Robustness and resilience in the cloud
Only when systems are put under load can their susceptibility to failures and malfunctions be identified. The same applies to extensive software systems, which nowadays prefer to run decentralized, compartmentalized and containerized in complex cloud architectures. Where in the past monoliths dominated the software landscape, today there are more and more combinations of modular software components, such as microservices, container orchestration and cloud-native functions. This increased complexity in the network is more prone to failures and is therefore prone to loss of general robustness and resilience.
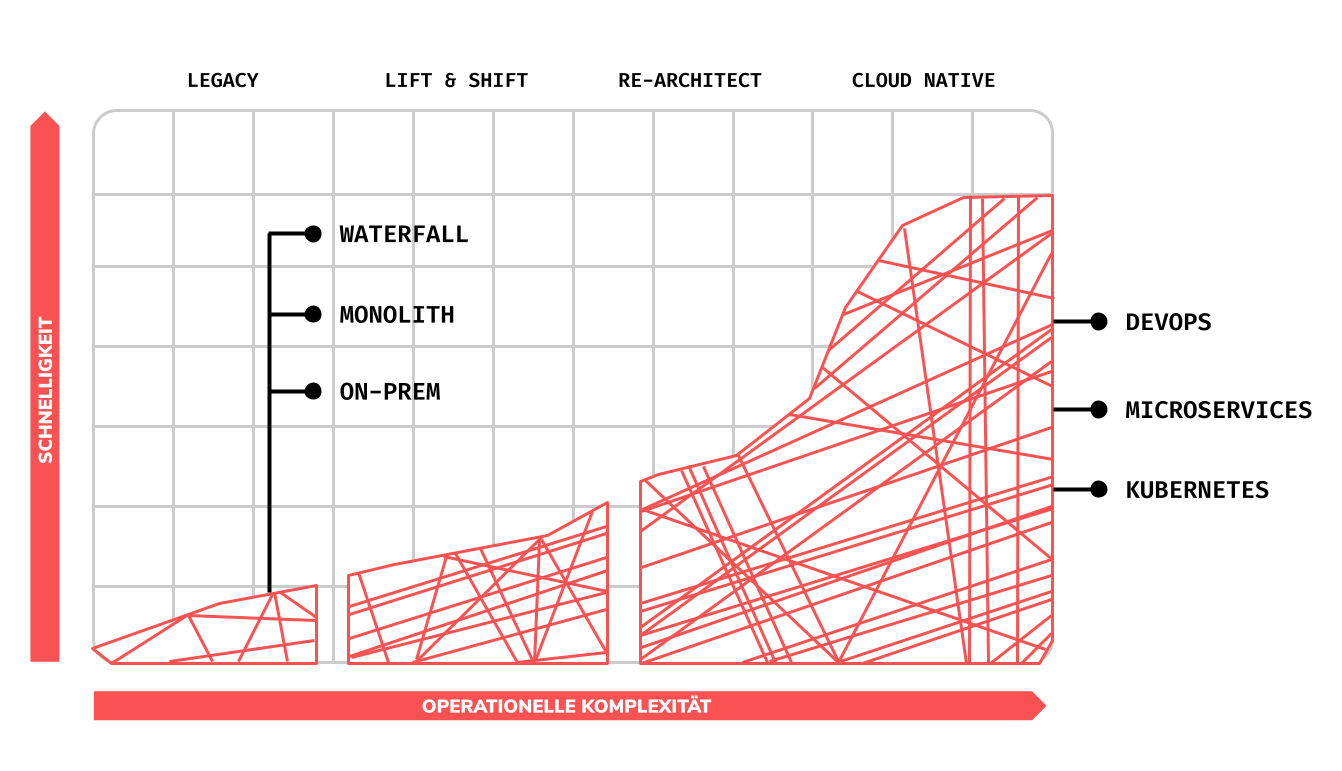
By proactively putting such systems under load, failures can be identified and rectified. This is called Chaos Engineering and has the purpose of optimizing and guaranteeing the stability and resilience of a system. In this day and age it has become essential to avoid unplanned failures and unforeseen failures. If no corresponding chaos engineering is carried out, unpleasant and cost-intensive situations can quickly arise for the stakeholders and in the user experience. According to a study from Gartner in the year 2014 a company can lose on average up to $ 336,000 per hour in the event of a failure. E-commerce websites are particularly hard hit, where it can cost up to $ 13 million per hour of downtime.
