
In this Techup, we’ll explore the best way to write multiple events to a single Kafka topic. To illustrate this, I’ve devised a practical use case. We regularly publish blog articles on various topics, which we call Techups. Additionally, we’ve had our own podcast called Decodify for some time now. All of this is part of our internal research and development process and is collected in our Techhub. Therefore, in this example, there’s a topic called Techhub that receives events of the type Techup and Decodify.
Below, you can see that different events are intended to be written to the TechHub topic:
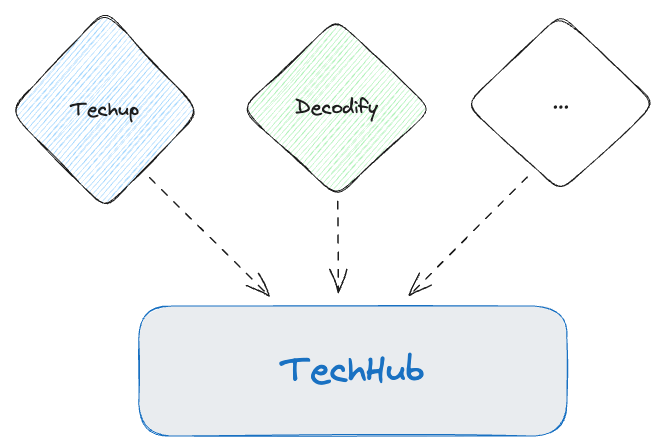
Practical Implementation: One Kafka Topic for Multiple Event Types
The example is implemented using a Quarkus application in version 3.9. The best way to start is by creating the basic framework in Quarkus itself.
Schema Development: Basics and Implementation
The first step is to create our desired schemas, from which the corresponding Java classes will be generated.
First, the Techup schema — techup.avsc:
|
|
We also need our Decodify schema — decodify.avsc:
|
|
However, to enable writing multiple entries to the same topic, we need another file that serves as a reference to the other two schemas.
bnova_techup_techhub_topic_all_types.avsc:
|
|
Kafka Topics — Set-Up
Now it’s time to create the corresponding topic. Our Techhub topic needs to be defined as both an input and output topic within our example project. This is because we’ll later provide an endpoint for testing purposes that will write to this topic, allowing us to test that both schemas can be read. The prefixes mp.messaging.outgoing and mp.messaging.incoming define whether the topic is used for receiving or sending.
In our example, the SmallRye Kafka Connector is used to send and receive messages to Kafka. This allows the application to efficiently send messages to a Kafka topic.
The setting with the postfix topic defines the name of the corresponding topic. Additionally, the desired serializer and deserializer must be defined so that the data can be processed correctly.
To enable the deserializer to use the exact schema that was used when writing the data, specific.avro.reader is activated.
|
|
Essential Kafka Services
To utilize different schemas, we need a Schema Registry. I’ve chosen the solution from Confluent for this purpose. Together, these services form a complete Kafka architecture deployed via Docker, providing a robust platform for message transmission and schema management. Each service plays a specific role:
The Kafka Broker is the heart of the system and is responsible for managing and storing messages. The configuration defines the necessary ports, environment variables, and listeners to enable communication.
|
|
The Schema Registry from Confluent, specified in the second service block, is crucial for schema management, which is needed in Kafka environments to ensure the compatibility and versioning of the schemas used for message serialization. The configuration ensures that the Registry has the necessary information to communicate with the Kafka Broker and effectively store and manage schemas.
|
|
To enhance user-friendliness and provide a graphical interface for interacting with the Kafka cluster, the kafka-ui service is employed. This tool allows users to visually inspect and manage the topics, partitions, messages, and schemas within the cluster. It is particularly useful for debugging and monitoring as it provides a quick overview and easy control of Kafka resources without complicated command-line operations.
|
|
Registration and Usage of Avro Schemas
After setting up the Schema Registry, the prepared schemas need to be registered. This is done through configuration in the application.properties, where the URL of the Registry is specified as follows:
|
|
To effectively register and manage the schemas, an additional plugin is required. The Avro schemas should be placed in a specific structure within the project directory so that dependencies/references can be resolved.
|
|
The kafka-schema-registry-maven-plugin from Confluent is configured in the project’s pom.xml file. This plugin allows registering the schemas directly from the project structure and ensuring they comply with the compatibility policies defined in the Schema Registry. The plugin configuration looks like this:
|
|
To ensure that the required dependencies are available, the Confluent repositories must be added to the pom.xml. This allows Maven to find and load the specific Confluent packages:
|
|
With this configuration, we can efficiently register the Avro schemas and ensure they are correctly validated and compatible with the requirements of the Kafka applications.
