Machine Learning mit Tensorflow
In meinem letzten TechUp ging es um die Grundlagen rund um das Thema Deep Learning. Dabei haben wir zentrale Konzepte und Begriffe kennengelernt. Heute gehen wir einen Schritt weiter und befassen uns mit dem Thema TensorFlow. Bei TensorFlow handelt es sich um eine “End-to-end open source machine learning platform”. Diese wurde ursprünglich von Google entwickelt, doch mittlerweile ist es unter einer Open-Source Lizenz verfügbar. Der Fokus liegt vor allem auf Spracherkennung und Bildverarbeitung. Dies ist möglich über lernende neuronale Netze.
Für das Verwenden von TensorFlow sind auf jeden Fall Grundlagen in den Bereichen Python, Machine Learning Konzepte und die Basics von Matrixrechnung zu empfehlen.
Setup 💻
Für das grundlegende Setup ist eine Installation von Python notwendig. Ob du die richtige Version nutzt, kannst du mit dem Kommando python3 --version prüfen. Dabei wird eine Version zwischen 3.7 und 3.10. empfohlen. Ebenfalls benötigst du den Python Packagemanager (pip) in der Version >19.0 ( oder >20.3 für macOS). Zusätzlich benötigst du am besten eine IDE, hier ist PyCharm von JetBrains zu empfehlen. Das kannst du hier runterladen.
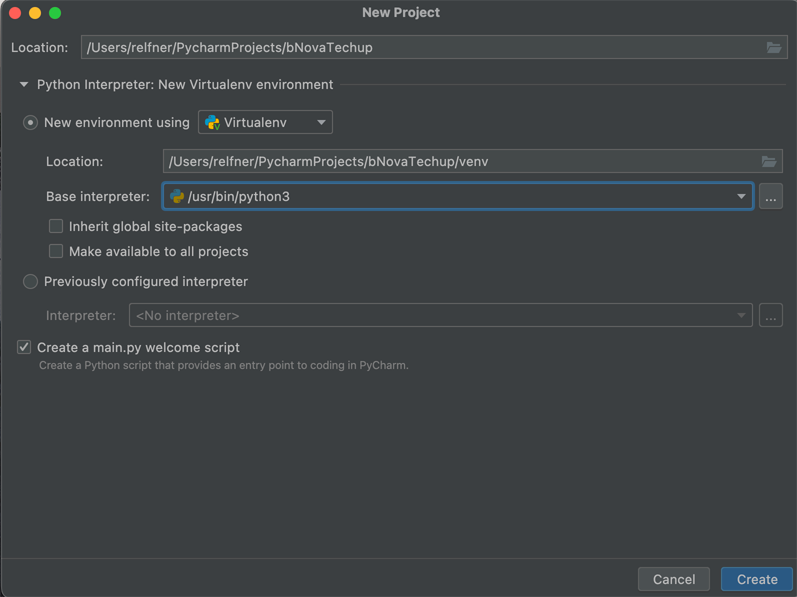
Anschliessend kannst du ein neues Projekt über PyCharm erstellen. Hier ist einfach zu beachten, dass du den gewünschten Namen angibst und die korrekte Python Version auswählst.
Sobald das Projekt aufgesetzt wurde, benötigst du ein File mit dem Namen requirements.txt, in dem du bestimmst, welche Versionen von den angegebenen Packages verwendet werden sollen. Innerhalb des Installations Guide von Tensorflow wird dies wie folgt beschrieben:
|
|
Die IDE zeigt dir anschliessend eine Meldung, damit du die Requirements installieren kannst. Wenn du diesen Weg nutzt, bekommst du diese Anzeige:
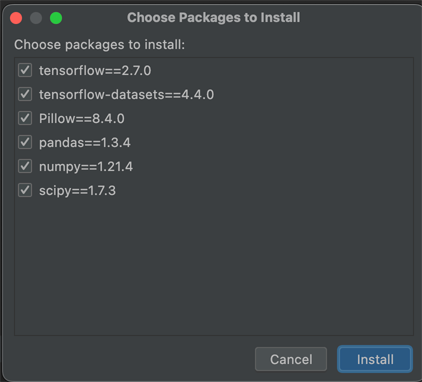
Sobald die Installation abgeschlossen ist, kannst du die Python Console öffnen.
