One of the most important tech developments of the last ten years was the containerization. That made it possible to run entire application environments in one container.
Kubernetes is the most widespread and by far the best-known solution for orchestrating containers. Is there because an alternative to Kubernetes at all? Yes, HashiCorps Nomad may be the only alternative to Kubernetes. What distinguishes Nomad, or rather, what makes Nomad different? Exactly two things:
-
Just like the UNIX philosophy: Do one thing and do it well.
-
Flexibility regarding containerized and non-containerized applications
Come on board with us and let’s see together what Nomad can do and why you might prefer Nomad over Kubernetes!
Everything looks like a nail with a hammer

Source: https://atodorov.me/2021/02/27/why-you-should-take-a-look-at-nomad-before-jumping-on-kubernetes/ (03.11.2021)
Kubernetes, as the most common solution for container orchestration, also has lesser known limitations. Kubernetes 5,000 nodes with 300,000 containers vs. Nomad with successful real tests of 10,000 nodes and up to 2 million Containers. See ‘The Two Million Container for this Challenge’ (https://www.hashicorp.com/c2m). There were 2,000,000 Docker containers successfully rolled out on 6,100 hosts in 10 different AWS regions in a time frame of 22 minutes.
There are already numerous Nomad users of which well-known companies such as Cloudflare, CircleCI, SAP, eBay or the well-known Internet Archives count.
Workload orchestration with Nomad
Nomad scores with its very own advantages, which Kubernetes does not necessarily guarantee in this form. You can underneath note the following points:
-
Deployment of containers, legacy applications and other workload types
-
Simple and reliable
-
device plug-in and GPU support
-
Federation of multi-regions and multi-cloud
-
Proven scalability
-
HashiCorp ecosystem
The Nomad architecture
Just like with Kubernetes or similar far-reaching software solutions, Nomad comes with its own understanding of Orchestration architecture, as well as the associated glossary with.
Perhaps having preceded all other explanations, Nomad is a single binary. This binary can optionally be on a host as a process, each as a client or server (we will describe that soon) or as command-line interface to be executed by the end user.
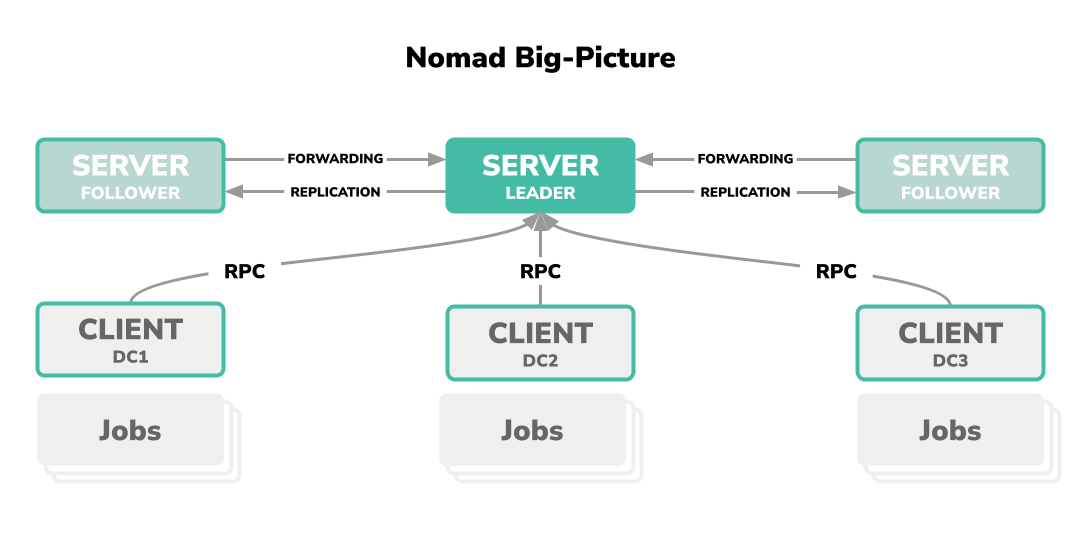
-
Server (s): Nomad Server is a network of at least 3 server units on which a Nomad agent in server mode running as a process. The latter is always the leader in the network and has the authority to interpret the cluster. These Order corresponds to Consesus Protocol and is based on the Raft consensus algorithm.
