
Was ist eigentlich eBPF? - Ein kleiner Reminder
GNU/Linux ist in der IT-Welt weit verbreitet und findet gerade als Server-Betriebssystem beliebte Anwendung. Das Betriebssystem ist ein Vorzeige-Open-Source-Projekt und ist über Jahrzehnte durch die innovative und breit aufgestellte Kernel-Entwicklung populär geworden. Dabei spielt der ursprüngliche Entwickler Linus Torvalds eine ganz zentrale Rolle, da er jeden Merge-Request des Linux-Kernels selber reviewed, und somit eine wichtige Instanz in der Linux-Kernel-Entwicklung spielt. Eines der Nachteile davon ist, dass die Kernel-Entwicklung dadurch lange Release-Zyklen für neue Features aufweist.
Ein Feature, welches seit der Linux-Version 3.18 im Jahr 2014 ausgerollt wurde, ist dabei eBFP. eBFP bietet die Möglichkeit, eigens geschriebene Logik direkt im Kernel-Space auszuführen, ohne dass der eigentliche Kernel selbst gepatched werden muss. Dieser Code, der sich per eBFP auf Kernel-Ebene ausführen lässt, wird dabei in einer eigenen isolierten Umgebung interpretiert. Das Ganze hat der Vorteil, dass sich Software schreiben lässt, die direkt im Kernel und somit möglichst low-level, direkt am Geschehen ausgeführt werden kann.
Es gibt zahlreiche Applikationsfelder, welche sich durch diese Technologie ergeben. Heute geht es aber nicht darum, was eBPF alles ermöglicht, sondern darum, wie wir eigene eBFP-Programme schreiben und wie man diesen am besten verpacken können. Falls dich das Thema eBFP und dessen Anwendungsfelder doch weiter interessieren sollte, dann schau doch in unsere eBFP-TechUp-Beiträge rein, welche wir schon mehrfach dazu geschrieben haben. Dabei sind folgende TechUps nennenswert:
Bumblebee als Build-Tool für eBFP-Logik
Wie schreiben wir am besten eigenen eBPF-Code? Eine Möglichkeit - die beste, die ich genau für diesen Use-Case eruieren konnte - ist Bumblebee. Bumblebee ist eigens dafür entwickelt worden, eBFP-Logik zu schreiben, builden und anschliessend in ein nutzbares Paketformat zu bringen, sodass sich das geschrieben Artefakt auch mit anderen einfach und leicht teilen kann.
In der jetzigen Ausführung übernimmt Bumblebee zwei wichtige Dinge:
- 1. Initialisierung eines eBPF-Programms anhand von vorgefertigten Templates: Bumblebee beinhaltet einen Init-Prozess, mit dem sich in der CLI ein eBPF-Programm vorfertigen lässt, mit dem man sich im Anschluss nur noch auf die eigene Business-Logik fokussieren kann.
- 2. Paketierung des Build-Artefakts anhand eines OCI-konformen Formats: Sobald die eigene Business-Logik geschrieben und getestet wurde, portiert Bumblebee das ganze Build-Artefakt in einem Paketierungsprozess in ein OCI-komformes Format, welches sich auf die gängigen Container-Registries hochladen lässt.
Wie wir soben festgehalten haben, vereinfacht Bumblebee den Entwicklungsprozess von eBFP-Logik stark. Neben dem Template-basierten Initialisieren, sowie der Paketierung des fertig gebauten Build-Artefakts, stellt Bumblebee aber auch weitere Konzepte zur Verfügung, mit denen man bei der Verwendung rechnen darf.
- Art und Weise, wie der eBPF-Filter getriggered wird
- Output-Typ: Aktuell gibt es Logging im Form von einem Print-Typ, und Metriken in Form von Count- und Gauge-Typen
Diese Bumblebee-spezifischen Eigenschaften kann man im offiziellen README.md nachlesen. Da Bumblebee sich noch in der Entwicklung befindet, kann sich diese Dokumentation in der Zwischenzeit erheblich verändert haben. Ich hoffe aber zumindest, dass die Grundkonzepte bis Dato noch an Gültigkeit behalten. Nun schauen wir uns das ganze einmal praktisch an.
