So setzen Sie Kafka in 5 Minuten auf Kubernetes mit Strimzi auf
Strimzi ist ein Tool womit einen vollwertigen Apache Kafka-Cluster inklusive Apache ZooKeeper auf Kubernetes oder auf OpenShift aufgesetzt werden kann. Strimzi ist ein Open Source-Projekt, dass von Jakub Scholz und Paolo Patierno von Red Hat betreut wird. Zudem ist Strimzi ein CNCF Sandbox Project. Heute schauen wir uns an wie Strimzi unter der Haube funktioniert und wie man damit Kafka in 5 Minuten aufsetzen kann.
Dies ist der zweite Teil in unserer Event-Driven Systems-Reihe. Im ersten Teil haben wir uns Apache Kafka angeschaut und wofür sich Kafka besonders eignet. Hier ein kurzes Recap der wichtigsten Punkte:
-
Kafka stellt in einem Rechnerverbund, genannt Cluster, Datenströme, genannt Streams, zur Verfügung
-
Microservices können einen solchen Stream effizient nutzen und halten somit Durchlauf und Latenz klein
-
Streams kennen Ordering, Rewinds, Compaction und Replication der Datenströme
-
Resilienz durch robuste Architektur, verteiltes System
-
Horizontales Scaling dank Cluster, ideal für verteilte, Event-basierte Systemarchitekturen
Kafka-Konfiguration mit Kubernetes Operator Pattern
Strimzi übernimmt die Konfiguration und das kontinuierliche Deployment der Kafka-Infrastruktur in Ihren Kubernetes-Cluster. Kubernetes bietet mit dem Operator Pattern die Möglichkeit eigene Ressourcen, sogenannte Custom Resources, zu definieren. Strimzi nutzt das Operator Pattern um die Konfiguration des gewünschten Kafka-Clusters vorzunehmen. Die Idee ist dabei, dass alle Einstellungen an Kafka in unterschiedlichen Operators festgelegt werden und diese Operatoren auf den Kubernetes-Cluster gespielt werden.
Strimzi sieht dafür 3 Operators vor: Ein Cluster-Operator und zwei Entity Operators. Die Entity Operators teilen sich in den Topic Operator und den User Operator auf. Die ganze Spezifikation ist auf der offiziellen Dokumentations-Webseite definiert.
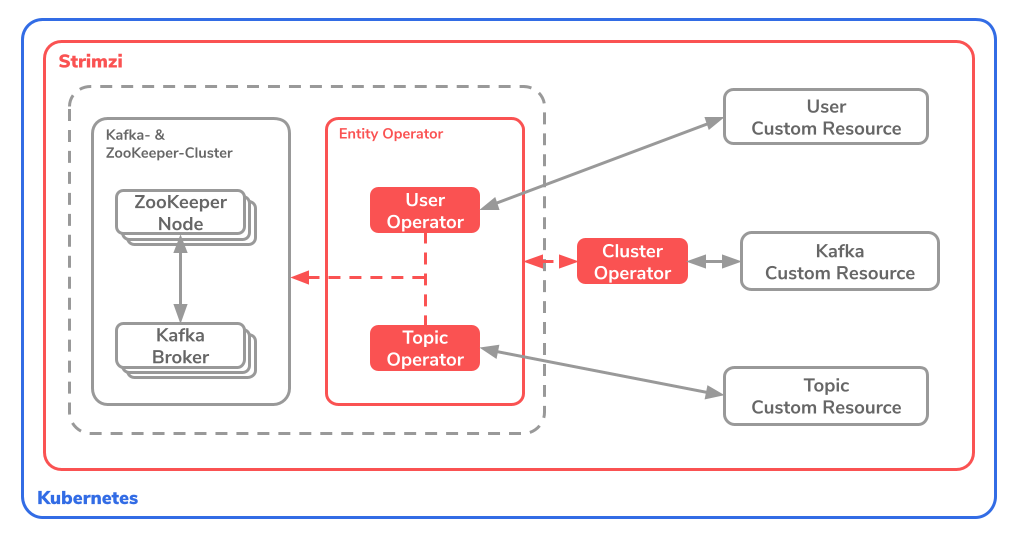
Die Idee dabei ist, dass Strimzi über die Operatoren (oben rot) die ZooKeeper-Nodes, die Kafka-Brokers sowie den ganzen Kafka-Cluster über die Custom-Resources (rechts im Bild) verwalten.
