This week we would like to deal with the topic of Artificial Intelligence, Machine Learning & Deep Learning. I’ll explain the basics of these important technologies, which are used in a wide variety of areas. Have fun! 😄
Deep Learning
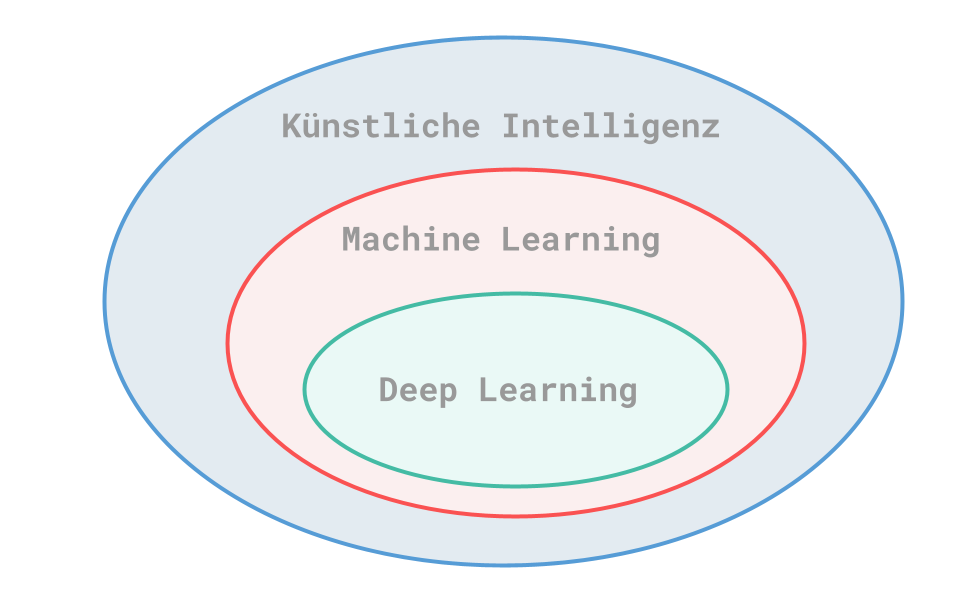
Artificial Intelligence
The topic of AI has been around as early as in the 1950s, when computer scientists at the time wondered whether it was possible to automate mental tasks that are normally performed by humans. Artificial intelligence includes the following two areas of machine learning and deep learning.
The first application of an AI was a chess game. For this purpose, programmers specified a set of rules to solve the “task”. This led to the idea that you can bring an AI to a human level by specifying a sufficiently large set of rules. This approach was followed until about the late 1980s and is known as symbolic AI. However, it quickly became apparent that this was not sufficient for more complex tasks. An example would be image recognition or the translation of foreign languages. This fact gave rise to the next subject area: Machine Learning.
Machine Learning
The publication of Alan Turing’s work “Computing Machinery and Intelligence” brought a decisive turn in the concepts surrounding the topic of artificial intelligence. With the so-called “Lady Lovelace Objection” he came to the conclusion that general-purpose computers are capable of self-learning. The Lady Lovelace Objection is Turing’s counter-thesis to a statement made by Lady Ada Lovelace in 1843: At the time, she said about the Analytical Engine, which was invented by Charles Babbage, that it did not aim to create something new.
This gave rise to the fundamental question of machine learning: Can a computer not only make decisions based on given rules, but perhaps also learn independently using data?
There are differences between the classic programming paradigm and that of machine learning: With the classic principle, data and rules are specified as input to the application. Responses are then created from these input parameters. With the principle of ML, data and the associated answers are given instead. The rules that lead to the result should be recognized from this. These learned rules can then be applied to new data.
