
Figure: PyTorch, the PyTorch logo and any related marks are trademarks of The Linux Foundation.
Mit Hilfe von Machine Learning Algorithmen können aus großen Datensätzen viele interessante und wertvolle Informationen gewonnen werden. Je nach Anwendungsfall eignen sich verschiedene Algorithmen für unterschiedliche Szenarien. In vorherigen TechUps hat Stefan bereits die Grundlagen von neuronalen Netzen erläutert und wir haben gesehen, wie man mit dem Random Forest Algorithmus die Überlebenswahrscheinlichkeit von Passagieren auf dem Titanic-Schiff vorhersagen kann. In diesem TechUp wollen wir uns mit einem weiteren Verfahren beschäftigen, das uns dabei hilft, Muster in Daten zu erkennen: der Anomaly Detection, zu Deutsch Anomalieerkennung.
Was ist Anomaly Detection?
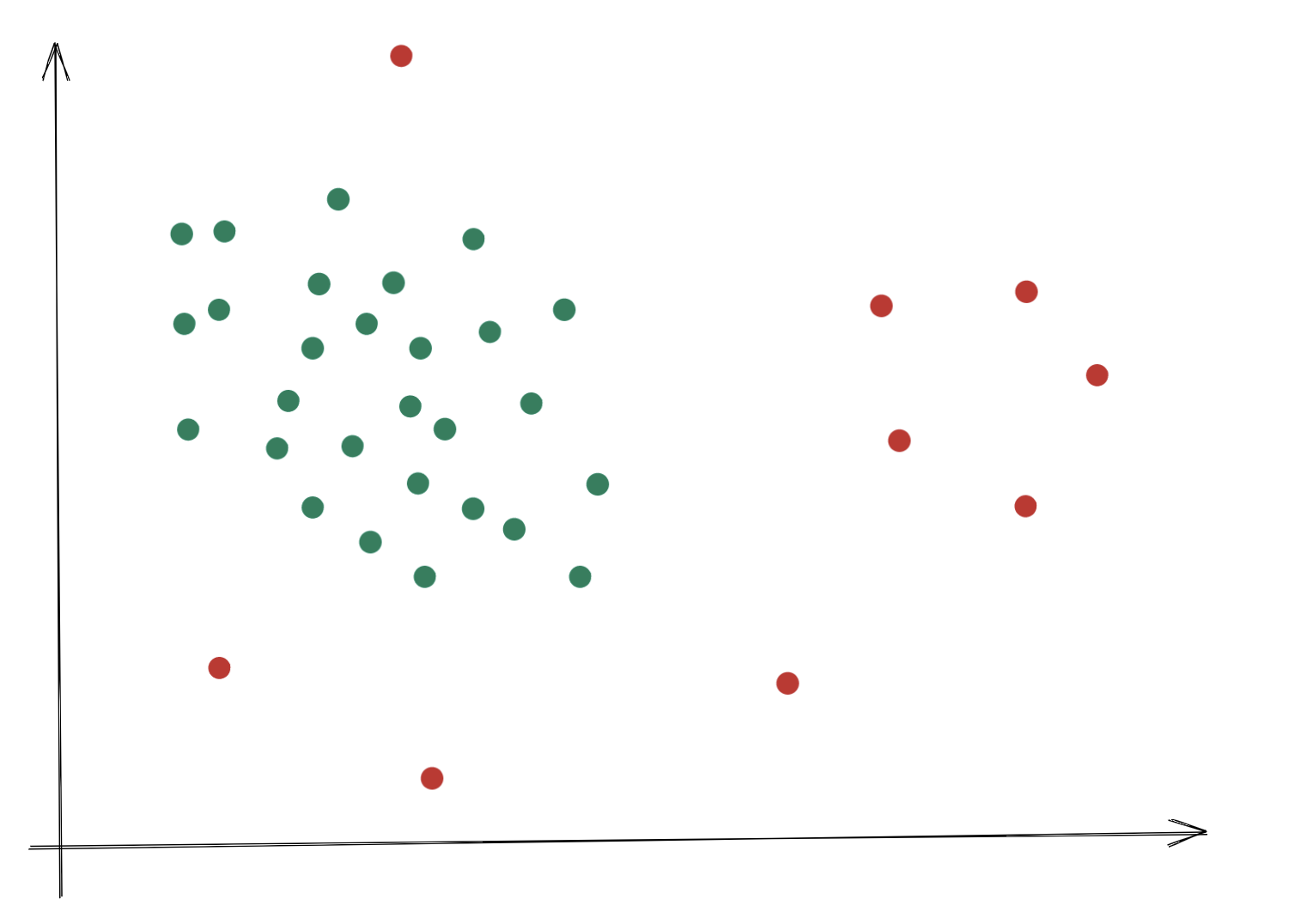
Anomaly Detection ist ein Verfahren, mit dem wir herausfinden möchten, ob ein bestimmtes Ereignis bezogen auf einen Datensatz der Norm entspricht oder nicht. Es gibt viele Anwendungsfälle, die dies verdeutlichen können.
Nehmen wir zum Beispiel die Sensorik einer Maschine, die Datenpunkte über Vibrationen an verschiedenen Messpunkten liefert. Wenn wir diese Daten über einen längeren Zeitraum aufzeichnen, können wir Muster erkennen, die zeigen, welche Art von Vibrationen die Maschine normalerweise aufweist. Sobald Datenpunkte gemessen werden, die von diesen Mustern abweichen, können wir davon ausgehen, dass die Maschine nicht mehr im Normalzustand ist. Dies kann ein Hinweis darauf sein, dass die Maschine defekt ist und repariert werden muss.
