
After Ricky has already shown the advantages and necessity of HA key value stores in an older TechUp, this TechUp is about the equivalent for sensitive data. HashiCorp Vault is a tool to store sensitive data like API keys, passwords and certificates not only securely, but also highly available. In the first part of this TechUp we’ll just be looking at the architecture and the basic structure of Vault. Hands-on examples will be in a future article.
Secrets
First of all, the question arises as to what secrets are and why you need your own software to manage them. Secrets are sensitive data to which only a limited group should have access, as they provide access to systems or areas that not everyone is supposed have access to. Examples of this would be passwords, certificates, but also keys for encrypting and decrypting data.
As soon as you move in the context of a larger team, the need to be able to share secrets quickly arises. Starting with the Wifi password, secrets can also be database credentials, for example, which a development team needs for development of its software. A frequently used tool at this point is 1Password, but all major cloud providers also offer a solution for both storing secrets and allowing or restricting access to them. With the need to be able to manage access to a wide variety of secrets in a precise and controlled manner, and to make them available to technical users with high availability, many of these tools reach their limits.
Why HashiCorp Vault?
With Vault, HashiCorp launched a product in 2015 which, as a central element, provides pretty much all use cases and necessities of a larger organization in terms of Secrets and Secret Management. Vault is no longer just a pure secrets store, but a complete secrets management system, which, for example, also offers the option of creating secrets yourself as required. Vault is to be integrated into the key management area of the CNCF landscape.
This is exactly where Vault currently stands out from other tools; As an example, let’s look at the differences to AWS Secrets Manager, the solution from Amazon:
Like Vault, the AWS Secret Manager offers the ability to store, rotate, and manage access to secrets. HashiCorp Vault also offers the option of dynamically creating secrets and deleting them after a defined expiration time. Other features that Vault offers compared to what AWS offers include the ability to generate Certificates, act as a SSH CA Authority, as well as Cross region/Cross Cloud/Cross Datacenter replication and encryption and decryption-as-a-service.
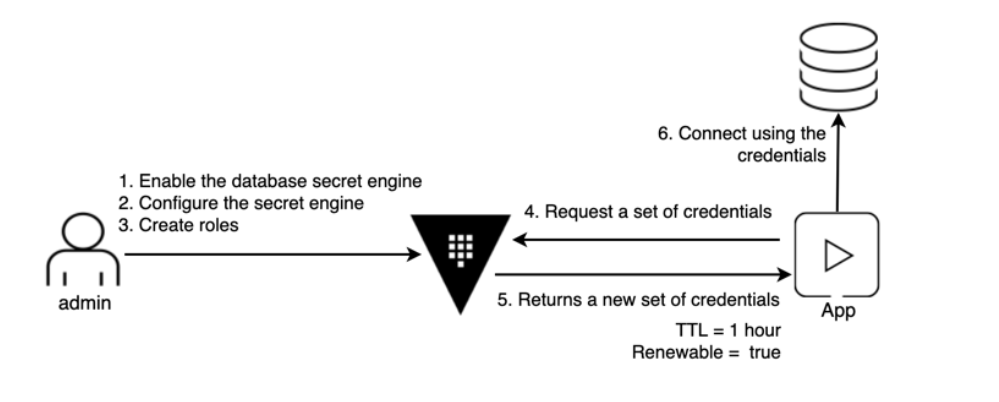
Figure: Flow example
This illustration shows an example flow: An application requires database access, the authorizations and configurations were created in advance by an admin in Vault. If an application now needs access to the database, it can query secrets, which are dynamically generated by Vault, from Vault and get access. After a predefined time (TTL) Vault automatically removes the credentials.
Various so-called Secret Engines enable the connection of numerous services to Vault; which function the individual secrets engine has is to be considered for each engine. A secret engine for a database could generate and include secrets dynamically, as in the example above. However, there are also secret engines for simple key-value stores that can store and make available key-value pairs, as well as a secrets engine that decrypts or encrypts data.
Features of Vault
- Vault handles authentication of clients, validation against third-party trusted sources, as well as authorization and access management
- Secure encrypted secret storage
- Dynamic Secrets, which can be generated on-demand for a defined lifetime
- Encryption and decryption of data outside of Vault
- Leasing from Secrets
- Audit Logs
- Both self-hosted and hosted (HCP Vault)
Architecture
In order to be able to describe the architecture of Vault clearly, after Vault has been installed, we start a Vault server in development mode with the command vault server -dev via the command line:
|
|
The server is started in development mode with an instance providing the Vault API on Port 8200. All data is stored in memory (inmem), i.e. not persistently. Also, the dev server starts unsealed which brings us to the first aspect of Vault’s architecture. Before I get into that, let’s set the API address and root token as environment variables to make all further commands more readable:
|
|
All data is stored encrypted by Vault in the storage backend. All communication with this backend is encrypted, the key for this encryption and decryption is encrypted in the “sealed” status.