A word about anti-fragility
Fragile systems collapse when they exceed a certain load limit. Robust systems know how to continue to function beyond this load limit. Antifragile systems become even more robust when exposed to this load. Nassim Nicholas Taleb described this in detail in his book Antifragile: Things That Gain From Disorder. Taleb sums up Antifragil’s premise as follows:
- Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, [risk](https://en.wikipedia.org/wiki/Risk , and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.
Chaos engineering can therefore be equated with an antifragilizing process. Doing chaos engineering is to ensure that a cluster operation and its services are always more stable and resilient over time.
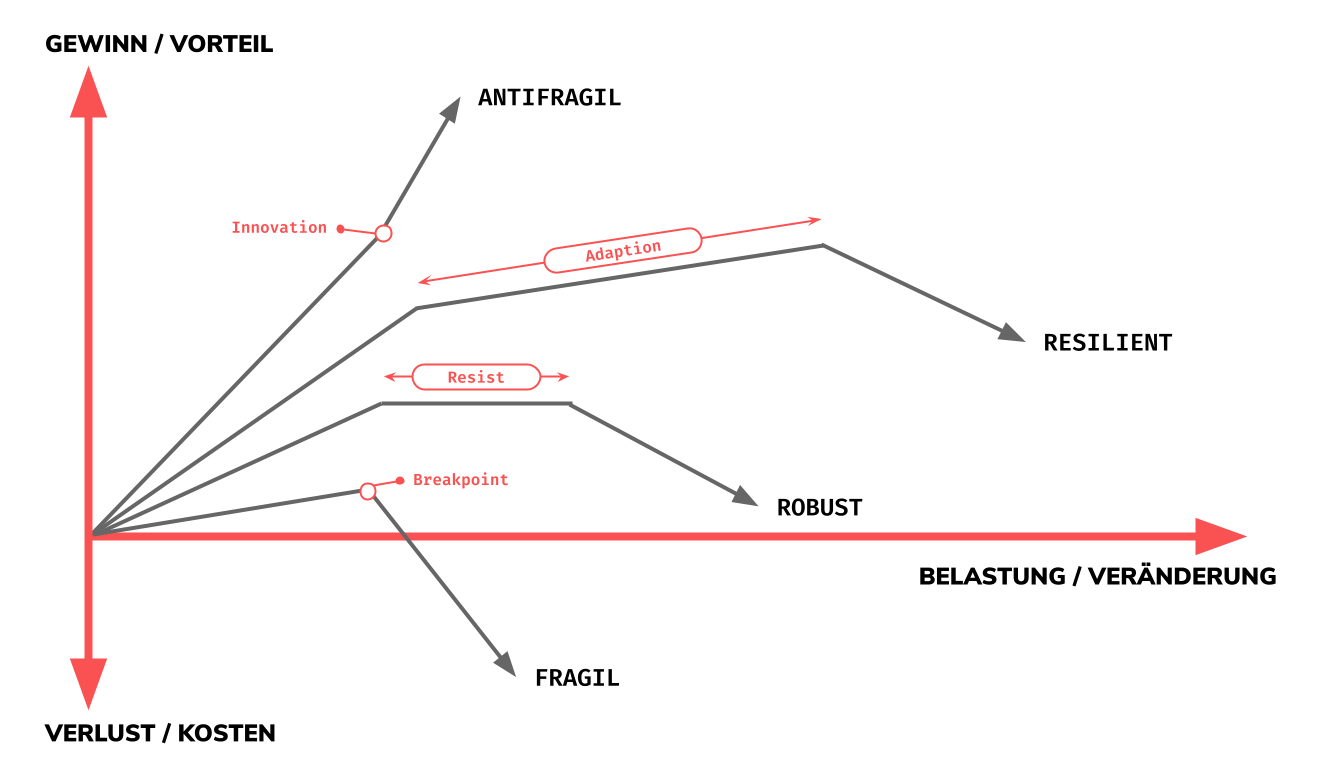
As can be seen in the graph above, there are 4 different types of behavior of systems under load:
-
Fragile: In fragile systems there is an inherent limit to the load, a so-called Breakpoint. If this is exceeded and the fragile system subsequently breaks, this causes unwanted, often unplanned, additional costs. This type of system should be avoided especially with software systems, since failure costs can quickly become significant. The overfilled glass falls on the floor.