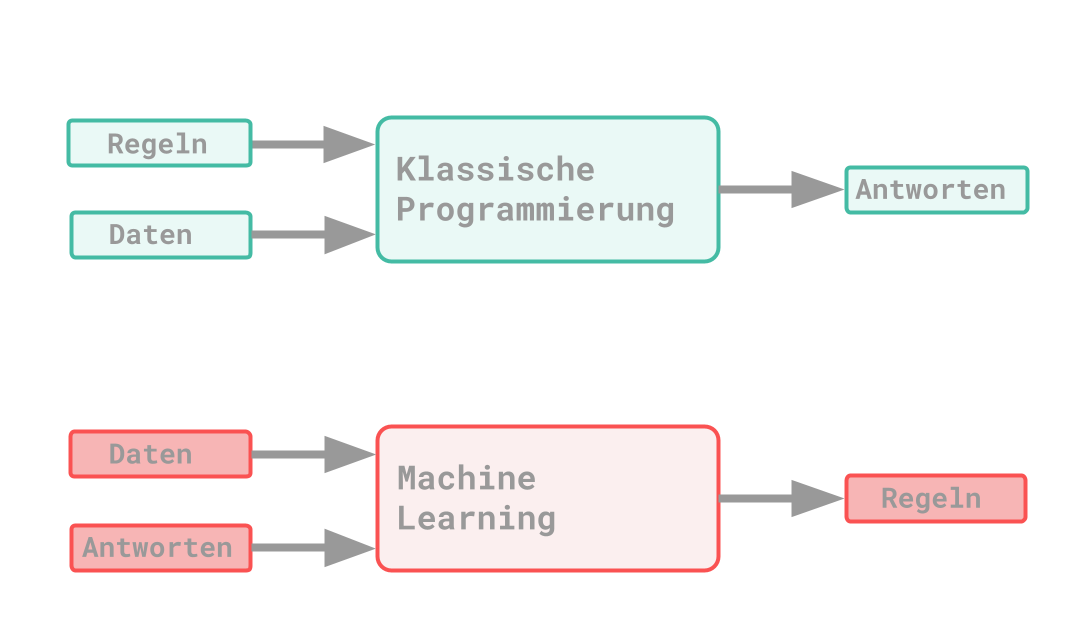
Compared to classic programming, it is more of a training process. ML is also related to mathematical statistics. A big difference is that with ML, a very large amount of data has to be processed.
Representations
Various transformations have to be made during the learning process of the ML algorithm. A representation must be chosen that represents the data in a better way. Using these representations, better rules can be found. Put simply, ML is a search for the best representation of the input data.
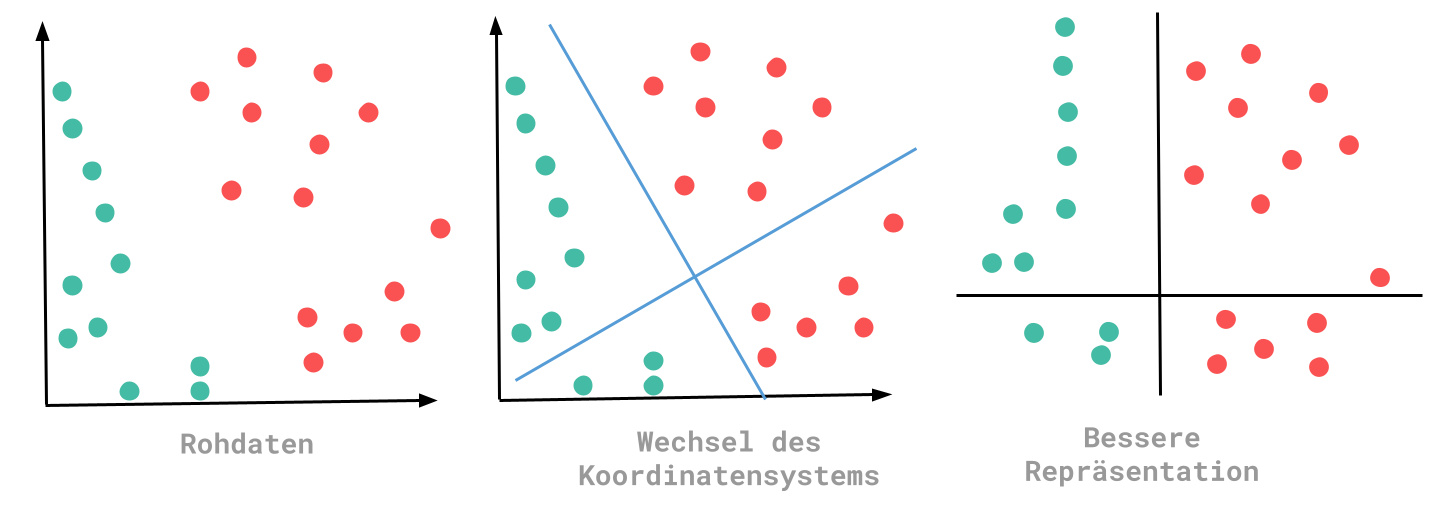
In this example, the changed representation allows the conclusion that all points that are less than zero have the color green. With the raw data, such a statement was difficult to define.
