With almost every application the question arises, where is my data stored? Do I need a cache? Is the database or location my bottleneck? Today we want to take a closer look at Redis, explore the advantages & disadvantages and explore the ideal area of application.
Redis
Redis describes itself as an open source, in-memory data structure store, which can be used as a database, cache or message broker. Simply put, there is a server running somewhere that takes over the storage of data that can be read very quickly.
In 2009, Redis, written in C, was born from the idea that a cache can also be a permanent storage location. Back then, Redis tried to solve the problem of slow relational databases by making cache & permanent storage a system.
So Redis is a Remote Dictionary Server, which reads and changes data very quickly via the RAM (Memory). At the same time, however, the data is saved on the disc, which is slower than the memory to be able to reconstruct data on a restart or the like.
One speaks here of hot values (RAM) and warm values (disk).
From a technical point of view, the data is stored in key-value pairs, whereby the value can consist of a wide variety of data types. By default, Redis supports the most common data types such as strings, lists, sets and maps (hashes).
Of course, Redis can also be operated in different high availability architectures. #Data storage How exactly does Redis store its data?
There are basically four different ways how Redis stores its data or how and when the data is available again.
No Persistence
The first and simplest storage is the no persistence or ephemeral storage. All data is lost as soon as the server is restarted. If you use an application cache without Redis, you usually have the same effect: the data is stored in the application’s memory, and everything is gone when you restart.
RDB
The so-called Redis Database allows us to persist data. The read and write operations are still handled in memory; a snapshot is also generated at a certain interval. A snapshot is also written with a normal, graceful shutdown. This snapshot is stored on a durable storage such as a file mount. By default, this is a JSON file, which is read in when the Redis server is restarted.
Advantages:
- simple, “normal” snapshot backup
- configurable interval
Disadvantage:
- There is a risk of minor data loss! If you configure the snapshotting to five minutes and there is an extraordinary shutdown of the server after four minutes, you lose the data from the last four minutes.
- With very large amounts of data, there may be peeks in the performance, since large amounts of data have to be written to a hard disk (disk IO)
AOF
The so-called Append Only File mechanism writes all write operations coming to Redis in a log and executes them again when the server starts. The same format is used for this as with the actual Redis protocol. An interval can also be configured here, by default the instructions are written every second (fsync). However, it can also be configured that every query is logged directly.
Advantages:
- No or little data loss
- Append Only Files cannot become corrupt and are always readable, no merge conflicts
- Automatic rewrite mechanism when files get too big
- All commands are simply stored and read in the correct order Disadvantage:
- Compared to an RDB dataset, the file size is larger here
- Depending on the fsync policy, the performance can be impaired with large amounts of data. With
every secondthe performance is still very good - The underlying process is slightly more complex and fragile compared to AOF
RDB + AOF
It is even possible to operate both types of memory in parallel. It should be noted here that the AOF file is used for the reconstruction in the event of a restart.
The advantages & disadvantages are difficult to quantify here, since the two mechanisms eliminate each other’s disadvantages.
In summary
Basically you should use both methods for data storage if you want to have data security similar to a PostgreSQL database. There are also use cases for each individual mechanism, but Redis recommends a combination of both.
In the long term, Redis wants to pack both methods into a Single Persistence Model so that the decision is made for the user.
Area of application
Cache
At that time, Redis was only called the Key Value Store and was used directly as the cache to cushion the performance-intensive calls to a database.
In most cases it is the case that the database, for example a relational SQL database such as Postgres, MySql or similar, is the bottleneck for performance. Typically, what is known as an in-memory cache is implemented, which is either located directly in the application or decentralized.
In the cloud environment, the decentralized approach, a so-called distributed caching, is suitable. This offers many advantages, among other things the cache can be used by several microservices at the same time. In addition, the cache is not lost when the application is restarted or deployed.
The application itself acts as a control center from which data source (cache (ephemeral) or database (durable)) the data is taken.
This approach is perfectly legitimate, but you have to be aware that you have multiple file locations, higher traffic with latency, and generally higher complexity.