Leider ist es in unserem Fall zu Fehlern mit dem M1 Prozessor gekommen. Aus diesem Grund haben wir eine andere Variante gewählt, um TensorFlow lokal zu nutzen. Hierfür war zunächst einmal eine Installation von Miniforge notwendig. Denn mit diesem ist es möglich, Python Packages zu installieren, welche Nativ für den Apple Silicon Chip kompiliert wurden.
|
|
Nach der Installation kannst du das standard Environment deaktivieren.
|
|
Für unser Beispiel haben wir eine virtuelle Umgebung mit der Python Version 3.8 erstellt. Wenn wenn diese erstellt wurde, muss sie noch aktiviert werden.
|
|
Nun kannst du damit beginnen, alle notwendigen Dependencies zu installieren. Dazu gehören als erstes alle TensorFlow Dependencies, bevor du weitere Requirements über pip für TensorFlow installierst.
|
|
Anschliessend solltest du auf dem gleichen Stand sein, wie über das Installieren innerhalb der IDE. Vorausgesetzt es gab keine Fehler. In unserem Fall haben wir anschliessend mittels jupyter notebook die Konsole innerhalb von Jupyter genutzt.
Nun müssen auf jeden Fall die folgenden Schritte ausführen:
import tensorflow as tf
Hier kann es passieren, dass du einige Warnungen angezeigt bekommst, wenn du ein GPU Setup auf deiner Maschine hast. Dies ist jedoch für unseren Fall nicht relevant.
Um zu prüfen ob es sich um die Korrekte Version handelt, kannst du die Version in der Konsole ausgeben: print(tf.__version__).
Dies sind alle notwendigen Imports:
|
|
Hands-on 🙏
Beispiel MNIST-Datenbank
Nun wollen wir als erstes Beispiel die MNIST-Datenbank verwenden, welche im Vergleich zu anderen Programmiersprachen als Hello-World-Programm verwendet wird. Dabei soll das Ziel sein, ein Machine Learning Model zu nutzen, welches handgeschriebene Ziffern erkennt.
Dafür legen wir zunächst ein neues Python File an und importieren alle notwendigen Libraries. Die restlichen Requirements wurden bereits über das Requirements File geladen. Mit dem Import von os ist es möglich, Environment-Variablen zu setzen, wie man anhand des Loglevels sehen kann.
Als dritter Schritt wird ein Main-Block erstellt, in den wir die Trainingsdaten aus der MNIST-Datenbank inklusive Infos laden. Die Trainingsdaten werden dabei als mnist_train definiert und die geladenen Informationen in der Variable info gespeichert. Zusätzlich müssen noch die Trainingsdaten geladen werden.
|
|
Sobald du dieses File ausführst, bekommst du in der Konsole folgenden Output.
|
|
Da du nun die Variable info defniert hast, kannst du sie in der Konsole einfach auslesen, in dem du sie aufrufst. Du kannst nun auch deine Trainingsdaten visualisieren lassen. Im Beispiel der MNIST-Datenbank handelt es sich um Bilder von Handgeschriebenen Zahlen. Dazu verwendest du diesen Befehl:
|
|
Sobald du diesen Befehl ausgeführt hast, bekommst du folgendes Bild angezeigt:

Nun benötigst du noch eine Methode, welche die Daten in die gewünschte Form bringt. In unserem Fall werden die Bilder als Pixelzahlen von 1 bis 255 dargestellt. Nutzt man jedoch Machine Learning, sollen sich die Daten am besten sich zwischen 0 und 1 befinden. Hierfür wird nun eine Map-Funktion verwendet, welche eine Lambda enthält. Dabei wird als Parameter einmal das Image übergeben, welches normalisiert werden soll und zusätzlich das Label. Dieses soll jedoch gleich bleiben. Damit man an Performance gewinnt werden die Daten in den Cache geladen, dies hat bei der Datenbank keinen grossen Einfluss auf das restliche System.
Handelt es sich bei dem Dataset um die Trainingsdaten, sollten die Zahlen durchgemixt werden. Anschliessend kann das Dataset wieder zurück gegeben werden.
|
|
Diese Methode kann vor dem Main-Block definiert werden. Sie kann im Anschluss innerhalb des Main-Blocks aufgerufen werden und der Variable neu zugewiesen werden.
|
|
Nun ist es noch notwendig, ein Modell zu erstellen. Hierfür wird eine neue Funktion mit dem Namen create_model erstellt. Hier kommt auch das erste mal Keras zum Einsatz. Dabei hat der erste Layer einen “Shape” von 28 Pixel x 28 Pixel x 1 Colorchannel. Mit der Funktion Flatten() wird der Layer zu einem einzelnen Layer. Dabei wird der Inhalt des Shapes multipliziert (28x28x1 = 784). Mit der Funktion Dense() wird das Model “gefüttert”, es erlernt die Beziehungen und findet heraus, wie die Daten zu klassifizieren sind.
