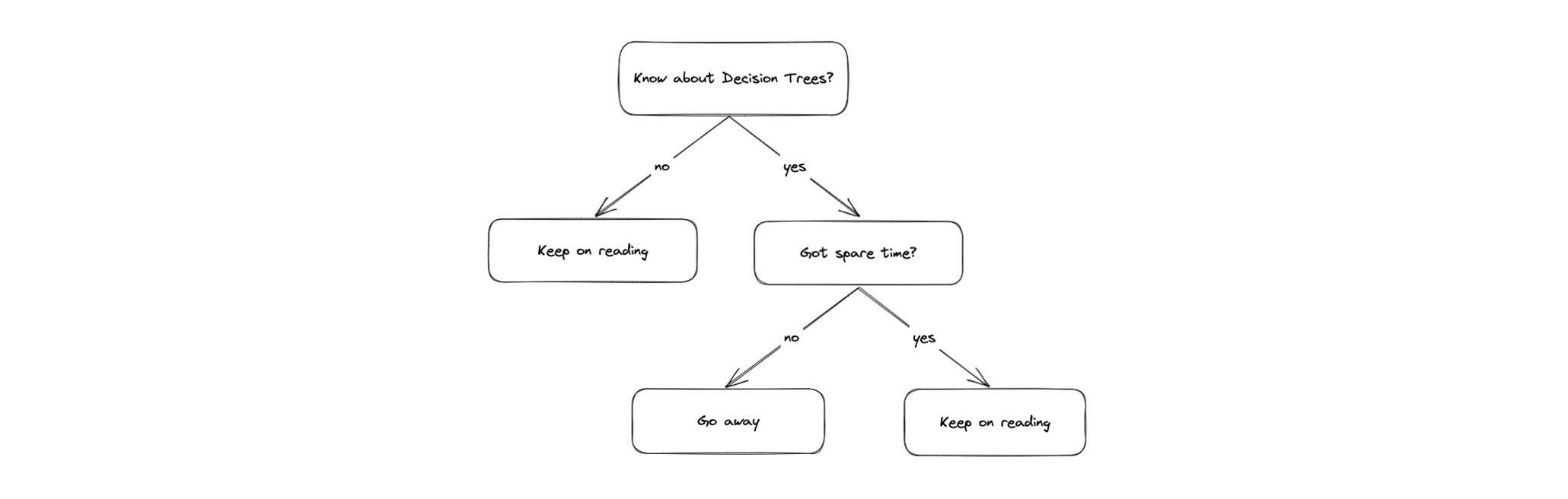
Figure: Beispielbaum
Entscheidungsbäume werden in der Regel in zwei Kategorien unterteilt: Klassifikationsbäume und Regressionsbäume. Klassifikationsbäume werden verwendet, wie der Name schon sagt, um Inputdaten im Hinblick auf spezifische Kategorien zu klassifizieren, während Regressionsbäume verwendet werden, um numerische Werte vorherzusagen.
Ein Beispiel zum Klassifikationsbaum
Ein Beispiel-Usecase für einen Klassifikationsbaum ist die Unterscheidung von Pflanzen nach ihrer Art. Merkmale wie die Wuchsgrösse, Blütenfarbe, Blütenform etc. können als Input verwendet werden, um einzelne Entscheidungen auf den Knoten des Baumes zu treffen, z.B. Anhand der Wuchsgrösse der Pflanze, und am Ende auf eine Kategorie zu kommen, in diesem Falle die Pflanzenart.
Ein Beispiel zum Regressionsbaum
Ein typisches Beispiel für einen Regressionsbaum ist die Vorhersage des Verkaufspreises eines Hauses. Merkmale wie die Anzahl Zimmer, die Grösse des Grundstücks, die Lage etc. können im Baum verwendet werden, um einzelne Entscheidungen zu treffen, und am Ende auf einen Preis zu kommen. Die möglichen Ausgänge sind hierbei nicht beschränkt auf spezifische Werte, sondern können beliebige numerische Werte annehmen.
Algorithmen
Es gibt diverse Algorithmen, um Entscheidungsbäume zu erstellen bzw. zu trainieren. In diesem TechUp werden wir uns zunächst den Algorithmus Random Forest anschauen, und im Anschluss anhand eines Beispiels einen Entscheidungsbaum erstellen sowie auf die Vor- und Nachteile von Decision Trees eingehen.