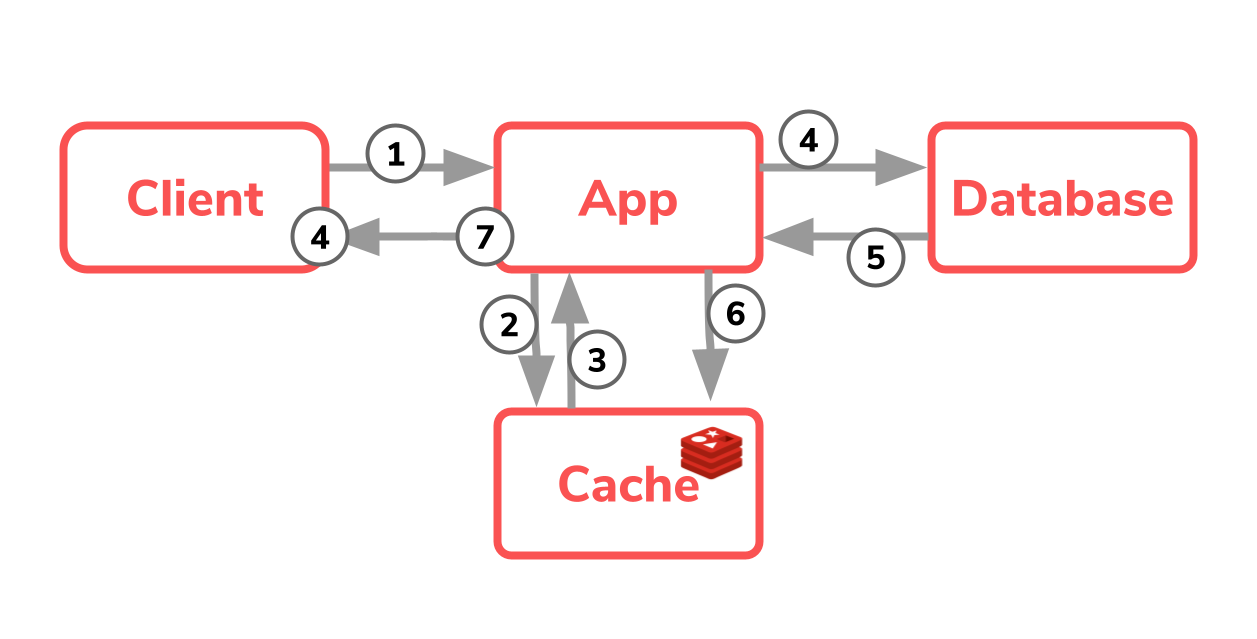
If we take a closer look at this architecture in detail, one quickly finds out that four or seven steps are necessary to query the data. The application accepts the user’s request and must first check whether the desired data is already in the cache. If these are available there, they can be returned directly to the user; the request could be processed very quickly in four steps.
However, if the data is not yet in the cache, the application must query the busy and slow database. The application then receives this data and fills it into the cache. The request could be processed in seven steps.
For the developer himself this architecture is important to understand and a constant “context switch” is necessary.
Basically, this architecture clearly has its raison d’être, for example if you cannot adapt the data source, if it is a soap or other web service or the like.
Primary data store
On January 8th, 2020, Redis published a blog post with the title Goodbye Cache: Redis as Primary Database. This made it clear where the journey should go, today Redis can and should be used entirely as the primary datastore.
Here you combine the cache and the data storage location from the first diagram and sort for a single process for writing and fetching the data.
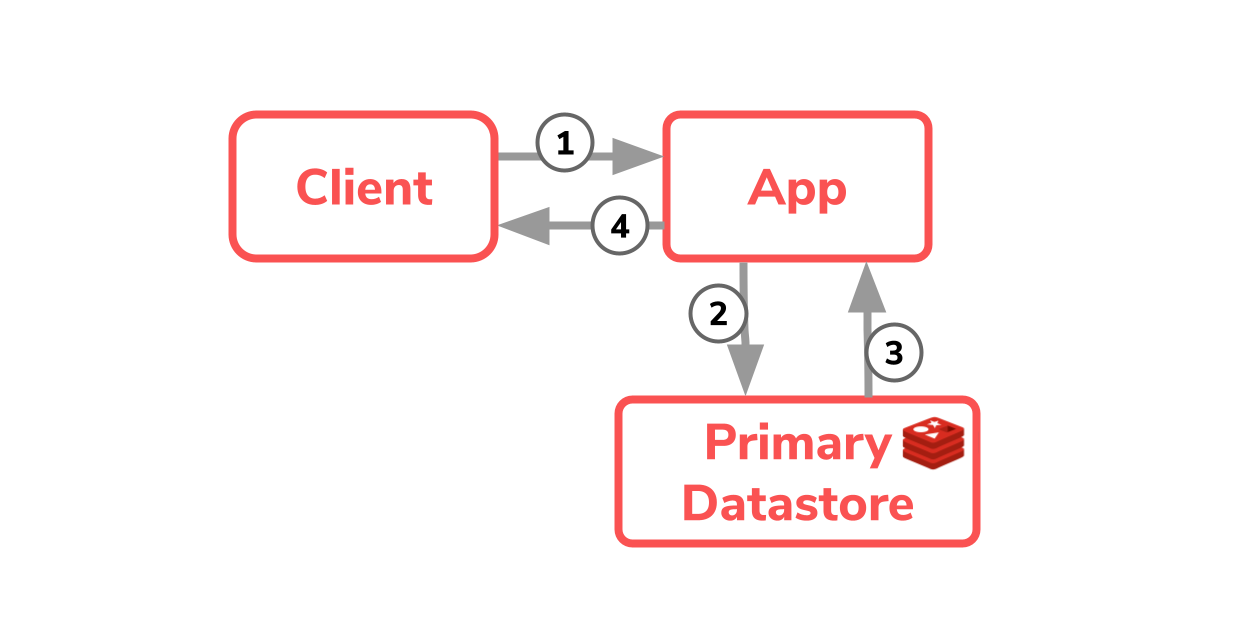
In this way, the data can be queried in just four steps, without any further functional or technical logic such as with caching in the application. In addition, Redis reflects the so-called Single Source of Truth, the data is only in one place.