-
Robust: In robuste systems there is a phase of resistance (called Resist in the graph above). The robuste system is characterized by the fact that it can withstand stress, but cannot pass it on and thus has reached an operational and functional ceiling. The robuste system also collapses when the load is increased. The glass that falls on the floor is made of zirconium.
-
Resilient: In resilient systems there is an adaptation phase. This means that the system can adapt to a certain extent under load and can thus guarantee operational functionality. But the resilient system also has a load limit and collapses if the load is too high. The glass falling on the floor is caught by a sophisticated safety device.
-
Antifragile: The antifragile system behaves fundamentally different from the 3 previous system types. The antifragile system knows an innovation point when it is stressed, whereby it increases in operational functionality the higher its stress is. In other words, the antifragile system becomes more efficient under stress because it knows how to deal with it. In the real world, man-made anti-fragile systems are often associated with a culture of “We celebrate our failures”, a motto widespread in Silicon Valley.
How to do chaos engineering
“Chaos Engineering lets you compare what you think will happen to what actually happens in your systems. You literally “break things on purpose” to learn how to build more resilient systems."
– Gremlin on Chaos Engineering
The basic idea behind Chaos Engineering is to let things break in a cluster configuration in a conscious and controlled manner. The procedure is built empirically. It behaves like a scientific experiment:
-
First you plan a experiment. The experiment involves one or more actions with which one would like to manipulate the cluster. This also includes the formulation of a hypothesis of the possible effects of the actions.
-
When carrying out the experiment, the damage must be kept within limits in a controlled manner. This is called the Blast Radius. You start with the smallest, most minimal units of action and progressively approaches the larger units of action.
-
The experiment ends as soon as a problem has become apparent. If no problem arises, the experiment can be continued and, if necessary, the blast radius increased.
-
For each experiment the impact must be determined. This can be done with predefined measures sizes. The subjective behavior is to be assessed, the functionality is to be quantified on the basis of resource utilization, state, alerts, events, stack traces, breadcrumbs and to be determined with other instruments such as throughput times.
In other words, one starts with a hypothesis about how the target system should behave. Then a experiment is carried out which could cause the least damage. During the experiment, it must be recorded what is still working successfully and what is no longer. After the first experiment, add further experiments and gradually increases the potential damage. With each iteration, the actual damage and success is recorded. At the end of the increased chain of experiments, there is a clearer picture of how the system behaves in the real world. This results in further knowledge from which weak points can be identified and the first solutions can be formulated.
As soon as the weak points have been identified and solutions have been formulated, it is important to implement them and thus make the overall system more robust and resilient. The entire process of chaos engineering is thus antifragile. Go fix it!
Best Practices as advanced principles
Experience has shown that there are other notable factors that one would like to consider in chaos engineering.
-
Varying real-world events
-
Execution of experiments directly on production
-
Automating continuous experiments
-
Minimizing the blast radius
In search of unknown unknowns
At Chaos Engineering, systems are examined for weak points. Some of these weak points are known in advance and only become apparent after targeted testing. Before doing chaos engineering, one must first recognize what kind of weak points there can be in a system. The reason for this is that one can only formulate experiments in a suboptimal way and carry out their prioritization if one has not yet identified the type of weaknesses.