Eine eBPF-Probe selber schreiben
Wie so oft bei b-nova; wenn wir uns eine neue Technologie anschauen, und diese auf Lunge und Niere prüfen, machen wir gleich den Kopfsprung und schreiben uns eine eigene eBPF-Probe mithilfe von Bumblebee. Aber bevor wir das machen können, müssen wir einige Dinge vorinstallieren.
Voraussetzungen
Für dieses TechUp brauchen wir eine GNU/Linux-Umgebung; da eBPF eine Technologie ist, welche auf dem Linux-Kernel fusst, funktioniert dies auch nur auf Linux. Da ich einen MacBook Pro als mein Gerät der Wahl nutze und dieser nicht mit einem Linux-Kernel daherkommt, muss ich mir eine Linux-Umgebung virtualisieren. Ursprünglich wollte ich die Virtualisierung mit einem Vagrantfile vornehmen und diese mit einem VMWare Fusion-Treiber ansteuern. Dieses Vorhaben war ziemlich zeitintensiv und kombiniert mit dem verbauten M1-Prozessor, sowie dem neuen Ventura 13.0-Update, musste ich auf eine einfachere Lösung ausweichen, um mir ein Linux System zu beschaffen.
Dabei kam mir Canonical, die Firma hinter der bekannten Ubunutu-Linux-Distribution, und deren Multipass recht gelegen. Im Handumdrehen konnte ich mir ein Ubuntu starten, welches einfach per MacOS-Terminal ansprechbar war. Somit baut dieser Guide auf der Vorraussetzung auf, dass ein Ubuntu-System zur Verfügung steht. Obwohl dieser Guide grundsätzlich mit jeder Linux-Distribution möglich ist, habe ich eben nur die Ubuntu-Fassung selbst getestet.
Die Linux-Umgebung bequem per Multipass erstellen (optional)
Multipass ist eine 1-Click Ubuntu-basierte Virtualisierungsumgebung. Diese lässt sich auf MacOS komfortabl mit brew wie folgt installieren:
|
|
So, Multipass ist installiert. Jetzt rufen wir die Applikation per Launcher einfach auf. Im Icontray gibt es jetzt neu ein Multipass-Icon. Mit einem Rechtsklick drauf bekommen wir die Möglichkeit, eine Shell direkt auf der Ubuntu-Maschine zu eröffnen.
Falls du diese Shell zu sehen bekommst und der ubuntu-User auf dem primary-Host angemeldet ist, dann sind wir bereit, den nächsten Step zu machen und installieren uns sogleich Bumblebee.
Bumblebee Installation
Wie bei so vielen neuen IT-Technologien, gibt es auch für Bumblebee ein sogenanntes Convenience-Script, also ein Shell-Skript, welches man sich über einen Einzeiler herunterladen kann, das die gewünsche Software in kürzester Zeit auf die Platte schreibt.
Um sich die Bumblebee-Umgebung auf das Ubuntu (oder deine Linux-Distribution der Wahl) zu installieren, kann das Convenience-Script wie folgt ausgeführt werden:
|
|
Das Ausführen führt zu einem Vorschlag, dass man das .bumblebee-Dotverzeichnis im Home-Verzeichnis gleich im eigenen PATH aufnimmt.
|
|
Da ich auf einer VM unterwegs bin und die Maschine nach meinem Test wieder herunterfahre, bin ich nicht daran interessiert, den PATH zu persistieren und mache ganz einfach einen Export mit dem vorgeschlagenen Wert.
|
|
Um zu testen, ob die Aufnahme von Bumblebee im Path geglückt ist, können wir ganz einfach bee version in unsere Shell eingeben (Bee ist der Name des CLI-Tools von Bumblebee).
|
|
Wir erhalten zwar keine Versionsnummer, aber ich gebe mich mit dem Wert dev zufrieden, gerade auch deswegen, da bee offensichtlich meiner Shell bereits bekannt ist.
Bee Initialisierung
So, jetzt sind wir soweit; Wir haben eine lauffähige VM, die Bumblebee-Umgebung ist installiert und wir konnten uns mit bee schonmal anfreunden. Wie eingangs schon gesagt, bietet Bumblebee die Möglichkeit, über eine interaktive CLI ein Template für unsere “Probe” zu generieren.
