
Einführung
Unser Ziel war es, die hinter unserem TechHub steckende Infrastruktur weg vom Magnolia CMS in Richtung Cloud Native zu bewegen. Im Grunde geht es hierbei um das Re-Engineering, sprich die Neuentwicklung des bestehenden Status Quo von einer konventionellen CMS-basierten Architektur mit Magnolia hin zu einer Headless-CMS-Architektur, die das vielversprechende Jamstack-Pattern implementiert. Jamstack ist ein neuartiges Architektur-Pattern für Contentsysteme, wobei auf drei Grundpfeiler aufgebaut wird; JavaScript, APIs und Markdown. Falls du dazu mehr erfahren möchtest, haben wir ein dediziertes TechUp in Petto, in dem wir uns das Jamstack-Pattern genauer anschauen und den ganzen Solution-Stack dahinter beleuchten.
Diese Neuentwicklung hin zum Headless-CMS erlaubt uns, den Publishing-Prozess zu automatisieren und zeitgleich zu vereinfachen. Zudem ermöglicht uns die Wahl einer Jamstack-fähigen Architektur, Git-basiertes Content-Management zu betreiben, wobei der Content stets in Form von Markdown auf einem entsprechenden Git-Repository festgehalten wird. Dieser Markdown-Content kann somit stets über Git von einer Vielzahl von APIs abgerufen und genau in das gewünschte Format einer Zielplatform transformiert werden. Dies gibt uns zudem die Möglichkeit, neue Features unserer TechUp-Seite sowohl im Frontend als auch im Backend schnell implementieren und testen zu können. Das heisst die Time-to-Market ist auf ein Vielfaches reduziert, wodurch wir unsere Plattformen flexibler bespielen können. Um dieses Ziel zu erreichen, haben wir uns ganz im Sinne des bewährten GitOps-Pattern entlang gehangelt, welches wiederum schlanke CI/CD-Prozesse ermöglicht. Eine kurze Time-To-Market, sowie schlanke CI/CD-Prozesse, sprich Pipelines, heissen für uns mehr Agilität, operative Kostenreduktionen, bessere Visibiliät beim Debugging und allgemein das Gefühl cutting-edge Prinzipien und Pattern anwenden zu können. Zusätzlich konnten wir ja auch reichlich dabei lernen. :)
Das waren jetzt schmackhhafte Worte. Lass uns hier ein wenig konkreter werden und aufzeigen, was das für das Tooling bedeutet. Hierzu eine kurze und knappe Auflistung aller zentralen Aspekte des Tooling-Stacks:
- Die Migration des TechUp-Page-Frontends hin zu Microfrontends mithilfe von Angular auf AWS Amplify.
- Die Entwicklung diverser Golang-Microservices für die automatisierte Aufbereitung der Zielformate aller bestehenden, aber auch neuen TechUps, plus der Bereitstellung der containerisierten Workloads all dieser Microservices auf einem Kubernetes-Cluster.
- Die Entwicklung von CI/CD-Prozessen mithilfe von Github Actions (wir hosten unsere Git-Repositories sowieso bereits auf Github) zur Überprüfung, Verarbeitung und Weitergabe neuer TechUps.
- Die Provisionierung von Apache Solr-Instanzen und AWS S3-Buckets als zusätzliche Persistierungslayer neben Git, die die Gesamtarchitektur effizienter machen (Stichwort Availability, Scaling, Distributed Data).
- Das Verbinden all dieser Komponenten zu einer funktionierenden Gesamtarchitektur.
Um diese Gesamtarchitektur auf einen Nenner zu bringen, können wir hierbei von einer Git-basierten Implementation eines Jamstack-fähigen Headless-CMS sprechen, da wir nicht nur den Code, sondern auch den Content in einem Git Repository abspeichern. Mehr dazu kannst du gerne in unserem TechUp So geht Headless-CMS mit JAMstack lesen.
