
The following questions will be answered in this TechUp:
- What is Rook❓
- What is Ceph❓
- How are Rook and Ceph related❓
- How can I use Rook in my Kubernetes cluster❓
- When does it make sense to use Rook❓
What is Rook❓
Rook is an open-source, cloud-native storage orchestrator for Kubernetes that simplifies storage management in Kubernetes clusters. 💡
Let’s take a look at a picture…
Figure: Source: DALL-E, OpenAI
Well, admittedly, DALL-E generated a nice and impressive picture, but we won’t get any smarter from it. 🤓 So back to basics:
Classically, storage is provided by the cloud provider and you don’t have to worry about it. But what if you need storage in your own Kubernetes cluster? This is where Rook comes in.
Behind Rook are maintainers from Cybozu, IBM, RedHat, Koor, Upbound and many others. In total, there are over 400 active contributors driving the golang project forward.
Rook can be found on the CNCF Landscape in the “Cloud Native Storage” category and is listed there as the only project with “Graduated” status. It took a good two years from Sandbox status in January 2018 until Rook received “Graduated” status in October 2020.
Rook delivers minor releases every 4 months, patch releases every 2 weeks. This speaks for an active community and a healthy project.
Rook pursues the following goals:
- Provide storage natively in the Kubernetes cluster (PVCs)
- Automatic deployments, configs & upgrades
- Storage management with an operator and CRDs (Custom Resource Definitions)
- Open Source!
- Building on Ceph
- High Availability & Disaster Recovery
Rook can be installed anywhere Kubernetes runs! The prerequisites currently include a Kubernetes version between v1.26 and v1.31. You also need disks that are not partitioned or formatted and that Rook can access.
Ok good, understood, Rook is a storage orchestrator for Kubernetes, but what is Ceph❓
What is Ceph❓
Ceph is an open-source, distributed storage system that was introduced in California in 2007. The company behind Ceph was acquired by RedHat in 2014 and is still being developed there today. Ceph itself is written in C++.
Basically, Ceph is highly available in its structure; several Ceph nodes form a Ceph cluster. Files are stored redundantly, which increases reliability. Persistent data is always stored on multiple nodes, so the failure of one node does not affect data availability.
Ceph is widely used in the industry; one of the largest Ceph clusters is located at CERN in Geneva.
Ceph offers three types of storage:
- Block storage using RBD (Rados Block Device)
- File storage using CephFS (Ceph File System)
- S3 & Swift object storage using RGW (Rados Gateway)
This allows Ceph to be used for numerous use cases, from databases to file servers to backups.
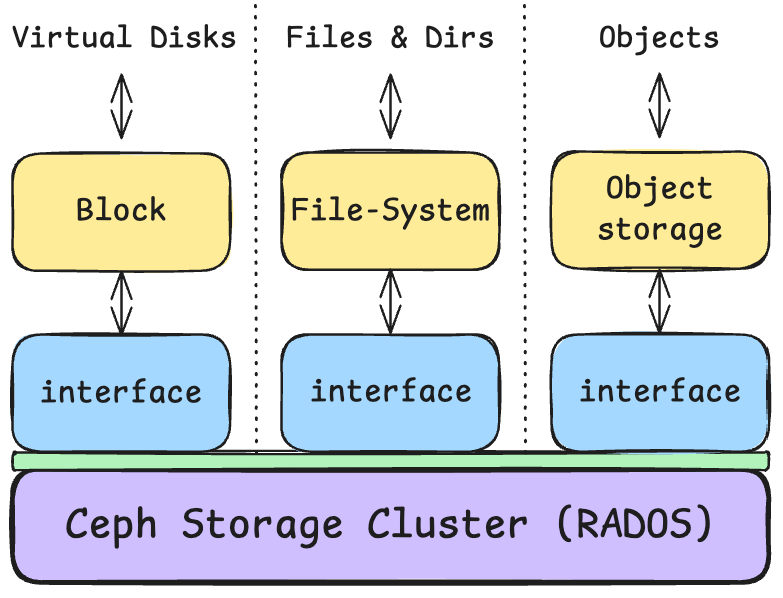
Figure: Source: Selfmade
It is nice to see in the diagram above that all types are summarized under the hood in RADOS (Reliable Autonomic Distributed Object Store). The different types of storage are provided through interfaces that sit on top of the RADOS backend.
Ceph can only be installed on Linux systems.