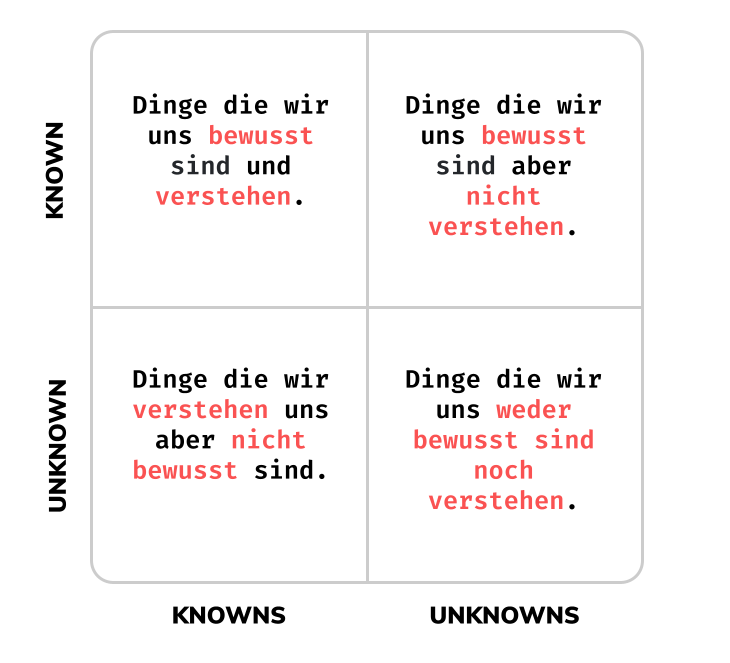
For this purpose we have drawn a 4-quadrant graphic with which one can easily classify 4 different types of vulnerabilities:
-
Known-Knowns: Things that we are aware of and understand. For example: If one instance of a service fails, a replication controller starts up a second instance.
-
Known-Unknowns: Things that we are aware of but do not necessarily understand. For example: If the cluster shares a message that a pod has been running for 5 minutes with only 1 instance. We do not know whether the 5 minutes is the optimal time for operation.
-
Unknown-Knowns: Things that we understand but are not aware of. For example: If two replicas in a cluster shut down at the same time, we do not necessarily know how long it can take Monday morning until 2 new replicas are started up again using the primary replica.
-
Unknown-Unknows: Things that we are neither aware of nor understand. For example: We don’t know exactly what happens when an entire cluster in the main region of a cloud provider is shut down.
Using these 4 categories, one can formulate experiments for a target system that try to simulate exactly these situations in the real case in order to move the unknown variables into the known. It is therefore always helpful to keep this distinction in mind when formulating experiments.
4 experiments to start
In the post of Matt Jacobs, a software engineer at Gremlin, he explains with which experiments, also called Recipes at Gremlin, one should make the first attempts of chaos engineering on one’s own cluster. We briefly clarify these here in order to symbolize the formulation of meaningful experiments:
Experiment 1: Resource Depletion
Resources on computer systems are finite. A container in a cluster also has only limited resources available, so the containerized application is obliged to use the resources made available to it. The idea of the experiment is to block the CPU cycles and to let the application run with normal customer-facing load.
-
Attack: CPU / RAM / storage medium
-
Scope: Single instance
-
Expected behavior: Response rate drops, errors multiply on all levels, Brownout-Mode enters (if implemented), alerts fired (if configured), load balancer forwards the traffic in other ways (if applicable)
Experiment 2: Unreliable network
Connections to other services in a network are part of everyday life with distributed systems. Networks are in real operation often unreliable. Precisely this type of error should not be underestimated. If a dependency fails for an application, it must be determined exactly what the result of this can be. The unavailability of network points (Services) is also called Network Blackhole.