-
Client (s): Nomad clients is a network of a large number of individual client units on which a nomad agent runs as a process in client mode. The client serves as the target system when workload through the server network needs to be orchestrated. On a client, the workload is called a job in the Nomad glossary.
-
Job: A job is a specification that has been declared by the end user and is assigned as a workload to a client unit to be orchestrated and rolled out.
job specification
The job is primarily a specification that is declared once by the user. Within a job there is a group, which in turn can contain one or more tasks. The hierarchy can be summarized as follows:
|
|
Job, Group and Task are defined in Nomad jargon as follows:
-
Job: The workload as a declarative specification.
-
Group: Also called Task Group, is a collection of tasks that have to be carried out together and are part of a job.
-
Task: Is the smallest unit of work in Nomad. Tasks are carried out by the driver and can have different types of operations that can be performed.
-
Driver: Also called Task Driver, defines what exactly is required for execution. A well-known task driver would be the Docker container solution.
Task Driver
Nomad officially supports the following task drivers:
- Docker
- Isolated execution (exec)
- Raw Execution (raw exec)
- JVM
- Podman
- QEMU virtualization
In addition, there are task drivers supervised by the Community, which offer the following runtimes, among others:
- containerd
- Firecracker
- LXC
- WebAssembly
- FreeBSD Jail
- Rooktout
- Singularity (Container Platform)
- systemd-nspawn
- Windows IIS
- AWS ECS as remote target
A full listing can be found in the official documentation under https://www.nomadproject.io/docs/drivers.
Example declaration of a nomad job
Here we see an exemplary specification of a Jobs with the name docs with which a web frontend using a
Docker image hashicorp/web-frontend is executed as a task and can be made available.
|
|
One more word about HCL
The manifestos we saw earlier are all written in a relatively unknown format: HCL.
HCL is an acronym for HashiCorp Configuration Language and is an
in-house standard, which HashiCorp’s
product range is using.
HCL is a JSON-related format and is understood by HashiCorp as a continuation of JSON. As native syntax, HCL should be machine-friendly as well as human-friendly and be able to be read efficiently by both. Further information and specifications can be found in the official GitHub repo hashicorp/hcl.
HashiCorp stack
HashiCorp is a San Francisco-based company founded in 2012 by eponymous Mitchell Hashimoto and Armon Dadgar. This Silicon Valley company offers and has software solutions in the field of cloud computing made a name for themselves with their relatively well-known infrastructure-as-code product Terraform.
In addition to Terraform, Hashicorp has other solutions at the start and actually offers separate partial solutions that each cover a sub-area of the cloud infrastructure, but when combined they create an overall solution for a fully-fledged cloud environment. This is exactly what the HashiCorp stack means: rolling out and operating a complete cloud infrastructure. A complete listing of these sub-components and products from HashiCorp can be summarized as follows:
- Terraform: Automation of the provisioning of an infrastructure on a cloud and / or service provider based on the Infrastructure-as-Code principle.
- Packer: Build machine images as containers with a single source configuration file.
- Vagrant: Provision of reproducible development environments using virtualization.
- Consul: Implementation of a classic service mesh and DNS-based service discovery.
- Vault: Provision of secrets management, encryption of application data and other security mechanisms.
- Boundary: Provision of a platform for identity-based access.
- Waypoint: Abstraction layer for the one complete pipeline (Build&Deploy) on different platforms such as Kubernetes or AWS ECS.
- Nomad: The orchestration tool discussed here for workloads of all kinds.