Übersicht der neuen Architektur
Die Entwicklung dieser Architektur bis zum jetzigen Stand hat viel Trial und Error benötigt. Oft möchte man etwas erreichen, braucht aber um das Ziel zu erreichen vielleicht einen anderen Microservice, der eine zusätzliche Transformation des Contents übernimmt. Schlussendlich sind wir aber bei einer sehr schönen Lösung angelangt, die ich jetzt genauer vorstellen werde. Schauen wir uns doch zuerst kurz an, was das ganze eigentlich tun soll.
Zusätzlich möchte ich kurz erwähnen, dass die Bezeichnung TechUp jeweils mit einem Blogbeitrag gleichzusetzen ist. Mit TechHub ist dann die Gesamtheit unserer TechUps und eben auch der Teil unserer Website gemeint, auf dem unsere TechUp’s zu finden sind.
Aufgaben der Architektur
Als starting-point haben wir wie so oft ein Github Repository als Single Source of Truth (SSOT), wo für jedes TechUp ein Ordner inklusive Illustrationen und dem eigentlichen schriftlichen Inhalt in Form einer Markdown-Datei namens content.md existiert.
Die Ordnerstruktur unseres TechHub-Repository sieht dann so aus:
|
|
Wichtig für das spätere Verständnis ist hierbei zu erwähnen, dass jede content.md-Datei einen Header mit essentiellen Metadaten besitzt. Der Header für unser TechUp namens “this-is-a-techup” könnte so aussehen:
|
|
Der slug ist zusammen mit der Sprache, die wir aus dem Dateipfad herauslesen können, sozusagen die “ID” unseres TechUps und wird im gesamtem Prozess zur Handhabung/Erkennung eines spezifischen Beitrags verwendet. Das hängt damit zusammen, dass der slug alleine noch kein Alleinstellungsmerkmal ist, da dasselbe TechUp mit demselben slug auf Englisch sowie auf Deutsch vorliegen kann.