Random Forest
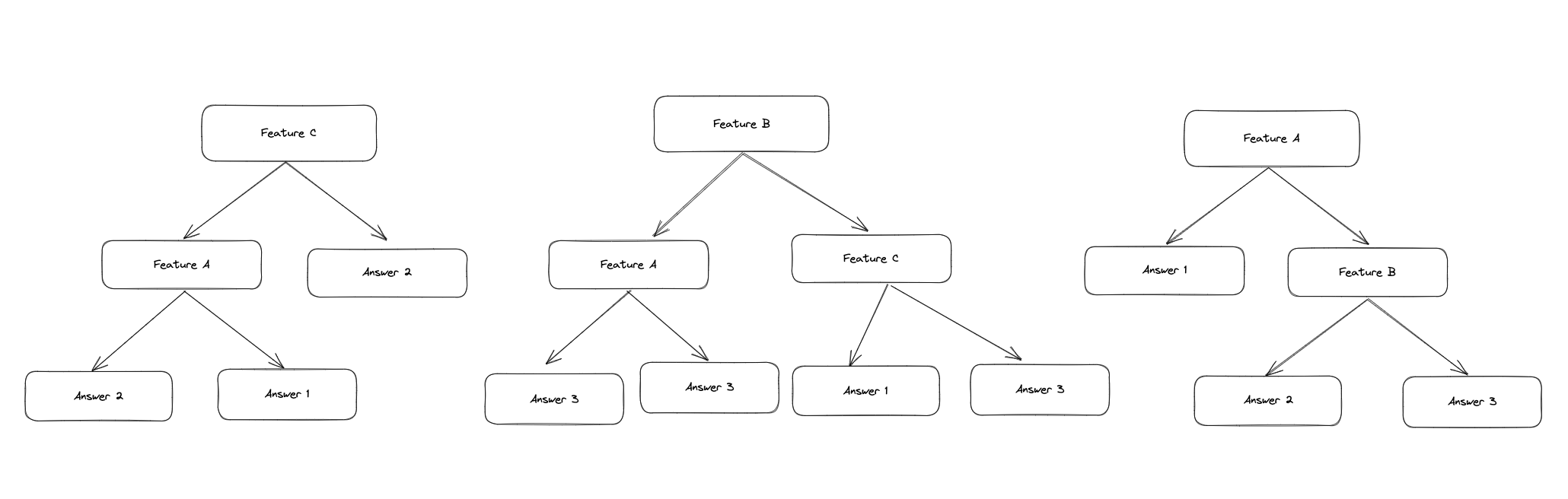
Der Random Forest Algorithmus ist ein Ensemble-Learning-Algorithmus, bei welchem mehrere Entscheidungsbäume unabhängig voneinander erstellt werden. Um von einem gegebenen Input auf eine Entscheidung zu kommen, werden die Entscheidungen der einzelnen Bäume kombiniert und zu einem Ouput zusammengefasst. Dieser Ansatz wird auch als Bagging (Bootstrap Aggregating) bezeichnet.
Der Vorteil und Hintergedanke bei diesem Vorgehen ist, dass die unterschiedlichen Bäume hierdurch Fehler der einzelnen Bäume ausgleichen können. Ein einzelner Baum kann durch zufällige Entscheidungen oder durch einen schlechten Input-Datensatz zu einem schlechten Output führen. Durch die Kombination mehrerer Bäume kann dieser Fehler ausgeglichen werden.
Um sicherzustellen, dass die Ergebnisse der einzelnen Bäume unabhängig voneinander sind und sich voneinander unterscheiden, werden die Bäume nicht alle mit dem gleichen bzw. kompletten Datensatz trainiert. Stattdessen wird jeder Baum anhand eines Subsets des kompletten Datensatzes trainiert.
Beim Aufbau eines Baumes wird an den einzelnen Knoten nicht anhand von allen Features, sondern anhand eines zufälligen Subsets der Features entschieden. Durch diese Vorgehensweise wird sichergestellt, dass die Bäume sich voneinander unterscheiden und unabhängig voneinander trainiert werden. Am Ende werden die Ergebnisse der Bäume zu einem Output zusammengefasst.