Diesen Prozess können wir mit bee init anstossen. Da das CLI-Tool komplett interaktiv ist, habe ich mir erlaubt eine GIF-Animation davon zu schiessen, sodass deutlicher wird, was genau gemacht werden muss.
Natürlich möchte ich die einzelnen Schritte der Bee-Initialisierung durchgehen und dir zeigen, was in jedem Schritt genau im Hintergrund gemacht wird.
1. Schritt — Programmiersprache
Nach dem bee init kommt somit gleich die erste Frage auf:
|
|
Da man nur die Möglichkeit hat, C als Programmiersprache auszuwählen, erübrigt sich eigentlich was man auswählen sollte. Es ist laut Eigenaussage von den Entwicklern angedacht, dass in naher Zukunft auch Rust als zweite Programmiersprache angeboten wird. Zum Zeitpunkt von diesem TechUp ist dies aber noch nicht möglich. Somit kann man einfach mit “Enter” in den nächsten Step hinüber gehen.
2. Schritt — Prozesstyp
Der nächste Schritt fragt nach dem Typ von eBFP-Programm, welches geschrieben werden soll.
|
|
Grundsätzlich muss man hier eBPF als Technologie ein wenig besser verstehen, denn es geht ja beim Programmieren eines eBFP-Filters darum, dass man im Kernel-Space Logik einschleust und diese zur Laufzeit des Betriebssystems gewisse Prozesse evaluiert. Eine Separierung dieser Prozesse aufgrund von Netzwerk-basierten und Dateisystem-basierten Zugriffen ist insofern gegeben, da eBFP den einen oder den anderen Zugriffstyp als Einstiegspunkt ansieht. In anderen Worten geht es darum, wofür unsere Logik dienen soll. Lass uns mal festhalten, dass wir jegliche Netzwerk-Zugriffe auf Kernel-Ebene überprüfen möchten, und somit die erste Auswahlmöglichkeit Network mit Enter bestätigen.
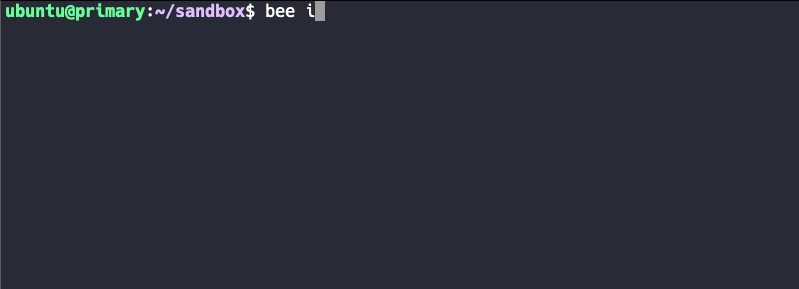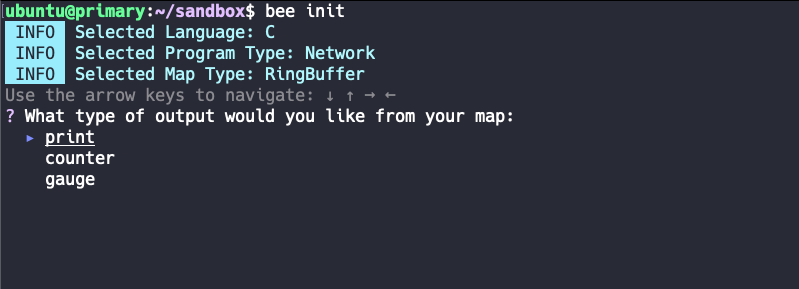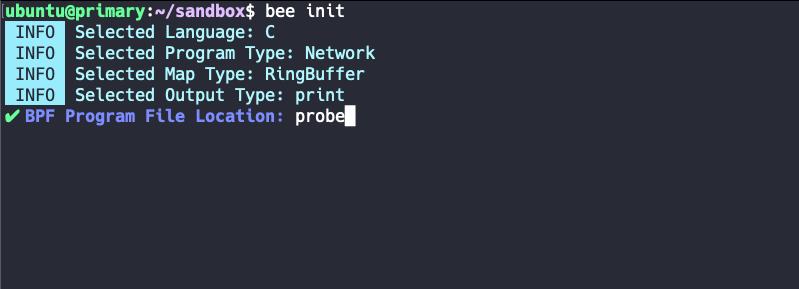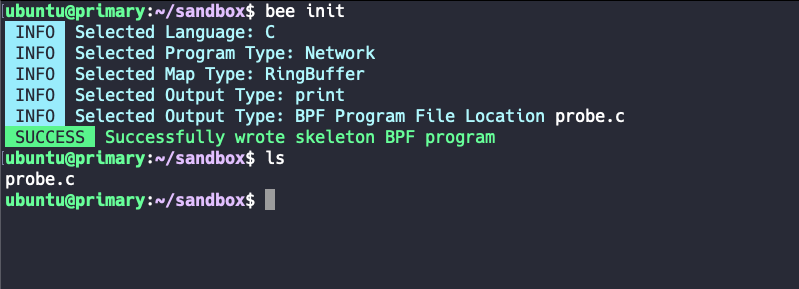
3. Schritt — Map-Typ
Dieser Schritt ist kein offensichtlicher. Hier wird gefragt, welche Art von Map genutzt werden soll. Zur Auswahl stehen RingBuffer und HashMap.