Cluster Operator
Der Cluster Operator dient zur Konfiguration des Kafka- und des ZooKeeper-Clusters, sowie den zwei Entity Operators. Somit ist der Cluster Operator zuständig für das Deployment der User- und Topic-Operators. Dafür werden Kubernetes Custom Resources genutzt.
Der Cluster Operator übernimmt auch die Konfiguration und Deployment von weiteren Kafka-Komponenten wie unter anderem aber nicht ausschliesslich von :
-
Kafka Connect
-
Kafka Connector
-
Kafka MirrorMaker
-
Kafka Bridge
-
und weitere Kafka-Ressourcen
Die Custom Resource sieht bei dem Cluster Operator wie folgt aus:
|
|
Hierbei ist ein Kafka-Cluster mit der Bezeichnung my-cluster und 3 Replicas konfiguriert.
Topic Operator
Der Topic Operator bietet die Möglichkeit KafkaTopics im Kafka-Cluster zu verwalten. Dies geschieht über Kubernetes Custom Resources.

Der Operator erlaubt 3 Grundoperationen:
-
Create: KafkaTopic erstellen
-
Delete: KafkaTopic löschen
-
Change: KafkaTopic modifizieren
Die Custom Resource für ein Topic Operator sieht beispielsweise wie folgt aus:
|
|
Hierbei ist ein KafkaTopic mit der Bezeichnung my-topic mit einer Partitions- und Replica-Menge von 1 konfiguriert.
User Operator
Der User Operator bietet, wie auch der Topic Operator, die Möglichkeit KafkaUser im Kafka-Cluster zu verwalten. Dies geschieht auch über Kubernetes Custom Resources.
Auch dieser Operator erlaubt 3 Grundoperationen:
-
Create: KafkaUser erstellen
-
Delete: KafkaUser löschen
-
Change: KafkaUser modifizieren
Die Custom Resource, kurz CR, für ein User Operator sieht beispielsweise wie folgt aus:
|
|
Wichtig zu beachten ist hierbei das operation-Feld auf der topic-Resource mit dem Namen connect-cluster-offsets. Da wird dem my-user-User über die CR die Rechte gegeben in das oben erwähnte Topic zu schreiben.
Noch ein Wort zur Storage
Da Kafka und ZooKeeper zustandsabhängige (stateful) Applikationen sind, muss der Zustand gespeichert werden können. Die Kubernetes Custom Resources die eine Storage-Property entgegen nehmen können sind der Kafka-Cluster Kafka.spec.kafka und der ZooKeeper-Cluster Kafka.spec.zookeeper. Strimzi unterstützt hierfür 3 Storage Types:
-
Ephemeral: Auf Deutsch flüchtig speichert der Ephemeral Storage Type die Daten nur solange die Instanz der Applikation läuft. Dabei werden
emptyDir-Volumen als Speicherzielort genutzt. Somit gehen die Daten verloren sobald der Pod sich neustarten muss. Dieser Storage Type eignet sich für die Entwicklung, nicht aber für produktive Einsätze. Insbesondere wenn der Replication-Wert von KafkaTopics 1 ist und/oder wenn Single-Node ZooKeeper-Instanzen.In der Resource-Definition für eine Entwicklungsumgebung könnte das etwa so aussehen:
|
|
-
Persistent: Der Persistent Storage Type, wie der Name bereits ahnen lässt, erlaubt dauerhaftes, Instanz-übergreifendes Speichern der Laufzeitdaten. Dies geschieht über die Kubernetes-eigene Persistent Volume Claims, kurz PVCs. Wichtig ist hier zu beachten, dass das Verändern der zugewiesenen Speichereinheiten nur verändert werden kann, wenn der Kubernetes-Cluster Persistent Volume Resizing unterstützt.
In der Resource-Definition einer unveränderbaren Persistenz könnte das etwa so aussehen:
|
|
-
JBOD: Der letzte Storage Type ist ein Acronym für Just a Bunch Of Disks und eignet sich nur für den Kafka-Cluster und nicht etwa für die ZooKeeper-Instanz. Kurz gefasst abstrahiert JBOD die beiden obigen Speichertypen und kann dadurch beliebig vergrössert, bzw. verkleinert werden. Dieser ist sicher der geeignetster Storage Type für einen skalierbaren Kafka-Cluster, da dieser zur Laufzeit beliebig angepasst werden kann.