-
Attack: Network blackhole / latency
-
Scope: Single instance
-
Expected behavior: Traffic to the dependency drops to 0 (or gets slower), application metrics remain unaffected in steady state, startup takes place without errors, traffic to the fallback systems runs and is reported as successful
Experiment 3: memory saturation
Many relevant applications in a system use at least one type of memory, but often several. We’re talking about databases, file systems, and other types of datastores. The management between storage medium and application is of great relevance for the healthiness of the overall application. There are different ways in which this can best be claimed. About a unavailability (Network Blackhole) of the storage medium, or reduced latency to the storage destination or its I / O bandwidth.
-
Attack: Network Blackhole / Latency / IO
-
Scope: Single instance
-
Expected behavior: Traffic to the datastore is slower and / or inaccessible, timeouts and concurrency limits are activated, alerts and pages are fired
Experiment 4: DNS Unavailability
The DNS is also a very important component in network-oriented systems. In October 2016 there was a worldwide big DNS outage. Although rare and therefore less risky, a DNS failure can be very costly. In our 4th recipe you want to create a DNS blackhole, i.e. the failure of the DNS, and see how you could use a backup via direct IP addresses. You can also switch off internal Service Discovery \ components (etcd, Eureka, Consul, usw.) here and see how the overall system behaves.
-
Attack: DNS blackhole
-
Scope: Single instance
-
Expected behavior: Incoming traffic is dropped, traffic to external systems fails, startup is not successful
These 4 recipes are certainly good entry points into real chaos engineering and can be easily adapted for further experiments. It is important to note here that how a recipe was defined here, namely with a definition of the type of attack (Attack), the scope of the attack (Scope) and the expected behavior (auch Expected Results). It is worthwhile to define the recipes as SMART as possible and to record the results as meticulously as possible.
So now we’ve had enough theory about chaos engineering. Let’s take a look at the tools that can best be used to operate chaos engineering as a process in your company! For this we look at 3 software projects with which one can use Chaos Engineering: chaoskube, Chaos Mesh and Gremlin.
Pod failures with chaoskube
chaoskube is a small, simple open source project with which you can easily cause pod failures. chaoskube is a CNCF Sandbox Project and is written in Go.
Features
-
randomly kills a pod in the Kubernetes cluster at a defined periodicity
-
Allows filters for namespaces, children, labels, pod names, annotations, etc.
-
Helm chart
Installation and configuration
For chaoskube there is a helm chart stable/chaoskube which you can easily install in your cluster as follows:
|
|
Recipes
chaoskube is configured directly via its deployment manifest.
This can look like this, for example, in the example repository of linki/chaoskube/examples as follows:
|
|
Run recipes
Since the recipe from chaoskube only allows pods to be switched off and its configuration is imported directly into the manifest via the manifest, the recipe can only be run in this case.
The above Deployment.yaml recognizes via the configuration of chaoskubbe (args:) that every 10 minutes a pod in an environment with value test, with the annotation chaos.alpha.kubernetes.io/enabled=true only occurs during the week and other conditions.
Thus one can relatively easily introduce a simple chaos engineering process and operate a ‘We Celebrate Failure’ \ culture.
Even more failures on Kubernetes with Chaos Mesh
Chaos Mesh is like chaoskube, but can execute a variety of chaos recipes. Just like chaoskube, Chaos Mesh is also a CNCF Sandbox Project and is also written in Go.
Features
-
Delivers predefined, customizable chaos experiments
-
thus allows a variety of different recipes (Pod, Network, IO, DNS, AWS, usw.)
-
Allows selection by namespace, label, annotation, field and pod
-
Uses CRDs for the operator definition of the chaos experiments
-
Helm chart
-
Provides a chaos dashboard
Installation and configuration
Chaos Mesh can be installed comfortably over a helm chart. To do this, first add the helm repositories from Chaos Mesh:
|
|
Then do the installation as follows (replace <NAMESPACE> with a suitable name like chaos-testing):
|
|
Then check whether the Chaos Mesh pods are running:
|
|
Recipes
Chaos Mesh offers the following Recipe-Templates. These are also called chaos experiments at Chaos Mesh:
-
PodChaos: Allows the
pod-failure,pod-killandcontainer-killof pods. -
NetworkChaos: Allows the Network Partition (separation in independent subnets) and the Network Emulation (Netem) Chaos of the cluster. The latter enables delays, duplication, losses and corruption of connections to be created.