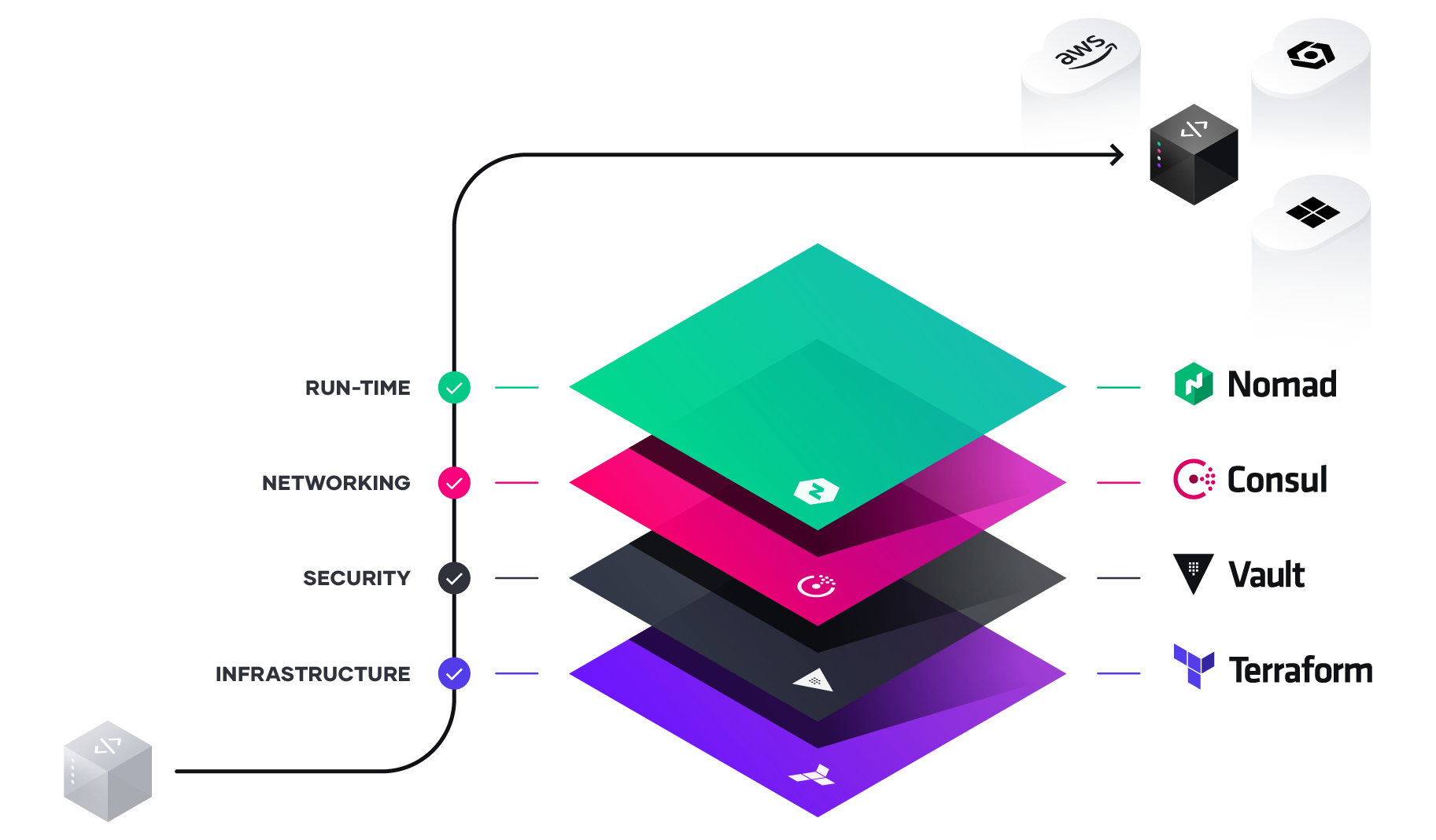
Source: https://www.hashicorp.com/resources/unlocking-the-cloud-operating-model-with-microsoft-azure (03.11.2021)
HashiCorp Cloud Platform
There is also an in-house cloud platform with which you can have the partial solution hosted by HashiCorp yourself: That is the HashiCorp Cloud Platform, or HCP for short.