Kommen wir zurück zu den Aufgaben der Architektur…
Wir haben also unsere SSOT mit dem Content. Nun kommen unsere Microservices ins Spiel. Die gerade besprochene content.md-Datei eines spezifischen TechUps soll nun zu HTML umgewandelt werden, um auf unserer Website dargestellt zu werden. Dieses HTML kann dann in Kombination mit den Metadaten vom Header als JSON in einer AWS EC2-hosted Apache Solr abgelegt werden. Nun sollen die Illustrationen aus dem Ordner extrahiert und in einem AWS S3 Bucket abgelegt werden. Die Arbeit der Microservices ist an diesem Punkt bereits erledigt. Schlussendlich lässt sich das TechUp auf unserer Homepage aufrufen - die Daten werden dann jeweils von unserem Angular Frontend aus dem Data Layer, also aus der Solr und dem S3 Bucket, gelesen und anschaulich dargestellt. Das könnte so aussehen:
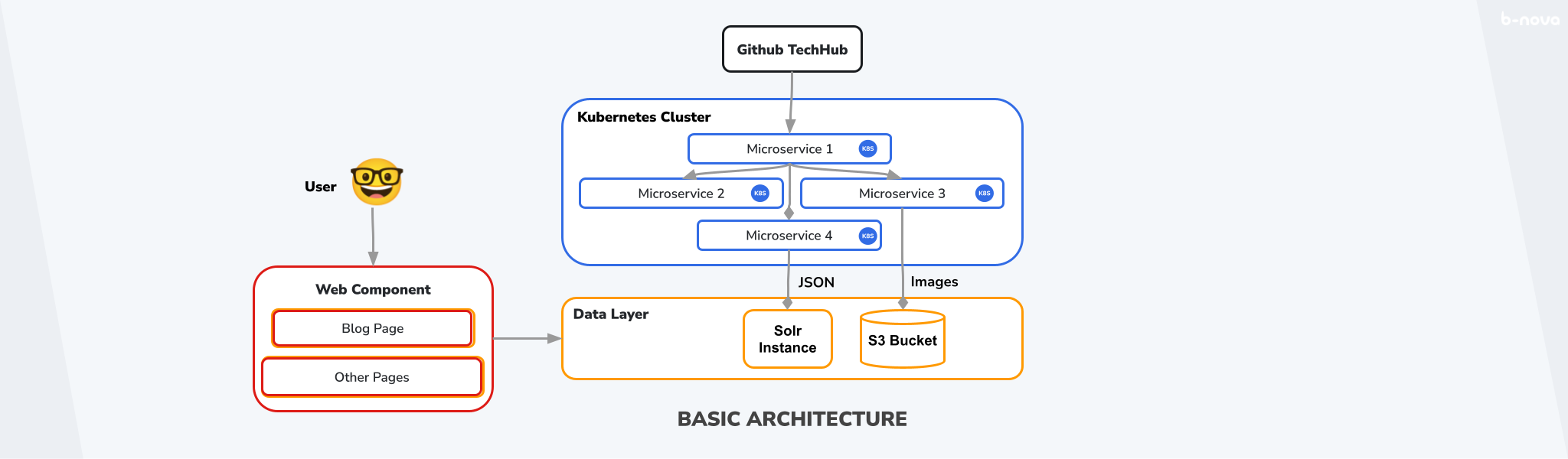
Figure: Grundsätzliche Architektur
An dieser Stelle möchte ich kurz erwähnen, dass es sich hierbei um einen Micro-Frontend-Ansatz handelt. Unter einem Micro-Frontend versteht man einen einzelnen, isolierten Teil einer gesamten Web-Applikation. Diese Micro-Frontends sind dadurch isoliert aufrufbar, beinhalten aber meist keine grundlegenden Standard-Komponenten wie beispielsweise einen Header oder einen Footer, sondern nur die spezifische, fachlich eingegrenzte Funktionalität einer einzelnen Seite. Auch zu diesem Thema haben wir natürlich bereits ein aufschlussreiches TechUp verfasst, welches du hier lesen kannst!