A big picture of Ceph could then look like this:
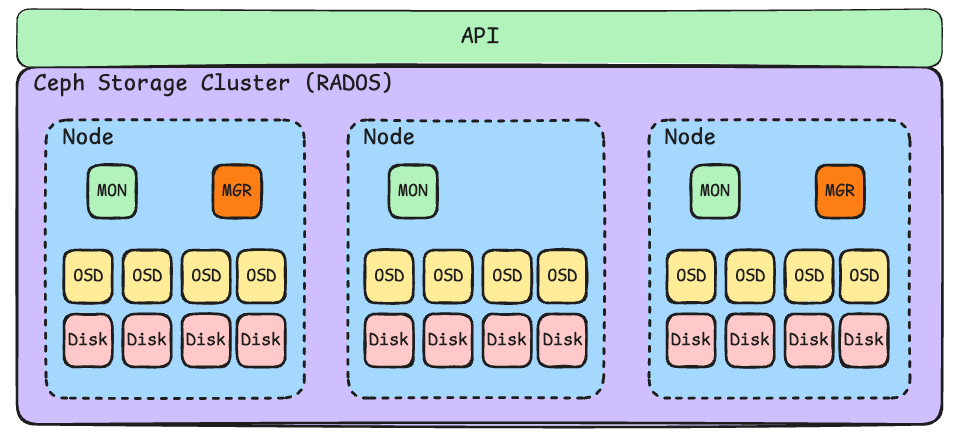
Figure: Source: Selfmade
As you can see in the picture above, the Ceph cluster consists of multiple nodes to ensure fail-safety. Multiple clients can thus access the Ceph cluster via standardized interfaces. The data is stored and replicated with the OSDs (Object Storage Devices) on the respective disks. The monitors (MONs) manage the cluster, and the managers (MGRs) are responsible for monitoring and reporting.
Ceph itself is open source, but numerous enterprise vendors offer solutions, such as RedHat with Ceph Storage.
Of course, Ceph also has a dashboard to monitor and manage the cluster.
I won’t go into more detail here - Ceph is a complex topic! More information can be found here or here or in the official documentation.
Well, so Rook is a storage orchestrator for Kubernetes and Ceph is a distributed storage system. How are the two related❓
How are Rook and Ceph related❓
Rook is an operator for Ceph that simplifies the management of Ceph in Kubernetes clusters. So Rook builds on Ceph and provides a Kubernetes-native interface for managing Ceph.
- Rook = Operator responsible for managing Ceph
- CSI = Container Storage Interface, standard for storage in Kubernetes
- Ceph = Storage backend, data layer
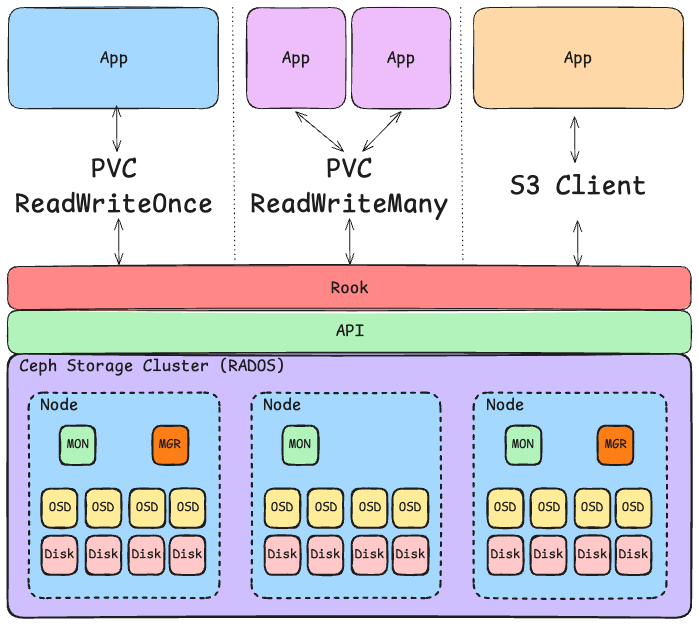
Figure: Source: Selfmade
The picture above shows the interplay of Rook, Ceph and Kubernetes. Different apps use either a Persistent Volume Claim (PVC) or an S3 client to access the storage. The Rook operator abstracts the CSI (Container Storage Interface) plugin and creates a bridge between Kubernetes and Ceph.
Rook also monitors the cluster to ensure that storage is always available and in good condition. This is one of the main tasks of the Rook operator: it interacts with Ceph and ensures the availability of storage.
What else happens in the example above:
- The blue app uses its own PVC of type Block Storage as a volume mount.
- The purple app uses a shared PVC as a shared file system, so both apps can access the same data, both read and write. Ceph ensures that the data is consistent and that there are no conflicts.
- The orange app uses a standard S3 client to access the object storage. In this case, the Rook operator automatically creates a bucket and provides the access data as Secret & ConfigMap.
More information can be found here: Rook Docs Storage Architecture
Where the data is physically located in the end also always depends on the configuration of our CephCluster CRD.
How can I use Rook in my Kubernetes cluster❓
You can easily deploy Rook in your Kubernetes cluster in the following ways:
- Follow the Quickstart Steps and deploy the example (not recommended for production)
- Use the Helm Charts for Rook-Ceph-Operator and Rook-Ceph-Cluster
Let’s theoretically go through the quick start guide step by step:
To use Rook, we first need to install Rook’s Custom Resource Definitions (CRDs).
Then the common.yaml file is applied, which creates the namespace and numerous service accounts as well as RBAC roles and bindings.