In the current version, (yet) not all products are offered as a service, but it can be assumed that all own products are offered in the long term. There is currently no offer for HashiCorps Nomad available. Thus, Nomad still has to be hosted on a cloud-based environment such as AWS ECS or on bare metals.
Practical basic course with Nomad
Installation on macOS:
|
|
To start a local instance of Nomad, simply run the following command:
|
|
Check the status of the Nomad instance as follows:
|
|
By calling up the members of the server, we can see that the agent is actually running in server mode and as a leader part of the Gossip Protocol is:
|
|
Now we can define our first job for the nomad cluster. The Nomad CLI offers a useful command for this.
Let’s quickly switch to the /tmp \ directory and execute nomad job init.
|
|
This generates a sample job for us in the local directory with the file name example.nomad. If we inspect the file
with less or cat we get the following to see:
|
|
If you ran the job init \ command exactly as it is above, you will get much more output and comment lines in your example. You can get a shortened output like mine with the -short flag, so only parts that are significant for nomads are generated.
The job is quite clear and declares a job with the name example, in it a group with the name cache, as well as - as the smallest unit of a nomad job definition - a task with the name redis, which the Docker image redis:3.2.
A port is also defined, as well as a resource specification for CPU and memory.
It is important to note here that a docker \ driver is explicitly declared. As already mentioned at the beginning,
Nomad can orchestrate not just Docker images, but a whole range of workloads. But here we stay
a classic Docker image. So far so good.
Now we roll out the job. It’s easy as follows:
|
|
After the image has been pulled and rolled out, we check the status of all existing jobs:
|
|
As well as specifically of the job with the ID example:
|
|
In my case the job has an allocation with the ID 0c88d2ef. With this I can check other conditions.
|
|