Deep Learning
Deep learning is an ML approach. Basically, according to the previous findings, three components are always necessary: input data, results and way to check the results. With the data and the ML algorithm, more and more suitable representations are to be found across several layers. Thus, the deep actually only means that several layers of representation are created or worked through. This describes the depth of a model. In deep learning, the various representations are learned by a neural network (a model). The lower the value of the loss function, the more accurate the results on the target values. The neural network is being trained. The loss value describes the deviation between the output and the desired result.
Application examples:
-
Image identification
-
Speech Recognition
-
Handwritten Letters Recognition
-
Translation
-
Digital Assistants
💡 Deep learning is not the only existing algorithm. Other examples would be the naive Bayes classifier or logistic regression.
A major breakthrough was achieved in a 2012 competition; In the competition, 1.5 million images have to be automatically assigned to 1000 different categories. At that time, an improvement in the correct classification rate of 12% was achieved (86,3%). For the recognition in that competition, “Deep Convolutional Neural Networks” were used, which have been used since then. Since 2015, the contest counts as solved with a rate of 96.4%.
The biggest advantage of deep learning is that the creation of characteristics, i.e. the creation of layers to represent data, happens automatically. Deep learning also depends on the hardware used, data volumes, benchmarks and algorithms.
Neural networks
If you deal with the topic of neural networks, you will often stumble across the following terms:
- NIST: National Institute of Standard and Technology. (MNIST: +modified)
- MNIST database: A classic data collection with training & test images. Comparable to Hello World programs in programming languages.
- Classes: Describes categories.
- Samples: These are data points.
- Label / Class Designation: This determines the class belonging to the sample.
Tensor
This is a container for data, numbers in most cases. Tensors are a generalization of matrices. When talking about tensors, the term dimension often comes up, which defines the axis. Incidentally, Tensor is also the namesake for TensorFlow.
If the tensor contains only one number, it is called a scalar (zero-dimensional tensor). However, if you have an array of numbers, it is a vector (1D tensor). Another variant are 2D tensors, which are called matrices. This name also remains regardless of whether more dimensions are added. Usually one finds 0D tensors to 4D tensors. Important attributes for tensors are the number of axes, the “shape” and the data type.
Practical examples
-
Vector Data
- (100000, 3) → 100,000 people with 3 pieces of personal information
-
Time series or sequential data
- (100000, 280, 128) → 100,000 tweets with a character length of 280 and 128 different characters
-
Image data
- (128, 256, 256, 3) → 128 color images, size of 256 x 256 and information about the color depth
-
Video data
- (4, 240, 144, 3) → 4 videos, 240 frames, size of 144 x 256 and information about the color depth
It is also important to know that there are tensor operations which form the basis of a neural network. In a normal computer program, these would be comparable to binary operations (AND, OR, XOR, …). Since tensors can be viewed as coordinates in a coordinate system, tensor operations can also be interpreted geometrically. Therefore, in simplified terms, one can say that a neural network is a very complex geometric transformation.
Loss functions
The loss function describes how good a neural network is at accomplishing a task. The function itself calculates the value that evaluates the training data. The lower this value is, the more accurate the result.
Optimizer
The optimizer determines how the weight is adjusted based on the loss score. This process is automated so that the neural network learns itself.