Ein einfaches Random Forest Beispiel
Das hört sich alles relativ komplex an. An einem Beispiel wird das ganze aber viel einfacher verständlich: In diesem Beispiel wollen wir anhand von einem Datensatz eine Pflanze klassifizieren und entscheiden, ob sie entweder ein Apfelbaum oder eine Tomatenpflanze ist. Der Datensatz besteht aus den Features Blattgrösse, Fruchtgrösse und Wuchshöhe. Es werden insgesamt 3 Bäume erstellt:
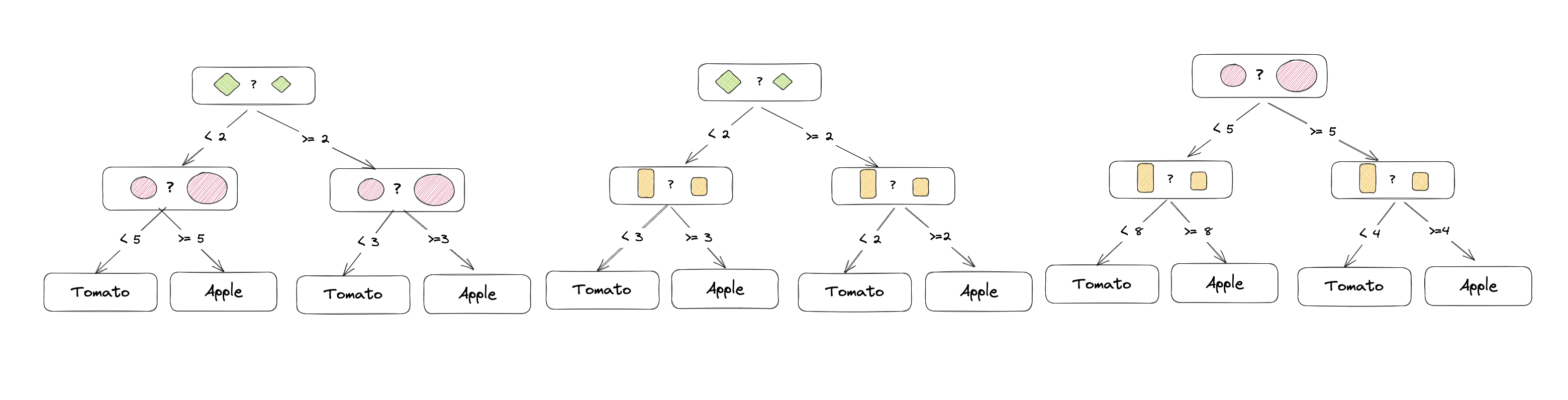
Der erste Baum unterscheidet anhand der Blatt- und Fruchtgrösse, der zweite anhand der Blatt- und Wuchshöhe und der dritte anhand der Frucht- und Wuchshöhe. Die Bäume werden unabhängig voneinander trainiert und die Ergebnisse zusammengefasst. Jeder Baum trifft dabei die Entscheidung, welche anhand der Features am besten passt.
Die Entscheidungen vom ersten Baum könnten wie folgt aussehen: Übersteigt die Blatt- und Fruchtgrösse eine bestimmte Grösse, ist es ein Apfelbaum, da die meisten Datenpunkte mit diesen Werten zu einem Apfelbaum gehören. Liegen die Werte darunter, ist es eine Tomatenpflanze, da die meisten Datenpunkte mit diesen Werten zu einer Tomatenpflanze gehören.
Möchte man nun eine Pflanze klassifizieren, werden die Werte für Blatt- und Fruchtgrösse an den ersten Baum übergeben. Der Baum entscheidet, ob es sich um einen Apfelbaum oder eine Tomatenpflanze handelt. Die Entscheidung des zweiten und dritten Baumes wird analog durchgeführt und die Ergebnisse werden zusammengefasst. Die Pflanze wird dann als Apfelbaum klassifiziert, wenn mindestens 2 der 3 Bäume die Pflanze als Apfelbaum klassifizieren.