As soon as the Vault Server is started, it is always in the “sealed” state (except if it’s been started as a dev-server) and must therefore first be unsealed before operations are possible. This is possible with an Encryption-Key, which is generated by the Vault Server during initialization and divided into several parts using Shamirs Secret Sharing-Algorithmus, as well as using a Trusted Vault Server, Cloud-Key-Management System or a Hardware Security Module.
In our example, however, the development server only has an unseal-key and is already unsealed. Using the command vault status, we can see the current state of our server:
|
|
As we can see, our server is unsealed and has only one secret share. Once the vault is unsealed, HTTP API can be used to communicate and clients can authenticate themselves. Vault offers several options for authentication: Via username and password, public/private keys, tokens, GitHub, cloud services, LDAP, OIDC etc.
After the client has authenticated itself, based on previously created policies a token with a specific lease time is issued, with which the client now has access to the configured areas. Vault only allows access to areas that have been explicitly given via policy. These policies are ACL rules.
In our example, we are currently using the root token to gain access to Vault. If the client now makes a request for a specific secret, it is made available by a so-called Secret Engine and is given a lease ID with which the client can cancel and renew the secret .
Using the command vault secrets list will show us the currently activated secret engines:
|
|
On the dev server, the key/value secret engine is activated by default on the path secret/. In the following section, we’ll go into more detail about secret engines.
Secret Engines
As we’ve already seen, Vault offers a variety of options when it comes to authentication. This also applies to secret engines, which are the backend solutions for different types of secrets.
For simple key-value pairs, we have already met the KV Secrets Engine, which can contain both non-versioned and versioned key-value pairs. Another example would be the Kubernetes Secrets Engine, which can generate Kubernetes service account tokens, service accounts, roles and role bindings.
A special feature is the Transit Secret Engine, which can be used to encrypt and decrypt data ‘in transit’ that is not stored directly by Vault. With this cryptography/encription as a service, guaranteed database encryption can be easily implemented on all databases without having to hold the developer responsible.
There is now a secrets engine for almost every use case; whether for all major public cloud providers, Active Directory, databases, as well as for identity management, certificates and SSH. What each Secrets Engine does and which functions it provides can be read in the respective documentation, which HashiCorp is happy to point out:
|
|
With our key-value secret engine example, secrets can be stored and retrieved as follows: vault kv put -mount=secret hello password=1234
|
|
The key/value pair we just stored using the put command can be retrieved as follows: vault kv get -mount=secret hello
|
|
Because we use the root token, we can store and retrieve secrets without prior configuration. We would first have to give a new client read and write access to the path (in this case secret/) via a policy for it to be able to perform the same actions.
High availability
Since Vault occupies an infrastructure-critical position as a central secret management system, the question of high availability and scaling is obvious.
One way to increase resiliency is to run Vault in HA mode with multiple Vault servers and a storage backend. Here, one of the servers takes on the role of the active server and answers all requests, the other instances are in hot-standby and take on requests if the first one fails.
Since newly started servers are always sealed, as described at the beginning, you should definitely think about one of the “unseal-as-a-service” options in this context. Vault supports various storage backends to persist the data such as Public Cloud Services, Zookeeper, S3, Etcd but also In-Memory and local storage.
Furthermore, since Vault 1.4, a directly integrated storage backend has been available, which is designed for high availability. It uses the RAFT-Consensus-Protocol, which we won’t go into in depth here. This would require several instances for an HA setup. In order to have fault tolerance from a server, at least three HA instances are required. For a two-server tolerance, the cluster would require five instances.
Conclusion
When it comes to Secret Management Systems, HashiCorp Vault is certainly a jack of all trades. Vault consistently focuses on key issues without adding unnecessary complexity. The variety of secret engines and authentication options leave nothing to be desired. Possibilities like encryption-as-a-service top it off. Like all other HashiCorp products, it’s Open Source and self-managed, free of charge. For more information on Vault, I highly recommend the Documentation and the Tutorials provided by HashiCorp.
I hope I was able to give you a good first overview of HashiCorp Vault in this TechUp. In the next part, the focus will be on hands-on. Stay tuned!