The advantages of this solution are obvious:
- Simple data storage process, no context switching for the developer
- very fast, scalable, flexible, NoSQL data storage
- Strong and popular in the community, Redis was named Most loved database selected
As with every component in software development, you should ask yourself in advance whether Redis is the right solution. In most cases, the data structure and the complexity of the queries are very simple, Redis is made for this use case. If there are more complex data structures and, above all, queries such as joins etc., the use of Redis as the primary data storage should be reconsidered.
Except in very complex use cases, this approach does not actually have any disadvantages. If you configure the data storage of Redis yourself, you have a very fast in memory with 100% data security as the primary data source! 🚀
It is also important to mention that Redis can be expanded with so-called modules. For example, you can install a full text search or save JSON values directly in Redis. The modules are partially limited to the Redis Enterprise version.
Redis in practice
Now we want to look at both use cases in practice. In this TechUp we deliberately do not want to use Quarkus or Golang as an example application. Based on many years of experience and a specific use case with a customer, we want to get to know Redis in combination with Spring Boot.
In the example we use a Spring Boot Maven project, which we start directly via IntelliJ.
Redis runs in a Docker container, for the sake of simplicity we use:
|
|
Caching
First we want to write an exemplary Spring Boot application and cache it. We have already prepared a project for this, which exposes an end point /api/getvalue, receives a key and uses this key to read a value from a text file. The text file functions here as our database, we want to cache this call with the help of Redis.
The cache integration in Spring Boot is simple and easy, you need two Maven dependencies, a few configurations and an annotation.
An exemplary Redis Cache Configuration can be seen below:
|
|
We define a general cache of 10 seconds duration and then specify a custom cache with the name “keyValueCache” with a duration of 20 seconds.
By default, Redis connects via localhost:6379, of course this end point can be adjusted.
In a real world case, e.g. a dedicated endpoint can be used.
Now we have to annotate our method, which should be cached. It is important to note here that the cache only works if the method is called from outside, not from within the class. Spring Cache puts a proxy class in front of it in order to control and implement the cache handling.
This is how our Dao methods, which the file calls and reads, now look like:
|
|
Using this annotation, we simultaneously control which cache specification, here “keyValueCache”, is involved.
With a call to http://localhost:8080/api/getvalue?key=abc in the log we see that the Dao is called once and then, for 20 seconds, only the service.
|
|
Cool right? We implemented a distributed cache with Redis so easily and quickly! 🚀
Primary data store
Now we want to use Redis as the primary data storage device and store data about our favorite films there.
The dependency spring-boot-starter-data-redis provides us with both the spring data abstraction and the actual Redis client.
For this we first define a model and annotate it with RedisHash in order to be able to use this:
|
|
Then we use the CrudRepository interface from Spring Data and specify the generics for our own Dao interface.
The standard interface provides us with an abstraction for all necessary operations such as Create Read Update Delete.
|
|
And now we can use our Dao interface directly in the service, create new films and query films:
|
|
Here in this example we use the standard configuration of Spring Data Redis, of course this can also be adapted.
If we use the Redis CLI Command HGETALL Movie:1 we can take a closer look at our model in the Redis Datastore:
|
|
Here you can see that behind the key Movie:1 there is a kind of list, whereby the values are always alternating key/value values.
From this information, Redis can then use the Sprint Data Connector to reassemble the actual Java MovieModel.
Redis CLI
Last but not least, they want to take a closer look at the Redis container and familiarize us with the CLI.
If we connect to the container, we can start the CLI directly with redis-cli and get to know our Redis better with commands.
|
|
In the folder /data we find the snapshot or AOF files and can use them e.g. B. take a closer look or save.
Conclusion
Do you need a way to relieve your slow databases or to save simple data quickly and easily? Redis! 🚀
Depending on the UseCase, Redis offers you exactly the options you need!
Redis has certainly not for nothing been named Most loved database for the third time in a row, it is incredibly fast, easy to use and offers great security thanks to backup & reconstruction mechanisms.
In another TechUp we want to explore the differences between Redis, Etcd and TiKV in more detail.
Do you need support, have questions or would you like to initiate a discussion? Contact us!
This text was automatically translated with our golang markdown translator.