After that, the operator.yaml file is applied, which configures and deploys the Rook operator in the cluster.
And then our basic Rook installation is done! 🎉
Now we can deploy a Rook-Ceph cluster, but let’s first take a quick look at what it takes.
Basically, a Rook installation consists of the following components:
- Mon (Monitors): Manage the cluster topology and ensure consistency. Three monitors are standard for high availability.
- Mgr (Manager): Monitors cluster metrics and status and performs management functions. Mostly with one active and one standby manager.
- OSD (Object Storage Daemons): Stores data and ensures its replication in the cluster. Each OSD represents a storage unit, e.g. a hard disk. The OSDs run here in a primary/secondary configuration, the primary replicates the data to the secondaries.
- MDS (Metadata Server): Manager for metadata in CephFS, the file-based storage. Required for CephFS, but not for block or object storage.
- RBD (RADOS Block Device): Provides block-based storage that can be directly mounted in Kubernetes as a Persistent Volume (PV). Ideal for databases and applications that require consistent and fast block storage.
- RGW (RADOS Gateway / Ceph Object Gateway): Enables access to object storage via HTTP(S) with S3- or Swift-compatible APIs. Perfect for cloud-based object storage to provide data via RESTful APIs.
However, all these components do not have to be configured manually, but can be configured via Rook’s Custom Resource Definitions (CRDs).
Let’s take a look at the cluster.yaml file from the quick start example.
We immediately see that a Custom Resource Definition (CRD) of type ceph.rook.io/v1 CephCluster is created for the Rook-Ceph cluster. This resource configures the cluster and defines numbers, parameters and other basic settings.
- Cluster Name & Namespace: The cluster is called
rook-cephand runs in the namespacerook-ceph. - Ceph Version: The image version is
quay.io/ceph/ceph:v18.2.4, here we define the version of Ceph and Rook. - Monitors (Mon): Three monitors for fail-safety, each on separate nodes. With
allowMultiplePerNodewe could allow multiple monitors to run on one node, which in production however makes no sense, since a failure of the node would endanger the entire cluster. - Manager (Mgr): In this setup two managers are started; one is active and one is passive in standby mode. Here
rookmust be activated as a module. - Dashboard & SSL: The Ceph dashboard is enabled and secured via SSL.
- Monitoring: Here we can also activate Prometheus to monitor the cluster. Further down in the file, configs for storage, failover and health checks are defined.
Well, that was a brief insight into the configuration of a Rook-Ceph cluster. Do I need Rook in my Kubernetes clusters? 🤓
When does it make sense to use Rook❓
Well, now we know roughly and theoretically how Rook works and how it relates to Ceph. But when does it make sense to use Rook❓
Rook is a great fit for cloud-native environments, especially Kubernetes clusters that need flexible and scalable storage. Because Rook uses Ceph as its storage backend, it provides a solution for block, file, and object storage in a single system. This makes it ideal for environments that require different storage types and rely on automation, self-healing, and scalability. Especially in on-premises Kubernetes clusters that do not have direct cloud storage access, Rook is a valuable addition. For managed clusters in a PaaS (Platform as a Service), Rook is often not necessary because the cloud provider already provides storage solutions.
However, for simple workloads that do not have high storage requirements, Rook is often overkill. Since Ceph works efficiently especially with large amounts of data, its use in small environments can be inefficient and cumbersome. Rook is also less suitable for extremely latency-critical applications, as Ceph can increase latency due to its architecture. If a company already has a well-functioning external storage service, Rook is often not necessary and only adds complexity.
As so often: Use-case dependent! 🤓
Let’s take a quick look at the advantages and disadvantages of Rook:
Advantages of Rook
- Integrated and cloud-native: Seamless integration into Kubernetes, the DevOps engineer doesn’t actually notice Rook and Ceph.
- Multi-protocol support: Provides file storage (CephFS), block storage (RBD) and object storage (RGW) in one.
- Automatic scaling and replication: Provides self-healing and data replication to protect against data loss.
- Flexible configuration: Can be adapted to different workloads and storage types.
Disadvantages of Rook
- Complex management: Ceph is powerful, but also demanding in configuration and maintenance.
- High resource consumption: Consumes many resources, which can overload small clusters.
- Latency and performance: Less performant than specialized storage solutions for extremely low latency requirements.
- Lack of support for small environments: Often overkill and inefficient for smaller environments.
Conclusion
Theoretically promising if you need it and depend on it!
From my point of view, Rook has earned the Graduated status at the CNCF and is a solid project that is used in many Kubernetes clusters. Integrating Ceph into Kubernetes is a powerful tool for providing flexible and scalable storage. For companies looking for a cloud-native storage solution, Rook is definitely worth a look. However, for smaller environments or latency-critical applications, Rook is often not the best choice.
If you are using a managed Kubernetes cluster, Rook is often not necessary because the cloud provider already provides storage solutions.
This techup has been translated automatically by Gemini