Implementation of the Consumer
Now we focus on implementing a Kafka Consumer. The consumer is represented by a Java class that we simply call Consumer. To listen to a specific Kafka topic, we use the @Incoming annotation from MicroProfile Reactive Messaging. This indicates that this method should receive messages from the “techhub” topic.
For flexibility in handling different schemas, we use the SpecificRecord as a parameter of the process method. SpecificRecord is an interface from the Apache Avro Framework that allows handling generated Avro objects, each representing a specific schema.
Currently, the functionality of the consumer is limited to logging information about the received Avro record. The class is configured to output the name of the Java class object representing the Avro record in the log. In our scenario, we expect the names com.bnova.Techup and com.bnova.Decodify to appear in the log, depending on which schema is used in the incoming messages.
|
|
Interactive Testing of the Topics
To enable writing messages to the Kafka topic “Techhub” for testing purposes, I’ve implemented a REST endpoint that allows manually creating and sending entries for two different object types – Techup and Decodify. The endpoint offers two specific paths: /test/techup/{title} for a Techup object and /test/decodify/{title} for a Decodify object.
For sending these objects to the Kafka topic, the Emitter mechanism of MicroProfile Reactive Messaging is used. This emitter is connected to the name of the topic to be written to using the @Channel annotation. This makes it possible to send messages directly from the application to the specified topic.
In the Java code, it looks like this:
|
|
By implementing these endpoints, the user can create and send example Techup and Decodify objects to the Kafka topic through simple HTTP GET requests. This method is excellent for debugging and testing integration and processing logic in the Kafka environment.
Commissioning
To test the required infrastructure for our Kafka and Quarkus application, we first start the services via Docker Compose. The command docker compose up in the directory containing our docker-compose.yaml file downloads all necessary images and starts the containers. We can then check the correct execution and status of the containers using the command docker ps. The result should look something like this:
|
|
Next, we check if the Schema Registry has started successfully and is accessible, although no schemas should be registered at this point.
![]()
Once the services are running, we start our Quarkus application in development mode with mvn quarkus:dev. If this process is successful, we should see the newly created topic bnova-techup.techhub-topic.v1 in the Kafka UI.
![]()
Now it’s time to register the schemas for our events that we previously configured in our Maven project. We achieve this by executing the command mvn schema-registry:register, which registers the schemas in the Schema Registry:
|
|
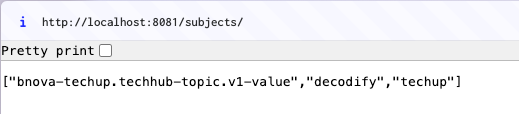
The successful registration can also be verified directly in the Registry.
The actual test is performed by sending two different event types via our REST endpoint. We use Curl commands to send one Decodify and one Techup event to the topic.
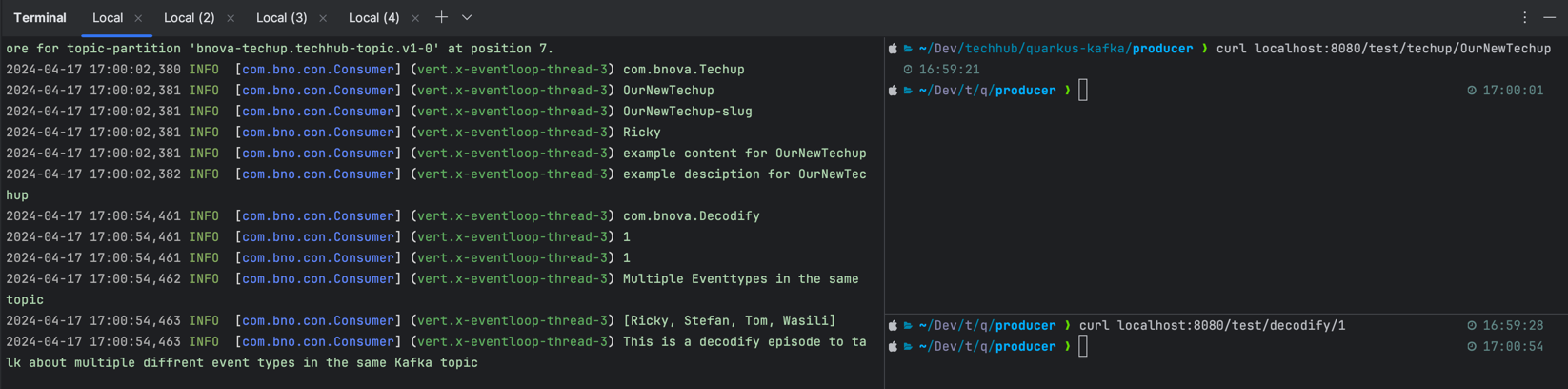
As you can see on the right side, one decofiy event and one Techup event were sent. On the left, you can see the output, which outputs the correct classes as desired.
