The interface is everything
Interfaces are sometimes one of the most important aspects in the development of software systems. Classically, data from one service is exposed to another via a REST interface. In one of us recently published blog posts we looked at how to implement an interface with gRPC. Here, gRPC relies on the variant of a remote procedure call, whereby the interface was predefined with Protobuf and thus enables typed function calls on target systems. This has certain advantages over a REST interface, since the interface was declared explicitly and the way in which a function call is made is comparatively faster.
If not REST or gRPC, then GraphQL!
There is another way in which one can alternatively expose data from a service; namely as a query language. The idea is that the search query, also called wuery, behaves identically to a query to a database or to a search engine such as Apache Solr. The search query only contains the search terms that are required for the respective case. One of the prerequisites for the target system is that it already knows and provides all possible search terms. This is exactly what GraphQL does - the query language for your future searchable API.
I beg you again?
GraphQL describes the structure of the interface in the following steps:
- Describe your data
|
|
Here a data type Project with 3 entries, the latter an array of type User. The entirety of all defined data types is called a schema and is explained again later.
- Search for what you want
|
|
This is a query. It looks for the tagline within the type project with the unique name “GraphQL”.
- Get understandable search results
|
|
The search result is structured exactly like Query and contains an existing tagline.
This is the simplest and fastest description of how a GraphQL interface should behave.
Advantages of a GraphQL interface
So, software systems require data exchange between the individual system components. Service A gets certain data from Service B. Often not all data exposed by Service B is actually needed in the business logic. Thus, the preparation and exposure of ready-made data structures - as is typically the case with a REST interface - is not always efficient. Sure, you can give the REST endpoint a certain number of parameters in order to get the desired result, but you are very limited and inflexible.
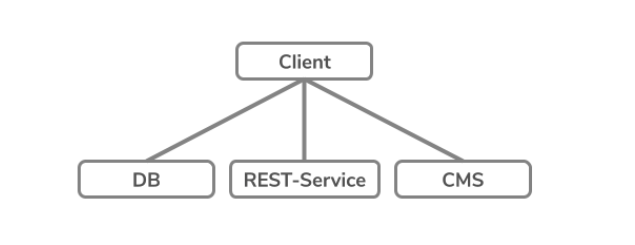
GraphQL offers an intermediate step in the form of a GraphQL server that aggregates all data sources and makes them available to the client.
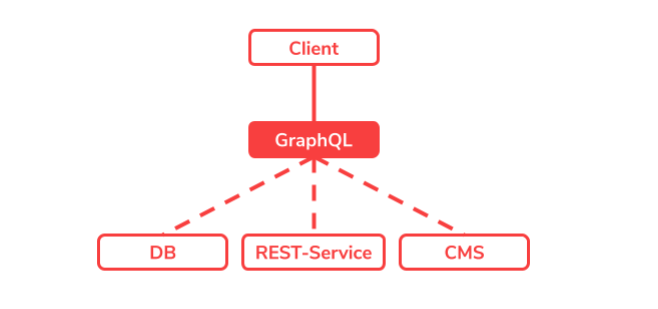
Typed graph with the GraphQL schema
The main part of a GraphQL implementation is the GraphQL schema, from here on it is simply called the schema. The schema is the domain definition of all fields connected in the graph. With every GraphQL interface there is a scheme that defines in advance what is available and thus determines what you can search for.
For example, the scheme for a blog post interface can look like this:
|
|
We can already see that there are different type definitions:
-
Query The
type Querydenotes a callable, ready-made query. In this case you can display all blog posts withgetAllBlogs()or a single blog post withgetBlogPost()whereby you can use an id parameter to give the unique identifier.Note: the Bang
!means that this value must be available. -
Mutation The
type Mutationdenotes a callable, ready-made function that can modify values in the interface. In the example you can create a new blog post viaaddBlogPost(). The parametertitle, thecontentand the unique author identifierauthorIDmust be given. -
Object An object is any structured type within the graph. In the example above with the blog interface, an object
BlogPostwith the fields id, title, content and hasAuthor and a second objectAuthorwith the fields id, name and hasBlog are defined. This can also be parsed and evaluated without a ready-made Query \ function. -
scalar A scalar type is any field within a structured object. In this case,
titleandcontentcan be a scalar field with typeStringwhich must not be zero. A scalar field can also be an array of individual scalar values.Note: The basic types for GraphQL are
Int(32-bit),Float(UTF-8),String,Boolean, and theID(serialized like a String).