Praktisches Beispiel: Überlebenswahrscheinlichkeit auf der Titanic
An einem praktischen Beispiel können wir sehen, wie Random Forests produktiv eingesetzt werden können. Als Datengrundlage nehmen wir den Titanic Datensatz von Kaggle (https://www.kaggle.com/c/titanic/data). Dieser Datensatz enthält verschiedene Informationen über die Passagiere der Titanic, welche im Jahr 1912 auf dem Weg nach Amerika sank. Die Aufgabe ist es, anhand der Daten zu entscheiden, ob ein Passagier überlebt hat oder nicht.
Wir werden, um das Beispiel einfach zu halten, keine gesonderten Features erstellen (Feature-Engineering), und auch nur ein paar der bereitgestellten Features verwenden. Folgende Features werden wir verwenden: Die Klasse, in der der Passagier reiste, das Alter und das Geschlecht.
Zunächst importieren wir die benötigten Bibliotheken und laden den Datensatz in ein pandas DataFrame:
|
|
Dann bereiten wir die Daten vor, indem wir die nicht benötigten Features entfernen und die Spalte mit dem Geschlecht in eine numerische Spalte umwandeln. Anschliessend extrahieren wir die Features und das Target aus dem DataFrame und teilen die Daten in einen Trainings- und Testdatensatz auf:
|
|
Wir verwenden den Random Forest Classifier aus der scikit-learn Bibliothek, welcher anhand von 50 Entscheidungsbäumen eine Entscheidung treffen soll (n_estimators). Den Classifier trainieren wir mit den Trainingsdaten und machen im Anschluss eine Vorhersage für die Testdaten. Zum Schluss evaluieren wir die Vorhersagegenauigkeit des Classifiers:
|
|
|
|
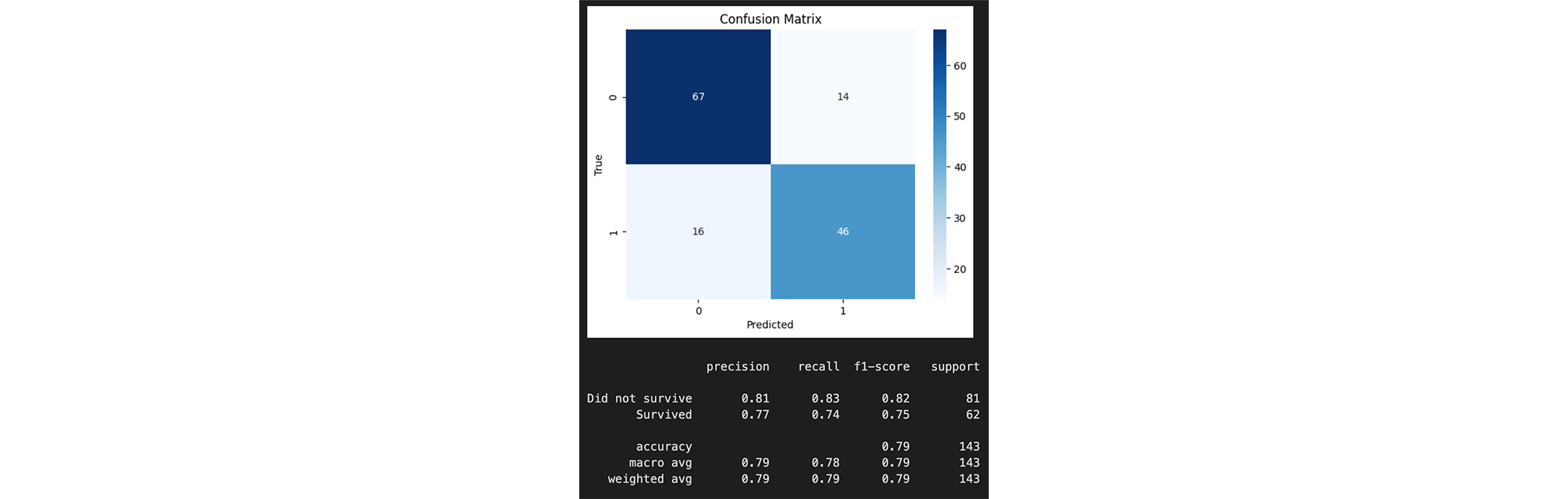
Die erreiche Vorhersagegenauigkeit liegt bei 0.79. Das heisst, dass der Classifier 79% der Passagiere korrekt klassifiziert hat. Dies ist nicht sonderlich hoch, da wir aber auch nur mit drei Features gearbeitet haben doch ein guter Wert.