-
StressChaos: Allows stress / strain to be generated by CPU usage on a set of pods.
-
TimeChaos: Allows the value of
clock_gettimeto be changed, which in turn creates an offset from Go’stime.Now()or Rust’sstd::time::Instant::now()and other time definitions. -
IOChaos: Allows file system errors such as IO delays or read / write errors to be generated.
-
KernelChaos: With this you can influence the performance of pods through KernelPanics. It is not advisable to do this on production, as it can lead to side effects and / or secondary reactions.
-
DNSChaos: Allows you to send faulty DNS responses or to force the resolution of arbitrary IP addresses.
-
AwsChaos: Allows EC2 instances to be stopped (
ec2-stop), restarted (ec2-restart) and volumes removed (detach-volume).
Example of a pod kill recipe
To run a Pod Kill as an experiment with Chaos Mesh we have to use the PodChaos operator and write a manifest that could look like this:
|
|
As can be seen in the manifesto above, a PodChaos operator is defined here, which has a cron \ expression of @every 1m via the scheduler.
The selector defines what can be affected, namespaces and labelSelectors.
With Chaos Mesh, it is relatively easy to define different recipes and have them executed on the target cluster. Chaos Mesh is particularly suitable when you want to generate more than just pod kills.
Gremlin - Chaos-As-a-Service
Gremlin is an enterprise-ready Chaos Engineering Platform and thus the top dog on the monkey throne. Gremlin is a CNCF sandbox project and is closed-source. Gremlin is based on and is a continuation of Chaos Monkey.
Chaos Monkey was a custom resiliency tool designed by Netflix in 2010 that had pioneered chaos engineering. When Netflix switched to the cloud provider Amazon Web Services in 2010, it was important for the Site Reliability Engineers (shortly SRE) to be able to guarantee the availability of Netflix streams as their trademark. The tool developed into a second version, called Simian Army. With this, Chaos Engineering was expanded and included people from the DevOps, engineering and SRE areas. Chaos Monkey and its continuation as Simian Army lives on in Gremlin to this day and thus became the market leader.
Installation and configuration
First get yourself an account on Gremlin.
Gremlin can also be installed on your cluster using a helm chart as follows.
To do this, we first add the Helm repo gremlin as follows:
|
|
Then we install the Gremlin Helm chart.
Here I am using the namespace name gremlin.
To do this, add the secrets (clusterId and teamSecret):
|
|
Then log in to your Gremlin-Dashboard. The dashboard looks like this:
Conclusion - How to make cluster operation resilient
Today we looked at how to introduce a ‘We Celebrate Failure’ \ culture with chaos engineering. Chaos engineering makes your company more resilient and, in the best case, anti-fragile. There are different tools, chaoskube, Chaos Mesh or even Gremlin, how to do Chaos Engineering, but all tools have the same procedure: You describe an experiment, make assumptions, carry out the experiment and record how the cluster actually behaves. Once you have identified the sources of error, you fix the error in order to prepare the entire system for the next failure and thus gain resilience. In cloud operations in particular, the benefits of targeted chaos engineering and advanced site reliability engineering should not be underestimated.
If you still want to learn more about chaos engineering, resilience in cloud operation and Failure ** \ - culture in DevOps, please contact us directly! We at b-nova are always interested in creating knowledge and experience for ourselves and thus added value for your company. Stay tuned!
Further resources and sources
https://principlesofchaos.org/
https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice/
https://www.gremlin.com/state-of-chaos-engineering/2021/?ref=footer
https://www.gremlin.com/roi/?ref=footer
https://github.com/dastergon/awesome-chaos-engineering
https://www.youtube.com/watch?v=rgfww8tLM0A
https://www.youtube.com/watch?v=qHykK5pFRW4
This text was automatically translated with our golang markdown translator.