For the sake of completeness, it should be noted that there are other types. These include Enums, Listen, Union, Interfaces, and Input Types. You can look them up in the official documentation about schema and types.
Underfetching and Overfetching
A second important advantage of GraphQL is the adequate resolution of the actually required data. Not too much, called Overfetching, but also not too little, called Underfetching, is delivered. Thus, the interface is efficient and, if implemented correctly, always better performing.
-
Underfetching is when not all data are delivered in a response. Often not all resources are output and only references to other resources are given, which requires further requests.
A REST API can, for example, provide CMS data. When calling the API end point
/cms/getAllBlogPosts?published=yes, not all the desired values, but references that would require further REST calls, would come back from the BlogPosts as a response. -
Overfetching is when more than the desired data is delivered in a response. This is the exact opposite of underfetching. This means that when a REST API is called, there are too many values in the response than desired and thus the interface would not be as efficient.
A quick word about caching
Of course, the question quickly arises whether GraphQL can also take over the caching of queries. The GraphQL server, which aggregates the data sets, does not save them. Therefore, client-side caching or even server-side caching must be implemented and taken into account separately.
Test a few queries with GraphiQL
GraphiQL is the official reference implementation of a GraphQL IDE. With it, you can write, test and analyze queries. The IDE can thus be made available for your own interface to provide a graphical user interface.
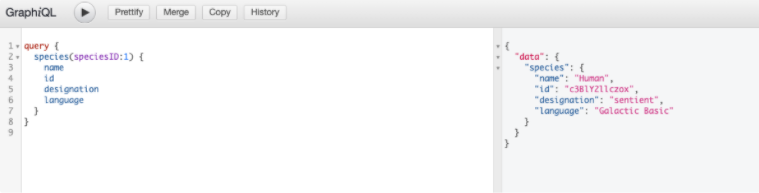
As you can see very nicely above, there is also a live demo of it, with which you can dare to take the first steps with GraphQL. With GraphiQL all possible queries can be tested and the schema can also be displayed in full. The scheme can be viewed in the window on the right. It looks something like this here:
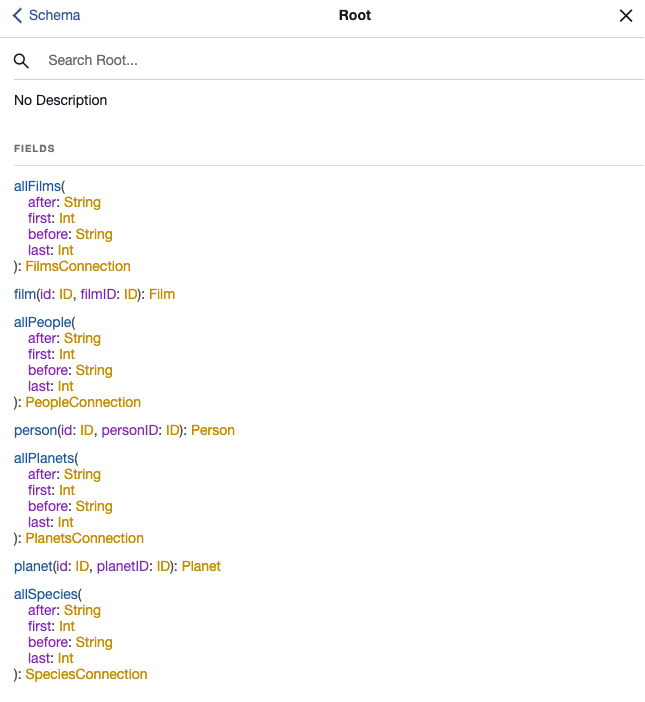
For the sake of experimentation I wrote the following query, which should output its name name, its identifier id, its name designation and its language language as the result for the species with speciesID:1.
|
|
The query, if executed correctly, delivers the following rather funny result:
|
|
The species with name “Human”, identifier “c3BlY2llczox“, description “sentient“ and language “Galactic Basic“ is the result self-explanatory.