In einer JBOD-Spezifikation könnte die Resource-Definition wie folgt aussehen:
|
|
Beim Aufsetzen eines Kafka-Clusters mit Strimzi kann man somit einfach die Storage Types wie gerade erforderlich einfach und bequem über Kubernetes-eigene CRDs definieren. Vorerst muss berücksichtigt werden welche Anforderungen die Applikation an den Kafka-Cluster hat und dadurch entscheiden welche Storages Types für den Cluster in Frage kommen.
Aufsetzen eines Kafka-Clusters
Jetzt wird es ernst. Um mit Strimzi eine Kafka-Infrastruktur auf dem Kubernetes-Cluster zu erzeugen, brauchen wir zuerst einmal eine lauffähigen Cluster. Dies kann direkt auf einem in der Cloud gehosteten Cluster erfolgen oder alternativ auch lokal mit minikube.
Verbinden Sie sich zuerst mit Ihrem Kubernetes-Cluster. Stellen Sie sicher, dass sie per kubectl mit ihrem Kubernetes-Cluster verbunden sind. Erstellen Sie danach einen kafka-Namspace auf dem Cluster. Dies kann man ganz einfach aus dem Terminal mit der kubectl-CLI machen.
|
|
So jetzt haben wir einen Namespace mit dem Namen kafka. Danach möchten wir die Custom Resource Definition, kurz CRD, von Strimzi einspielen. Diese CRD ermöglicht es den Syntax von Kubernetes-nativen Custom Resources um Strimzi-spezifische Definitionen zu erweitern. Diese CRD können Sie bei Interesse unter https://strimzi.io/install/latest näher untersuchen.
Die von Strimzi offiziell zur Verfügung gestellte Installationsdatei, welche ClusterRoles, ClusterRoleBinding sowie weitere Custom Resource Definitions über die CRD erstellt ist hierbei das Herzstück der Strimzi-Installation.
|
|
Applizieren Sie danach das vorgefertigte Manifest an, welches den Kafka-Cluster mit all den Konfigurationen der Kafka-Topic/-User vornimmt.
|
|
Dies ist eine exemplarische Konfiguration, die bei ihrem Real-World Projekt angepasst werden müsste. Die hier genutzte Custom Resource für den Kafka-Cluster ist im Manifest kafka-persistent-single.yaml definiert.
|
|
Zur Erläuterung: wie man aus dem obigen Manifest entnehmen kann wird hier ein Kafka-Cluster my-cluster mit Kafka in der Version 2.7.0, zwei Ports 9092 und 9093 konfiguriert. Hierbei wird im im config-Feld gewisse Kafka-spezifische Configs definiert, die Storage Type ist hier jbod mit einer persistent-claim von 100Gi. ZooKeeper mit einer Instanz wird ebenfalls angegeben. Die topic- und user-Operatoren sind leer initialisiert.
Sie können das Hochfahren der Pods realtime anschauen:
|
|
Prüfen Sie ob der Kafka-Cluster korrekt hochgefahren ist:
|
|
Glückwunsch! Sie haben erfolgreich mit Strimzi hoffentlich unter 5 Minuten eine Kafka-Instanz mitsamt ZooKeeper auf Ihrem Kubernetes-Cluster aufgesetzt.
Testen des Kafka-Streams
Da der Kafka-Cluster per Strimzi nun lauffähig ist, möchten wir per Kafka-Stream eine oder mehrere Messages in ein Topic schreiben und diese als Consumer irgendwo entgegen nehmen. Dafür gibt es ein nützliches Docker-Image von Strimzi, quay.io/strimzi/kafka, welcher wahlweise ein Producer oder Consumer als Service bereitstellen kann.
Erstellen wir zuerst einen generischen Producer-Service mit dem folgendem Ausdruck:
|
|
Der Consumer führt das Shell-Script bin/kafka-console-producer.sh aus und erstellt dabei ein KafkaTopic mit dem Namen my-topic. In einer interaktiven Prompt können Sie beliebige Werte in den Stream des Topics schreiben.