Construction
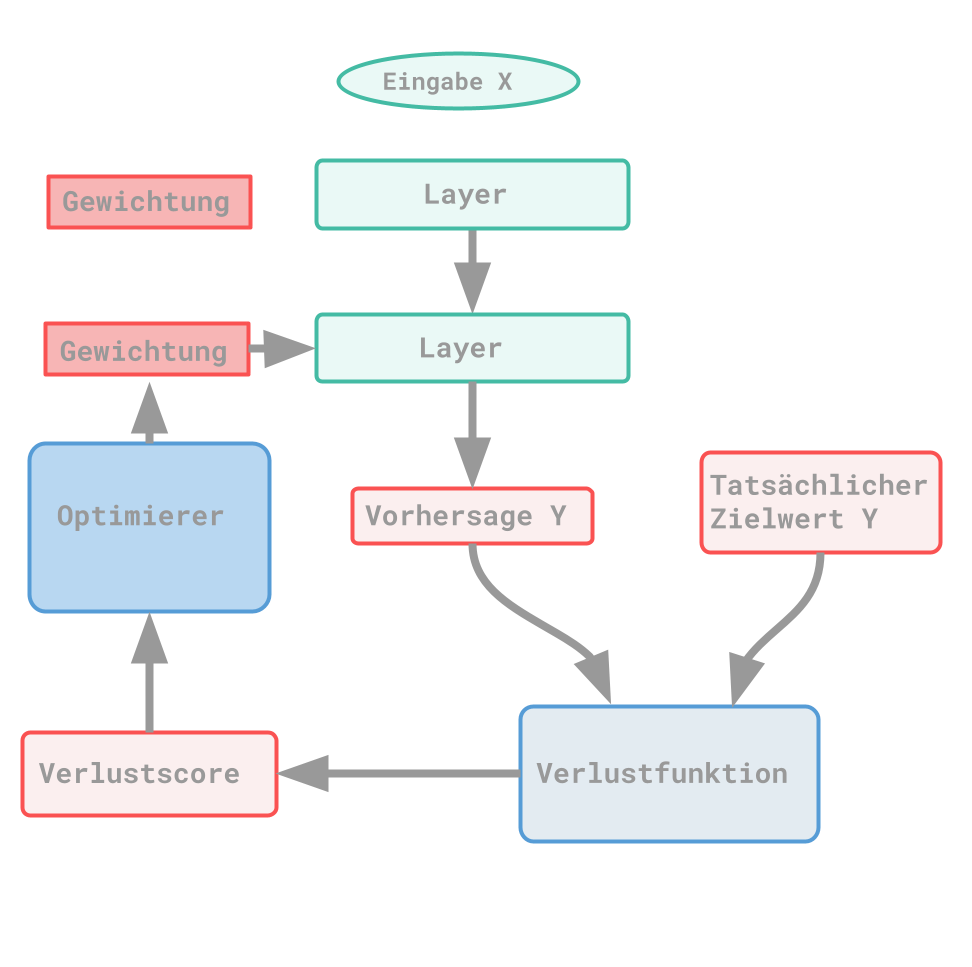
Keras
Keras is a deep learning API written in Python. It offers an easy and fast implementation of neural networks. Keras gives you the ability to run your code on the CPU and GPU.
Keras offers a library for models and can access backend engines such as TensorFlow, Theano-Backend or CNTK. An example of a typical Keras workflow is the definition of the training data using input tensors including the target value tensors. The model, i.e. the neural network, must then be determined using layers. The third step is to configure the learning process. In this, the loss function, the optimizer and the key figure to be monitored are defined. Finally, the training process can be started.
Machine Learning
Sub-areas of machine learning
Supervised learning
This is the most common way of learning with neural networks. In the process, input data is assigned to specific target values using example data.
Examples:
-
Binary Classification
-
Multiple classification
-
Scalar Regression
-
Sequence generation: Adding an image description.
-
Syntax tree prediction: Break down sentences into their component parts.
-
Object detection: Detect object within an image.
-
Image Segmentation
Unsupervised learning
This method is mostly used for visualization, compression and cleansing of data. Data analysts in particular use this frequently.
Self-supervised learning
This is very closely related to supervised learning. The difference, however, is that no class designations are given by people. Instead, these are generated using the input data. An example of this would be autoencoders.
Reinforced learning
Actions are learned, for example, by a neural network observing a video game screen and issuing control instructions for maximizing the score.
Training and Assessment
When training a neural network, each time one should distinguish between training data and test data and subdivide them. The network should be trained with the training data and recognize suitable rules. The rules should then be used to make predictions and use test data to check how good the prediction is. If the training data is also used for checking, the predictions become worse with new data. This is then referred to as overfitting. For this reason one should split data into training, validation and test data. The training data is used for pure training. The performance of the network is checked using the validation sets. Once the training is completed, there is a test run with test data.
There are also some evaluation methods that you should know about:
Holdout method
The point of this method is simply that you should keep a small part of the total amount of data for testing purposes. There’s often the problem that not enough test data or training data is available.