Or the logs of the job with the same allocation ID:
|
|
As with Kubernetes, Nomad also has a graphical user interface. This runs under the port and can be used with can be called up via the following link.

Under jobs we can take a closer look at our example workload.
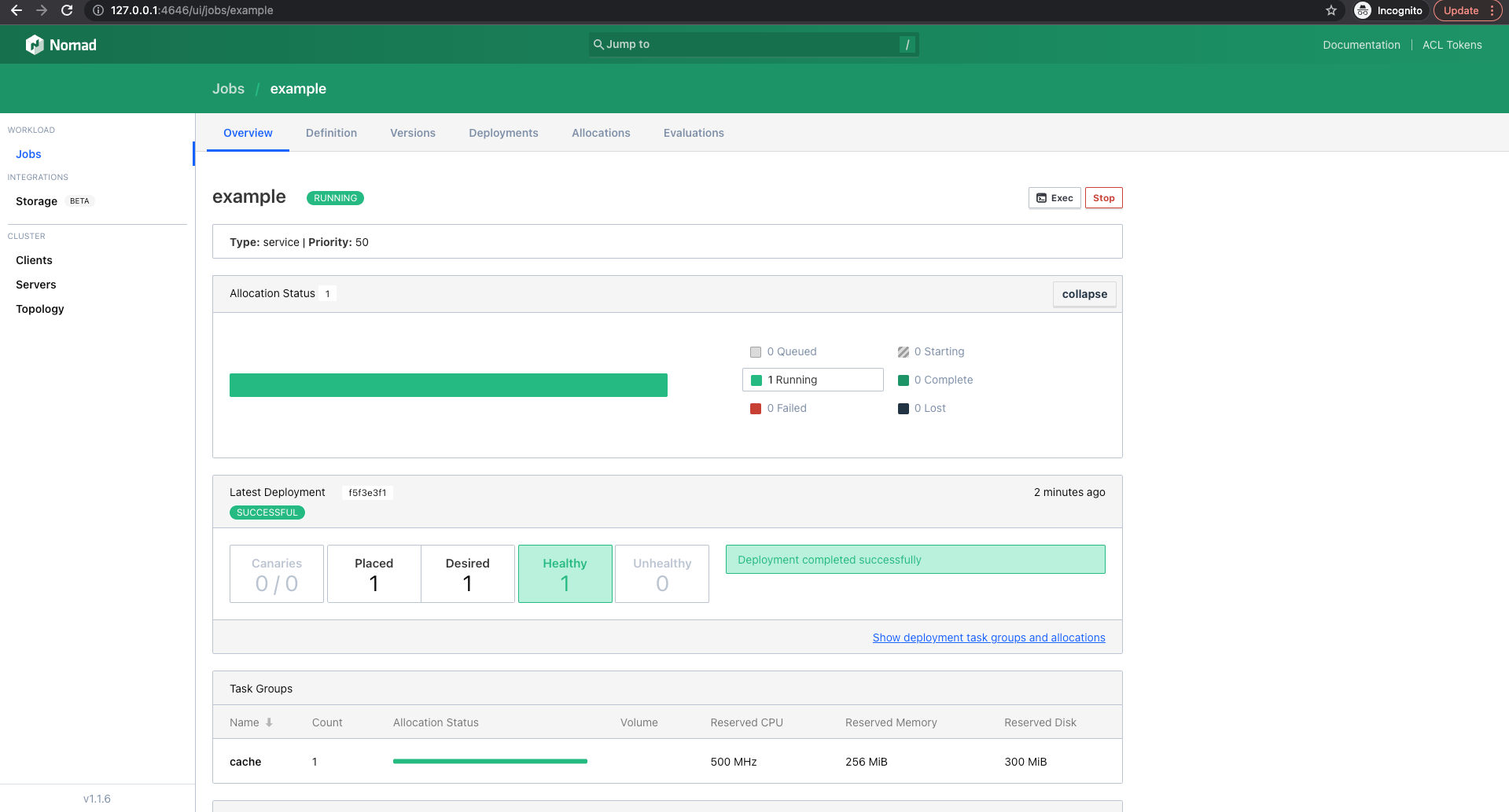
Conclusion
Nomad made a good impression on us. It is neither the size nor the mass of a Kubernetes, but shines with its minimalism with flexibility and efficiency. Nomad can’t do everything, but what it can it does well. In our assessment, Nomad is suitable in specific use cases where Kubernetes would be too big and too sluggish. That involves small development teams or the need for some flexibility in using application environments - where a container may not necessarily be the shortest route to the destination - to want to have.
Another use case is certainly the fact that Nomad can directly access GPU performance and thus workloads which will be interesting on applications relying on GPU. This includes, for example, applications such as machine learning, cryptocurrency mining or in general resource-intensive scientific computing.
At b-nova we don’t use Nomad, but we think Nomad is best for small startup teams, SMEs can be used in general or in very specific niche areas. Most of the other cases, Kubernetes certainly the better solution. If you need advice and support with Nomad, Kubernetes or in general in container and cloud environment, we are at your disposal at any time. Stay tuned!
Further links and resources
https://learn.hashicorp.com/nomad
https://learn.hashicorp.com/collections/nomad/get-started
https://www.hashicorp.com/blog/a-kubernetes-user-s-guide-to-hashicorp-nomad
https://atodorov.me/2021/02/27/why-you-should-take-a-look-at-nomad-before-jumping-on-kubernetes/
https://endler.dev/2019/maybe-you-dont-need-kubernetes/
https://medium.com/hashicorp-engineering/hashicorp-nomad-from-zero-to-wow-1615345aa539
https://aws.amazon.com/quickstart/architecture/nomad/
https://manicminer.io/posts/getting-started-with-hashicorp-nomad/
This text was automatically translated with our golang markdown translator.