In nächsten Schritt erstellen wir in einem zweiten Terminal-Fenster einen zweiten, generischen Consumer mit dem gleichen Docker-Image per folgendem Befehl:
|
|
Wie auch vorhin führt dieser Producer ein Shell-Scipt bin/kafka-console-consumer.sh aus, wobei das Topic my-topic angesprochen wird. Es werden alle Messages von Beginn an (--from-beginning als Parameter) empfangen und verwertet.
Falls Sie bereits Werte in den Producer geschrieben gehabt haben, sollten diese im der Consumer-Prompt ausgeloggt werden. Falls nicht, schreiben Sie welche in den Producer und schauen Sie danach im Consumer nach. Wenn alles richtig funktioniert, sollte die eingetippten Messages über den Kafka-Cluster im Stream übergeben werden. Glückwunsch ! So schwer war das Ganze doch nicht, oder?
Custom Konfiguration des Kafka-Cluster
Strimzi stellt in ihrem offiziellen GitHub eine vollwertige Repo zur Verfügung worin Vorlagen von unterschiedlichsten Custom Resources Definitions und Konfigurations-Manifesten vorhanden sind. Laden Sie sich am besten das Repo per Git oder auch per .zip herunter.
Custom Resource Defintion definieren
In der Repo gibt es ein install/cluster-operator-Verzeichnis. Darin sind unterschiedliche yaml-Dateien womit die Custom Resource Definition konfiguriert werden. Falls man erneut die Custom Resource Definition auf einem eigenen Namespace einspielen möchte, genügt es die Konfigurationen in diesem Verzeichnis vorzunehmen, den Wert STRIMZI_NAMESPACE mit dem verwendeten Namespace-Namen in der Datei install/cluster-operator/060-Deployment-strimzi-cluster-operator.yaml ersetzen und den folgenden kubectl-Befehl gegen ihren Kubernetes-Cluster ausführen:
|
|
Beispiele für Kafka-Resourcen
Wie weiter oben bereits beschrieben gibt es grundsätzlich 3 unterschiedliche Ressourcen, die wir für Kafka konfigurieren möchten:
-
Kafka
-
KafkaTopic
-
KafkaUser
Im Verzeichnis examples/ findet man unter anderem 3 Unterverzeichnisse mit Beispiel-Manifesten für genau diese 3 Resources, die man per kubectl-CLI einspielen lassen kann. Die Verzeichnisse sind respektiv examples/kafka/, examples/topic/ und examples/user/. Einfach raussuchen, konfigurieren, einspielen und am besten mit GitOps-Pattern im Cluster einbauen, sodass der Kafka-Cluster so transparent und robust wie möglich laufen kann.
Kubernetes-fähige Erweiterungen
Strimzi stellt die Nutzung von Kubernetes-nativen Features zur Verfügung. Dabei greift Strimzi auf folgende bekannte Cloud-Native Projekte zurück:
Kafka in der Cloud mit Amazon MSK
Noch ein Wort zu alternativen Lösungen zu Strimzi: Cloud-Anbieter wie AWS bieten auch die Möglichkeit über einen Haus-eigenen Service einen Kafka-Cluster nutzen. Bei AWS heisst dieser Service MSK, kurz für Managed Streaming for Apache Kafka. MSK lässt dabei einen vorgefertigten, komplett konfigurierbaren Kafka-Cluster auf einer EC2-Instanz laufen.
Grundsätzlich kann man damit einen Kafka-Cluster per AWS CLI aufsetzen und mit JSON-Dateien die gewünschte Konfiguration einspielen lassen.
Fazit
Strimzi vereinfacht stark das Aufsetzen einer vollwertigen Kafka-Infrastruktur auf einem Kubernetes-Cluster. Dabei können alle Konfiguration in einer Git-Repository zusammengefasst werden und idealerweise per GitOps-Pattern auf den jeweiligen Cluster neu ausgerollt werden. Strimzi reduziert somit gewaltig die Abstraktion der Verwaltung eines Kafka-Cluster in der Cloud. Daumen hoch und stay tuned!
Weiterführende Ressourcen und Quellen
https://strimzi.io/documentation/
https://itnext.io/kafka-on-kubernetes-the-strimzi-way-part-1-bdff3e451788
https://www.youtube.com/watch?v=RyJqt139I94&feature=youtu.be&t=17066