Nun erhöhen wir das ganze um eine Komplexitätsstufe, denn wir wollten noch einige Features einbauen, die uns wichtig waren.
Preview und Main Flow
Ziel war es, einerseits den gesamten Prozess testen zu können, und andererseits eine Vorschau des jeweiligen TechUps zu erhalten, bevor dieser zur Veröffentlichung auf unserer Website freigegeben wird.
Um das zu erreichen, duplizieren wir die Komponenten, also den Cluster, die Instanzen in unserem Data Layer und die Webkomponente und erhalten eine Kopie unseres Systems. Beide Systeme haben dasselbe Github Repository als SSOT und tun grundsätzlich dieselben Dinge. Das eine System, welches wir zum Testen und für die Vorschau verwenden, nennen wir “Preview Flow” und dessen Komponenten “dev” für development. Das System, welches die öffentlich sichtbare TechUp-Page erstellt, nennen wir “Main Flow” und dessen Komponenten “prod” für production. Das ganze sieht so aus:
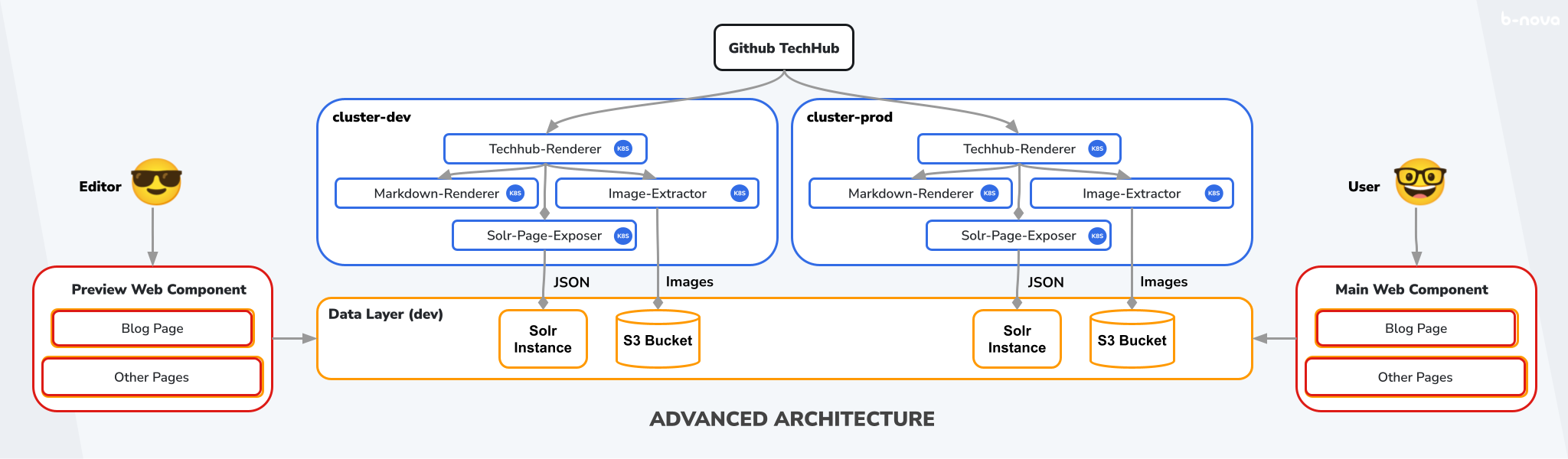
Figure: Fortgeschrittene Architektur
Da alle Komponenten ja exakte Kopien voneinander sind, müssen wir mit Hilfe von Umgebungsvariablen sicherstellen, dass dev-Komponenten, also die Microservices im cluster-dev und die Preview-Webkomponente jeweils auch die entsprechende dev-Solr-Instanz und den dev-S3-Bucket verwenden, damit die Systeme getrennt bleiben.
Aber woher soll unsere Architektur wissen, wann der Preview Flow und wann der Main Flow verwendet werden soll? Hier kommen Github Actions ins Spiel.
Github Actions