Zum Schluss wird eine weitere Funktion aufgerufen, welche im nächsten Schritt erstellt wird.
|
|
Diese Funktion muss innerhalb des Main-Blocks aufgerufen werden:
|
|
Nun ist eine weitere Funktion für das Kompilieren des Modells notwendig, welche als Inputparamter definiert wird. Mit der Funktion compile() wird der Optimizer, die Loss-Funktion und die Metrics für weitere Information definiert.
|
|
Sobald auch diese Funktion fertig ist, kannst du dein Programm wieder ausführen. Dabei erhältst du als Output einige Informationen. Man kann sehen wie viele Paramter pro Layer verarbeitet werden und wie sich die Korrektheit pro Durchgang verbessert.
|
|
Um nun zu Prüfen, wie gut das Model angelernt wurde, kannst du die Testdaten aus dem ersten Schritt verwenden. Und die evaluate() Funktion nutzen. Dabei siehst du die Genauigkeit, die Erreicht wurde anhand von Daten, welches das Model quasi noch nicht gekannt hat.
|
|
Wenn du deine Arbeit nun speichern willst, kannst du dies mit model.save('mnist.h5') machen. Innerhalb deines Projekts wirst du nun diese Datei finden.
Beispiel Online Daten
Wenn du ein Modell mit Daten aus dem Internet nutzen möchtest, gibt es das Machine Learning Repository. Das meistverwendete Datenset is dabei das Iris Dataset.
Hierfür benötigst du zunächst einmal eine Funktion, welche die entsprechenden Daten aus dem Internet lädt. Dazu benötigst du die entsprechende Url und der gewünschte Speicherort muss definiert werden.
|
|
Innerhalb eines Main-Block kann diese Funktion nun aufgerufen werden, damit die Daten geladen werden.
|
|
Sobald du das File zum ersten Mal ausgeführt hast, stehen dir die Daten zur Verfügung. Hier ist es auf jeden Fall zu Empfehlen, sich die Daten für das Model zuerst anzuschauen, um zuprüfen, ob diese dem gewünschten Format entsprechen, oder ob sie erst noch angepasst werden müssen.
|
|
In diesem Fall fehlen uns die Namen der Spalten. Deshalb musst du diese noch hinzufügen, damit die Daten zugeordnet werden können. Dafür legst du zunächst einmal ein Array mit dem entsprechenden Namen an. Anstatt von Namen sollen Zahlen verwendet werden, damit das Model besser damit umgehen kann. Hierfür legen wir eine Map an welche die entsprechenden Arten einer Nummer zu weisen.
|
|
Innerhalb des Main Blocks kann nun auch diese Funktion aufgerufen werden iris_data = parse_iris_data(iris_filepath). Um dein Ergebnis zu prüfen, kannst du die Anzahl der “Spezien” vergleichen. Hier sollten überall 50 Stück zur Verfügung stehen.
|
|
Zum Schluss müssen die Daten in ein TensorFlow-Dataset geladen werden. Hierfür erstellst du nun eine weitere Funktion. Um dieses Set zu definieren, musst du zunächst einmal die Features bestimmen. Diese entsprechen den Spaltennamen. In diesem Beispielfall kann hier direkt iris_columsn verwendet werden. Anschliessend müssen die Labels auch aus dem dataframe ausgelesen werden.
|
|
Auch diese Funktion muss in dem Main-Block wieder aufgerufen werden.
|
|
Das Endresultat würde nun so aussehen:
|
|
Sobald dieser Code ausgeführt wird, werden die entsprechenden Daten heruntergeladen, aufbereitet und in das Dateset geladen.
Fazit ✨
In diesem TechUp konnten wir einen Schritt weiter gehen, da wir bereits letztes Mal die Grundlagen für das Thema gelegt haben. Deshalb haben wir uns heute dem Praxisteil gewidmet und dabei die bekannteste Datenbank im Bereich Machine Learning genutzt. Des Weiteren konnten wir zeigen, wie leicht man mit der Hilfe von TensorFlow ein ML Model erstellen und es auch direkt trainieren und testen kann. Ebenfalls konnten wir einen Schritt weiter gehen und Daten aus dem Internet nutzen. Dadurch ist es uns nun möglich, bereits vorhandene Daten zu verwenden, da man hier sehr viel Zeit sparen kann, wenn man keine eigene Datenerhebung durchführen muss. Man muss aber an diesem Punkt auf jeden Fall sagen, dass es sich hier um sehr einfache Grundlagen im Bereich von TensorFlow handelt. Somit gibt es in diesem Bereich noch viele weitere spannende Themen, die wir uns anschauen werden.
Bleib dran! 🚀