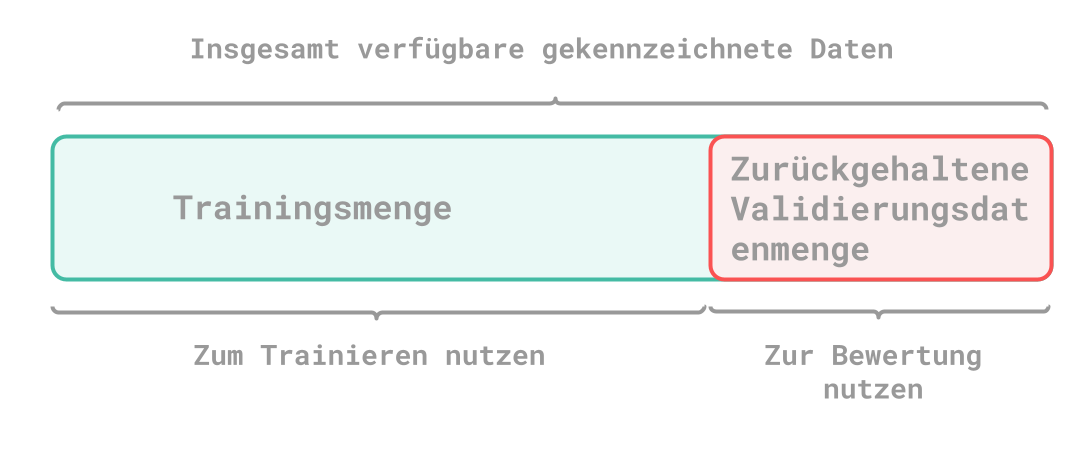
K-fold cross validation
Another variant is cross-validation. The existing data is divided into several subsets (K). Then one part is used for testing and K-1 parts for training. In the end, the overall score is derived from the scores of the individual runs.

However, if you don’t have enough test data, another variant you could use is K-fold cross-validation with shuffling. There is an additional step that mixes the data each time before splitting. However, it should be mentioned that the computational effort is also considerably higher.
Selection of training data
When choosing training data, there are a few things you should definitely keep in mind. Most importantly, the split must be meaningful data. For example, if your neural network is designed to recognize numbers and you split your data so that the training data is digits 0-6 and the test data is digits 7-9, then the data is not truly representative.
Another point to consider is the time aspect. An example of this would be a model for weather forecasting, because here the test and validation data must be in the past in order to be able to check whether the forecasts are correct.
You should also note that there should be no duplicate data. In this case, it can happen that you train with training and test data, which is to be avoided at all costs.
Data preparation
Fot you to be able to use the data for neural networks, it has to be brought into a certain form.
Vectorization
Data vectorization is about transforming your input values, as well as target values, so that they can be used within tensors. These are floating point numbers or whole numbers. If it is text, for example, then it can be displayed as an integer list, which stands for word sequences. These can in turn be converted to float32 tensors.
Normalization
Normalization is actually about the fact that suitable values are available. Small values should be selected, which are in the range between 0 and 1. This can be achieved, for example, by dividing the data before adding it. Another feature should be the use of similar values. This means that the values should correspond to roughly the same range of values.
Missing values
If you are missing values in the example data, you can simply use 0 instead. However, this only applies as long as 0 has no meaning. By setting 0, the neural network will learn that these are missing values. If you cover the case in this way, you should definitely add test data with missing values as well.
Feature creation
The point here is to formulate the task in advance in such a way that it can be solved as easily as possible. Because you already enter the transformation, you can save computing power. This was often necessary, especially in the past, because some algorithms did not even have the opportunity to learn certain features.
Upgrading models
When evaluating or predicting values, there is always overfitting from a certain point in time if nothing is done about it. The subject of optimization is important because it allows adjustments to be made to a model in order to achieve the best possible result with the test data.
Another important point is the generalization ability, which describes how good the results are with unknown data. During the first training runs, the ability to generalize improves. However, if you repeat this too often, your validation score drops and you have overfitting. This happens because the model recognizes certain patterns in the training data and these become habitual. As a result, these patterns are no longer so important for new data. To counteract this, one can add new training data to the model to improve the generalization ability again.
Another variation is limiting information storage, which aims to focus the model on more conspicuous patterns. This would be a regularization, for which there are some examples such as reducing the size of neural networks, adjusting the weight, or drop-out regularization.
Machine Learning Workflow
As a first step, you should define the task precisely. This includes determining the input data to be used and the prediction to be made. In order to be able to show this or to be able to learn it, first, you should have the appropriate training data available. You should also think about the task type. The task type is the basis for the model architecture and other parameters.
Then you should think about how you can check whether the predictions are successful or not. From this you can make further decisions about the choice of the loss function. You should also decide on an evaluation method.
Once those decisions are made, it’s now time to prepare your data. This includes forming into tensors, finding the right values for your data, and deciding whether feature creation is necessary.
Conclusion
With this TechUp I hope I was able to give you a better understanding of the basics for the topic of my next TechUp, TensorFlow. This should help you to understand what things like machine learning or deep learning even are. You have also learned about the most important terms, which will make it easier for you to get started with the next topic. Keep it up!