Mit Github Actions lassen sich Workflows erstellen, um Software Workflows zu automatisieren. Hier kannst du mehr über Github Actions erfahren.
Damit wir uns das bildlich vorstellen können, schauen wir uns am besten direkt die volle Illustration an. Hier noch einmal eine Zusammenfassung der Komponenten, die wir gleich etwas genauer betrachten werden:
- Github Actions (Schwarz)
- Kubernetes Microservices (Blau)
- Data Layer: AWS-hosted Apache Solr und AWS S3 (Orange)
- Angular Webkomponenten auf AWS Amplify (Rot)
Auf der folgenden Illustration sind die einzelnen Komponenten und deren Relation zueinander sichtbar. Anhand der Pfeilfarbe lässt sich erkennen, ob es sich um schreibende Operation (rot), lesende Operation (grün) oder um eine Aktivierung (grau) handelt. Hier nun eine Illustration der gesamten Architektur, wie sie aktuell bei uns im Einsatz ist:
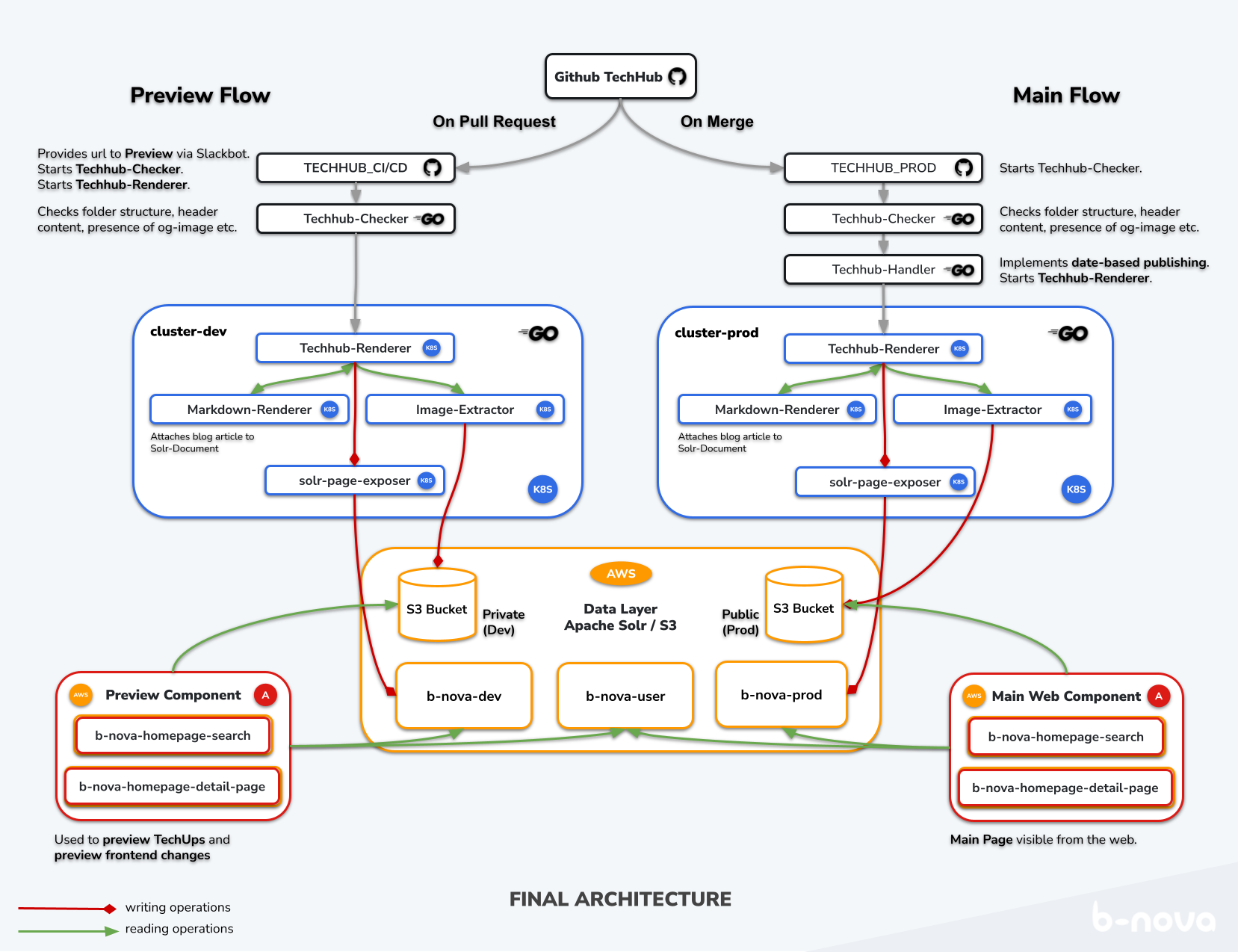
Figure: Aktuelle Architektur
Schauen wir uns jetzt also die einzelnen Komponenten genauer an. 😁
Preview Flow: TECHHUB_CI/CD
Diese Action startet automatisch sobald ein Pull-Request erstellt wird und ruft direkt den Techhub Renderer Service mit entsprechenden Parametern auf, der uns die Page generiert - vorausgesetzt der Techhub-Check war erfolgreich! Hier werden zudem die entsprechenden Umgebungsvariablen mitgegeben, die klarstellen, dass die Services aus dem cluster-dev verwendet werden sollen.
Ein Pull Request signalisiert, dass schon ein Branch kreiert wurde und Daten da sind, für die wir eine Vorschau generieren möchten, weswegen wir hier den PR als Startmechanismus verwenden.