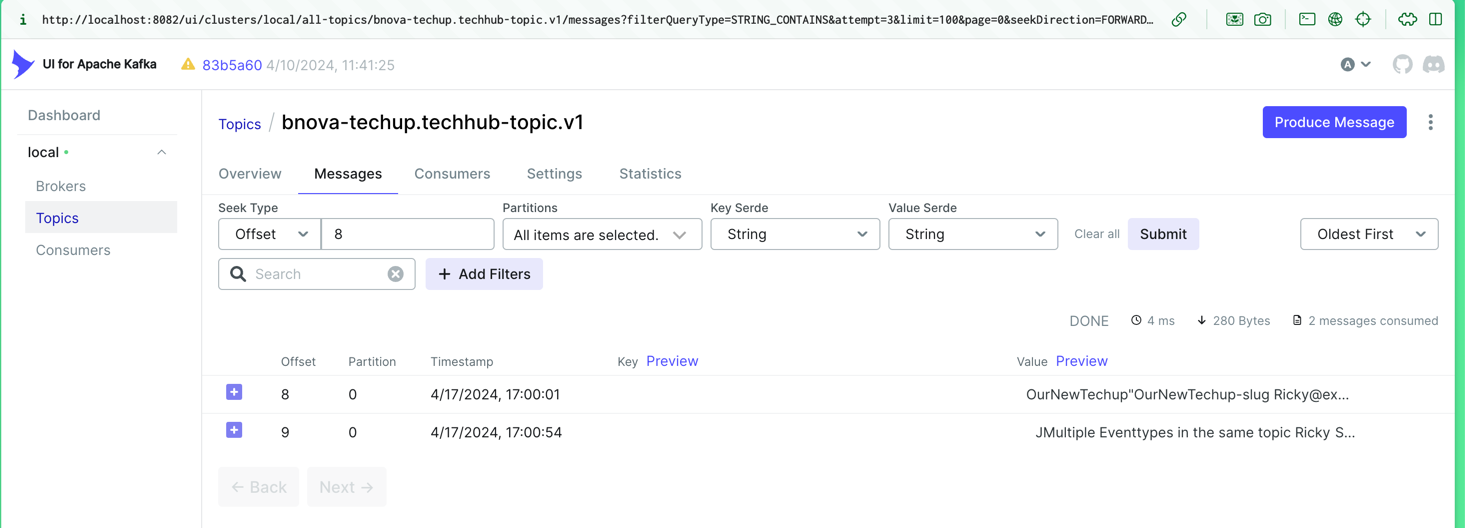
We can see the results of these actions not only in the console but also in the Kafka UI, where the received messages are displayed.
[!TIP]
The entire code can also be viewed via the Techhub Repository
Conclusion
Implementing this approach presents both challenges and significant advantages. Technically, simplifying with a single topic initially increases complexity, especially during the initial configuration. A specific type is not read directly from the topic but is processed as a SpecificRecord that needs to be checked before further processing. The use of Avro schemas also limits the use of generic classes or inheritance structures.
On the positive side, there is a significant reduction in administrative effort and costs, as fewer topics need to be maintained, and costs are often calculated per topic. Additionally, the structure allows for flexible expansion with new types without much effort: It only requires creating a new schema, registering it, and possibly adjusting the business logic. This approach offers an efficient solution for dynamic and scalable data architectures in modern applications.
This techup has been translated automatically by Gemini