So you always get exactly the data that you initially want to get via the query, no more and no less.
GraphQL is only a specification
You still have to implement GraphQL yourself. Fortunately, there are already established libraries that you can use, but basically the interface still has to be written by yourself.
The white paper of specifications is available on the official website and contains the complete definition of what a full-fledged GraphQL implementation must have. The first paragraph of the introduction reads as follows:
- “GraphQL is a query language designed to build client applications by providing an intuitive and flexible syntax and system for describing their data requirements and interactions.”
Implementation of a GraphQL interface
Write query resolvers
A resolver is a piece of code that resolves the values for a GraphQL object. In Java, a resolver is a Java class that inherits from a GraphQL resolver class and assembles the desired objects via the data connections (Connectors).
The schema definition
Let’s take a scheme that is supposed to expose blog posts via a GraphQL interface. The scheme would include a BlogPost object with at least a title and a field for the content. We want to have all blog posts aggregated via a query. It could look something like this:
|
|
So, we have the GraphQL schema and thus the domain definition. Now we want to provide our Java-based GraphQL server with resolvers in order to aggregate all this data. First we need to recreate the BlogPost object in Java. The best we can do is make a POJO class with the same name and fields:
|
|
Now we have to build an aggregation class that provides all BlogPosts.
This class is necessary because we will not use a database connection for the example and only provide the data as an example.
Let’s call the BlogPostRepository.
It manages all BlogPosts and can output them using a corresponding method getAllBlogPosts() and adds new BlogPosts using a method addNewBlogPost().
|
|
Now we have, so to speak, our data and its connection is mocked.
The next step is the resolver for the BlogPosts.
This implements GraphQLRootResolver (graphql-java) and bears the class name of the blogPostResolver object to be resolved.
This class implements our getAllBlogPost() query.
|
|
Now we can integrate this resolver in our interface.
For this we build a servlet that implements the SimpleGraphQLServlet class.
The targeted endpoint is /graphql.
We have to create an object of the type GraphQLSchema which has the Schema - file and knows the corresponding Resolvers, here the BlogPostResolver.
It looks like this:
|
|
Connect data sources
Usually you want to connect several data sources. To do this, you have to write a corresponding connector for each data source. The connector then transfers the necessary values to the respective resolver. The values are already known in advance via the domain definition of the GraphQL interface schema.
Finished implementations and tools
GraphQL was originally developed by Facebook. The story of its origins can be admired in an informative 30-minute documentary movie. The bottom line is that due to the complex requirements of the well-known Facebook wall, a more flexible and efficient interface to the actual data was required and a solution, now known as GraphQL, was worked on internally. In 2015 the implementation was made open source and the further development was shifted to its own GraphQL foundation. As for the Cloud Native Foundation, there is also a landscape for the GraphQL Foundation.
Since GraphQL is actually just a white paper, a specification, there are numerous implementations. Over time, certain libraries and implementations have proven themselves. Here is a small list of the ecosystem around GraphQL:
GraphQL ecosystem
-
Apollo is the reference implementation of a GraphQL platform Website: apollographql.com/ Git repo: github.com/apollographql
-
Java Libraries are available for Spring Boot, Quarkus and other JVM frameworks Quarkus: quarkus.io/guides/smallrye-graphql Spring Boot: github.com/graphql-java/graphql-java
-
Go-Libraries there are also more than one graphql-go: github.com/graphql-go/graphql
There is a lot more to write about GraphQL, but here we have explained the basics of how to use GraphQL and how to use it to design the appropriate interface for your next project.
Stay tuned!
Further links and resources
So what’s this GraphQL thing I keep hearing about? | freeCodeCamp
GraphQL concepts I wish someone explained to me a year ago | Naresh Bhatia @ Medium
GraphQL Explained in 100 Seconds | Fireship
Building Modern APIs with GraphQL | AWS Summit 2019
GraphQL: The Documentary | Honeypot
This text was automatically translated with our golang markdown translator.