|
|
Dabei geht es um die Art und Weise wie die eBPF-Logik, die auf Kernel-Ebene auf Prozesse hört, mit dem User-Ebene-Teil von der Bumblebee-Laufzeitumgebung kommuniziert. Das heisst, dass die Information, die der Nutzer auf User-Ebene zu Gesicht bekommt bereits verarbeitet ist und in einem gegeben Format (hier “type”) vorliegt. Dieser Typ muss eingangs bestimmt werden, sodass Bumblebee den korrekten Typ kennt. Für unseren Filter wählen wir RingBuffer, da der Typ für unseren Use-Case nicht eine allzu grosse Rolle spielt.
4. Schritt — Output-Typ
Genau wie beim vorherigen Schritt wird hier ein Formattyp gewählt. Zur Auswahl stehen hier zum Zeitpunkt dieses TechUp die drei Typen print, counter, und gauge.
|
|
Als der Map-Typ aus dem vorherigen Schritt bestimmt wurde (wir hatten ja RingBuffer gewählt), ging es darum, wie die Bumblebee-Logik zur Laufzeit zwischen Kernel- und User-Space kommuniziert. Hier bestimmt der Output-Typ das Format der Information, welche über den Kommunikationskanal übergeben wird. Wir bestimmen hier also, welche Art von Information wir gerne aus der eBPF-Logik erzielen möchten.
Der print-Typ liefert dabei Text als Output-Format und eignet sich somit als Grundlage für jegliche Art von Logging-Mechanismen. counter und gauge sind beide Zahlenbasierte Output-Formate, welche sich eher für Metrikbasierte Mechanismen eignen. Hier wählen wir das konventionelle print-Output-Format.
5. Der letzte Schritt — Naming
Nach Bestätigung mit Enter, sollte nun noch eine letzte Eingabaufforderung kommen, nämlich wie unser Sourcefile, und somit die zu generierende Vorlagedatei heissen soll. Wir nennen das nach phlegmatischer Software-Entwickler-Manier einfach mal my_filter.c.
|
|
Der Filter
Wenn wir unser Verzeichnis inspizieren, finden wir eine neue Datei. Diese heisst hoffentlich my_filter.c, welche nach einem cat/less/vim oder einem ähnlichem Darstellungsbefehl wie folgt aussehen sollte.
|
|
Hoffentlich verstehst du ein wenig C, ansonsten wird diese Datei ein wenig obskur aussehen. Lass uns hier kurz rekapitulieren, was wir genau vorfinden sollen. Wir wissen, dass uns bee init eine my_filter.c-Vorlagedatei generiert hat. Über fünf verschiedene Parameter der CLI lässt sich der Filter invidiualisieren. Diese Parameter bestimmen die Programmiersprache der Vorlage (hier .c), den Prozesstyp, auf den der Filter reagiert (Network), die Kommunikationsart zwischen Kernel- und User-Space (RingBuffer), der Formattyp des Outputs bei dieser Kommunikation (print) und schlussendlich den Namen der zu generierenden Datei (my_filter.c).