So sieht der Trigger dieser Action in der cicd.yml Datei aus:
|
|
Techhub-Checker
Egal, ob der Preview oder Main Flow verwendet werden soll, die Techhub-Checker-Action wird immer ausgeführt. Schauen wir uns zuerst kurz an, was der Techhub-Checker tut.
Der Techhub-Checker ist ein Golang-Programm, welches von der Action ausgeführt wird und die Integrität unseres Repositories überprüft. Da wir hier unsere Single Source of Truth haben und dies der letzte Punkt ist, an dem Menschen involviert sind, möchten wir sicherstellen, dass jedes neue TechUp gewissen schematischen Vorgaben entspricht. Das ist besondert wichtig, damit bei der Weiterverarbeitung durch die Microservices keine Probleme entstehen.
Diese schematischen Vorgaben beinhalten Regeln bezüglich:
- Ordnernamen
- Dateinamen
- Angaben im Header der Markdown-Datei
Schlägt einer dieser Checks fehl, wird direkt im Pull Request eine entsprechende Fehlermeldung ausgegeben. Läuft diese Action erfolgreich durch, wird der Techhub-Handler (prod) beziehungsweise der Techhub-Renderer (dev) gestartet.
Main Flow: TECHHUB_PROD
Diese Action startet automatisch sobald ein Pull-Request geschlossen wird, oder alle vier Stunden, und startet - vorausgesetzt der Techhub-Check war erfolgreich - ein weiteres Golang-Programm, nämlich den Techhub-Handler. Auch hier werden wieder Umgebungsvariablen mitgegeben, in diesem Fall für den cluster-prod.
|
|
Du fragst dich vielleicht, wieso diese Action jeden Morgen um vier Uhr ausgeführt wird, und wieso dieser zusätzliche Schritt über den Techhub-Handler notwendig ist. Das hat damit zu tun, dass es auch möglich sein soll, TechUps automatisiert zu posten. Wie das funktioniert, schauen wir uns jetzt an.
Techhub Handler
Der Techhub-Handler ist für die automatisierte Veröffentlichung von TechUps zuständig und unterscheidet zwischen zwei Fällen:
-
Geschlossener Pull-Request: Handelt es sich um einen geschlossenen PR, wird das Datum des entsprechenden TechUps überprüft und falls es nicht in der Zukunft liegt, also veröffentlicht werden kann, wird der Techhub Renderer Service aufgerufen.
-
Main-Branch: Wird der Handler nicht durch das schliessen eines PR, sondern durch den vierstündigen Cron Job aufgerufen, liegt kein konkretes TechUp vor, dessen Datum überprüft werden kann. Das Datum jedes einzelnen Beitrags muss überprüft werden und es wird anhand von HTTP-Requests an die
b-nova-prod-Solr geschaut, ob der Beitrag bereits vorhanden ist. Ist der Beitrag noch nicht vorhanden, wird zur Veröffentlichung ebenfalls wieder der Techhub-Renderer Service aufgerufen.Dieser Fall ist dafür da, TechUps zu entdecken, die in Fall 1 ignoriert wurden, bei denen aber mittlerweile das Veröffentlichungsdatum nicht mehr in der Vergangenheit liegt.
Der Microservice Cluster
Die Golang-Microservices sind für wichtige Backend-Aufgaben zuständig und bilden gemeinsam einen Kubernetes-Cluster. Ob wir uns im Preview oder im Main Flow befinden, bestimmt an dieser Stelle nur (über Umgebungsvariablen), von welchem Cluster aus die Daten verarbeitet werden und dann in welche Instanzen unseres Data Layers geschrieben werden. Die Funktionsweise der Services unterscheidet sich ansonsten zwischen cluster-dev und cluster-prod nicht.
Schauen wir uns doch gleich mal an, was diese vier Services eigentlich jeweils tun.
Techhub-Renderer
Der Techhub-Renderer ist unsere Einstiegsstelle. Wir können ihn für unser Beispiel-TechUp mit diesem HTTP-Request starten: http://localhost:8080/getpage?slug=this-is-a-techup&lang=de.