Mittels einer Confusion Matrix können wir die Vorhersagegenauigkeit noch genauer analysieren:
|
|
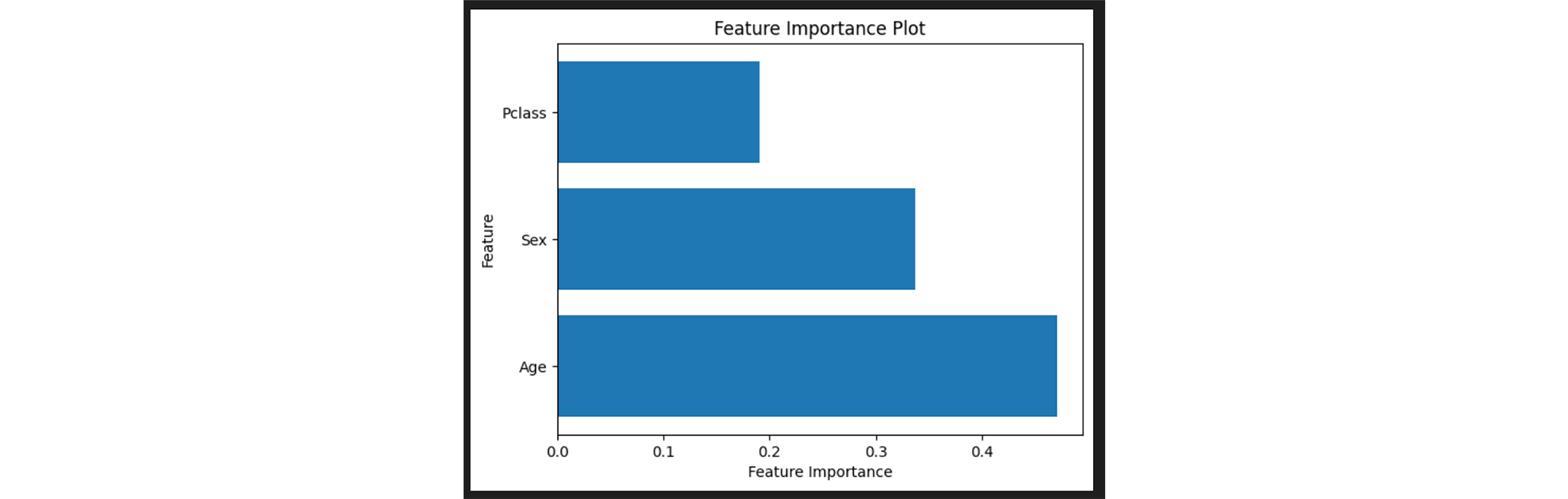
Um weitere Informationen über die einzelnen Features zu erhalten, können wir die Feature Importance ausgeben:
|
|
Fazit
Wie gezeigt lässt sich mit relativ wenig Aufwand schnell und einfach ein Random-Forest Classifier mit relativ guten Ergebnissen trainieren. Natürlich gibt es noch viel mehr Möglichkeiten, die Vorhersagegenauigkeit zu verbessern. Neben Hyperparameter Tuning, Feature Engineering, weiteren Features und besseren oder bereinigten Daten könnte die Vorhersagegenauigkeit sicherlich deutlich verbessert werden.
Wie man sieht, ist vor allem die Analysefähigkeit ein Aspekt, der den Random Forests Algorithmus und Entscheidungsbäume im Allgemeinen so interessant macht. Jede Entscheidung des Entscheidungsbaums genau verstehen und analysieren zu können ist ein riesen Vorteil beim erstellen, trainieren und Weiterentwickeln von Modellen.
Natürlich gibt es neben Random Forest noch weitere Algorithmen, um Klassifikationsprobleme wie dieses zu lösen. Beispiele wären Boosted Trees, Support Vector Machines, Logistic Regression, Neuronale Netze etc.. Jeder dieser Algorithmen hat natürlich seine eigenen Vor- und Nachteile, je nach Datengrundlage, Anwendungsfall und Zielsetzung, doch das werden Themen für folgende Artikel sein. Bleib dran! 🚀