Soweit, so gut. Lass uns jetzt diese C-Datei bauen und schauen, was wir rauskriegen.
Bee Build
Jetzt machen einen bee build, welchen wir noch ein wenig parametrisieren wollen. Grundsätzlich sei gesagt, dass wir als Ausgangsdatei unsere frisch generierte Probe my_filter.c als Baugrundlage nehmen wollen und damit ein vollwertiges OCI-konformes Image bauen wollen, welches wir ähnlich wie bei Docker mit den gleichen Annahmen ausführen können.
Somit geben wir bee build zunächst die Datei my_filter.c als ersten Parameter mit. Zweiter Parameter ist der Image-Name, einfach my_filter:v1. Wir können zusätzliche Flags mitgeben. Ich möchte noch den --build-image-Flag definieren, da ich sichergehen möchte, dass wir das gleiche Builder-Image verwenden und somit garantieren, dass wir den gleichen Output als Bumblebee-Image haben werden. Dessen Wert ist einfach ein Builder-Image, welches auf einer OCI-Registry unter dem /solo-io/bumblebee-Account liegt.
|
|
Genau wie bei Docker (oder Podman) können wir die gebauten Images wie folgt mit bee list anzeigen lassen.
|
|
Sehr gut, das Image ist gebaut und ist unter dem Befehl list ersichtlich. Ich weiss schon was die meisten denken, bee run wird das Image ausführen…
Bee Run
Wie korrekterweise angenommen kann man das myfilter:v1-Image mit bee run anstossen, aber wir müssen noch eine OS-seitige Erlaubnis einholen:
|
|
Das bewirkt, dass wir den eBPF-Filter überhaubt als normaler nicht-Superuser-Nutzer in den Kernel-Space hineinbekommen. Klar könnte man den Befehl einfach mit sudo prefixen sofern der Nutzer diese Rechte hat, aber da wir das Image im User-Kontext gebaut haben, müsste der Superuser dieses Image nochmals komplett nachbauen. Dieser Fix oben ist somit einfacher.
Jetzt können wir den run wie folgt anstossen.
|
|
Gratulation!
Wir halten fest
Bumblebee ist ein Tool, mit dem sich eBPF-Probes generieren, schreiben, bauen und verpacken lassen. Dabei beruft sich Bumblebee auf den OCI-Standard, mit dem man eBPF-Logik genau so verpackt, wie das Container-basierten Technologien wie Docker beispielsweise auch machen. Der ganze Prozess mit Bumblebee ist sehr nahe an der Docker-Experience und man kann sich somit mit relativ mit wenig Einarbeitung um die eigentliche eBPF-Logik kümmern. Es werden auch genug Primitive durch die Entwicklungsumgebung geliefert, sodass man sich nicht mehr um den User-Space kümmern muss und eigentlich nur noch die Logik im Vordergrund steht. Somit ist Bumblebee eine eher geglückte vereinfachung des gesamten Entwickleraufwands, welcher bei konventionelleren Methoden rund um eBPF komplexer und aufwendiger ausfallen würde.
Mir ist klar, dass der eBPF-Space noch in den Kinderschuhen steckt, ich bin aber überzeugt, dass Bumblebee einen Schritt in die richtige Richtung macht, um eBPF dem Normalverbraucher, sprich dem Durchschnittsentwickler nahezubringen. Die Frage ist eher, ob die Entwicklung von eBPF-Logik überhaupt von diesem Schlag von Entwicklern übernommen wird, oder ob es nicht geschickter, sprich effizienter ist, dass eBPF-Logik dann doch weiter abstrahiert wird, um die Entwicklung zu vereinfachen. Wie so oft mit Neuankömmligen lässt sich diese Frage mit der Zeit beantworten.
Sicher ist, dass eBPF eine interessante Technologie ist, welche man im Jahr 2022 definitiv auf dem Schirm haben und sich die einzelen Entwicklungen wie jetzt hier mit Bumblebee zu Gemüte ziehen sollte. Es bleibt somit spannend.
Referenzen und weiterführende Quellen
https://github.com/solo-io/bumblebee
https://github.com/solo-io/bumblebee/blob/main/docs/concepts.md
https://github.com/solo-io/bumblebee/blob/main/docs/getting_started.md