Die getPage-Methode wird dadurch mit Parametern slug = this-is-a-techup und lang = de aufgerufen, holt und speichert sich das Repository lokal ab, und sucht durch Abgleichen des mitgegebenen Slug mit den jeweiligen Slugs aus den Headern aller .md-Dateien nach der richtigen Datei.
Wird diese Datei gefunden, wird ein StaticPage-Objekt erstellt, welches mit aus dem Header extrahierten Metadaten befüllt wird und später als Teil unseres JSON-Dokuments an die entsprechende Solr geschickt wird. Das Objekt sieht so aus:
|
|
Als nächstes wird der Inhalt der Body der .md-Datei, also alles nach dem Header, an den Markdown Renderer Service geschickt, dort von Markdown zu HTML umgewandelt und in unserer StaticPage unter Article gespeichert.
Nun müssen wir uns noch um die Illustrationen kümmern. Dazu wird der eben genannte HTML-Body mithilfe einer Regex nach HTML-Image-Tags (bspw. <img src="image1.png">) durchsucht, wobei die aus den Tags extrahierten Dateinamen in einem Array gespeichert werden. Für jeden Dateinamen in diesem Array wird ein Request an den Image Extractor Service gemacht, der uns die entsprechende Url zum Bild auf dem AWS S3 Bucket zurückliefert. Die src jedes Image-Tags wird nun durch die entsprechende Url, die zur selben Illustration, aber diesmal auf dem S3 Bucket, führt, ersetzt.
Das fertig “befüllte” StaticPage-Objekt wird nun zur Weiterverarbeitung in Form von JSON als HTTP-Post an den Solr-Page-Exposer-Service geschickt.
Wie du siehst, macht der Techhub-Renderer den Grossteil der Arbeit und ist sozusagen das Herzstück unseres Clusters. Die weiteren Services werde ich nur kurz beleuchten, da deren Funktion trivial ist.
Markdown Renderer
Der Markdown Renderer ist simpel und lässt sich unter http://localhost:8081/md aufrufen. Er kriegt Markdown-Text und liefert HTML zurück.
Image Extractor
Den Image Extractor verwenden wir, indem wir einen HTTP-Post auf folgende Adresse abwerfen und die jeweilige Illustration mitliefern: http://localhost:8082/upload?name="<ImageName>"&bucketName="<bucketName>"&imgPath="<imgPath>"&lang="<language>". Er kriegt also den Namen des je nach Flow mit Umgebungsvariablen definierten S3 Bucket inkl. weiterer Parameter und natürlich der Illustration selbst, lädt diese auf den Bucket an die richtige Stelle hoch und gibt die entsprechende URL zum Bild zurück.
Solr Page Exposer
Der Solr Page Exposer lässt sich verwenden, indem ein HTTP-Post mit dem fertigen StaticPage JSON-Objekt an http://localhost:8083/expose gemacht wird. Die Aufgabe des Page Exposers ist es, die fertige Seite in Form eines JSON-Objekts in die richtige Solr-Instanz einzuspeisen.
Fertig!
Frontend - Amplify Komponente
Da nun alle Daten auf unserem Data Layer vorhanden sind, kann die Angular Webkomponente bei einem Aufruf mit den entsprechenden Parametern (Slug und Sprache) das TechUp einwandfrei darstellen. Hurra!
Fazit
Ich hoffe, dass ich dir unsere Implementation eines Jamstack-fähigen Headless-CMS näherbringen konnte und die Vorteile einer solchen Architektur sowie die konkrete Funktionsweise unseres Publishing- und Preview-Systems nun etwas klarer sind. Falls du Lust auf weitere TechUps hast, kannst du dich gerne auf unserem TechHub umschauen - jetzt weisst du ja, was dahinter steckt. Und wie immer, stay tuned! 🔥