Weitere Anwendungsfälle gibt es in vielen Bereichen:
- Cybersecurity (z.B. Erkennung von Anomalien im Netzwerkverkehr)
- Betrugserkennung (z.B. Kreditkartenbetrug oder Versicherungsbetrug)
- Gesundheitswesen (z.B. Erkennung seltener Krankheiten)
- Straßenverkehr (z.B. Erkennung von Unfällen)
Wie funktioniert Anomaly Detection?
Wie wir gesehen haben, gibt es viele Anwendungsfälle, in denen Anomaly Detection eingesetzt werden kann. Wenn wir Machine Learning Algorithmen verwenden möchten, um Anomalien zu erkennen, gibt es zwei verschiedene Ansätze, die wir uns im Folgenden anschauen werden.
Bevor wir uns jedoch Gedanken über das Training von Modellen machen, sollten wir uns zunächst Gedanken über die Datengrundlage machen. Um Anomalien erkennen zu können, werden zunächst Daten benötigt, die den Normalzustand darstellen. Je nach Algorithmus werden möglicherweise auch klassifizierte Daten benötigt, die ausreichend von der Norm abweichen, um überhaupt als Anomalie klassifiziert werden zu können. Vor allem bei der Anomaly Detection ist die Qualität der Datengrundlage entscheidend. Betrachten wir zum Beispiel die Betrugserkennung: Wir können davon ausgehen, dass die Mehrheit der Datenpunkte nicht betrügerisch ist. Wenn die wenigen betrügerischen Datenpunkte nicht ausreichend repräsentativ sind oder falsch klassifiziert wurden, kann unser Algorithmus falsche Vorhersagen treffen. Dies kann in diesem Fall zu einer Über- oder Unterklassifizierung führen, die je nach Einsatzgebiet schwere Folgen haben kann.
Nun, sobald die Qualität der Datengrundlage gesichert ist, können wir uns Gedanken über die Algorithmen machen. Hier unterscheidet man zwischen zwei verschiedenen Ansätzen: Supervised Learning und Unsupervised Learning. Wenn wir einen Supervised Learning Algorithmus verwenden möchten, muss unser Datensatz klassifiziert sein, das heißt jeder Datenpunkt muss entweder als Normalzustand oder Anomalie klassifiziert sein. Je nach Anwendungsfall kann es schwierig sein, solche Daten zu generieren.
Betrachten wir das Beispiel der Sensorik einer Maschine, würden wir erwarten, dass im Normalfall wenige bis keine Anomalien auftreten. Wenn wir jedoch einen Supervised-Ansatz wählen möchten, müssten wir entweder Daten über relativ lange Zeiträume sammeln oder die Maschine gezielt beschädigen oder stören, um Anomalidatenpunkte zu erzeugen. Die Sensordaten korrekt zu klassifizieren, ist auch nicht unbedingt einfach. In solchen Fällen eignet sich ein Unsupervised Learning Algorithmus besser, der keine vorher klassifizierten Daten benötigt, sondern Anhand von Mustererkennung die Anomalien selbst erkennt.
Beispiel: Anomaly Detection anhand von Kreditkartenbetrug
Um die beiden Ansätze zu veranschaulichen, betrachten wir als Beispiel einen Datensatz über Kreditkartenbetrug. Die Daten umfassen insgesamt knapp 284.000 Kreditkartentransaktionen an zwei Tagen im September 2013, von denen 492 als betrügerisch klassifiziert wurden. Das Datenset kann von Kaggle heruntergeladen werden.
Insgesamt stehen uns 30 numerische Merkmale zur Verfügung, von denen 28 das Ergebnis einer Principal Component Analysis (PCA) Transformation der Originaldaten sind. Die anderen beiden Merkmale sind der Zeitpunkt und der Betrag der Transaktion. Aufgrund von Anonymisierungsmaßnahmen sind keine weiteren Informationen zu den einzelnen Features bekannt.
Da wir klassifizierte Daten vorliegen haben, können wir einen Supervised-Learning-Ansatz verwenden. Hier werden wir den Random Forest Algorithmus einsetzen, den wir bereits in meinem TechUp zu Decision Trees kennengelernt haben.
Als weiteren Ansatz werden wir nach diesem Beispiel auch Autoencoder zur Veranschaulichung eines Unsupervised-Learning-Algorithmus vorstellen.
Anomaly Detection mit Random Forest
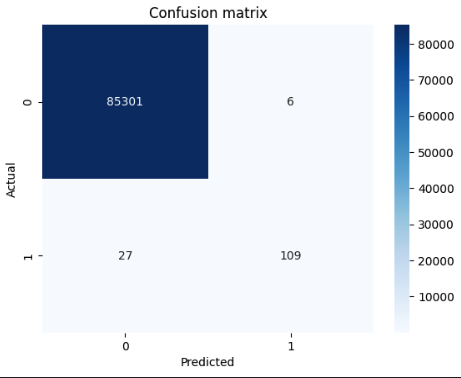
Mit dem Random Forest Algorithmus lässt sich ein Modell trainieren, welches einzelne Datenpunkte anhand der Features klassifizieren kann. Um das Modell zu trainieren, benötigen wir klassifizierte Daten, die wir in unserem Datensatz vorfinden. Wir werden nun das Modell trainieren und anschließend die Vorhersagen des Modells mit den tatsächlichen Klassifikationen vergleichen. 🤓
|
|
Die Resultate sind trotz des geringen Aufwands ziemlich sehenswert:
Anomaly Detection mit Autoencodern
Bei Autoencodern handelt es sich um eine spezielle Art bzw. Architektur von neuronalen Netzen, die darauf ausgelegt sind, Daten zu komprimieren. Die Idee hinter Autoencodern lässt sich am besten mithilfe einer Abbildung erklären:
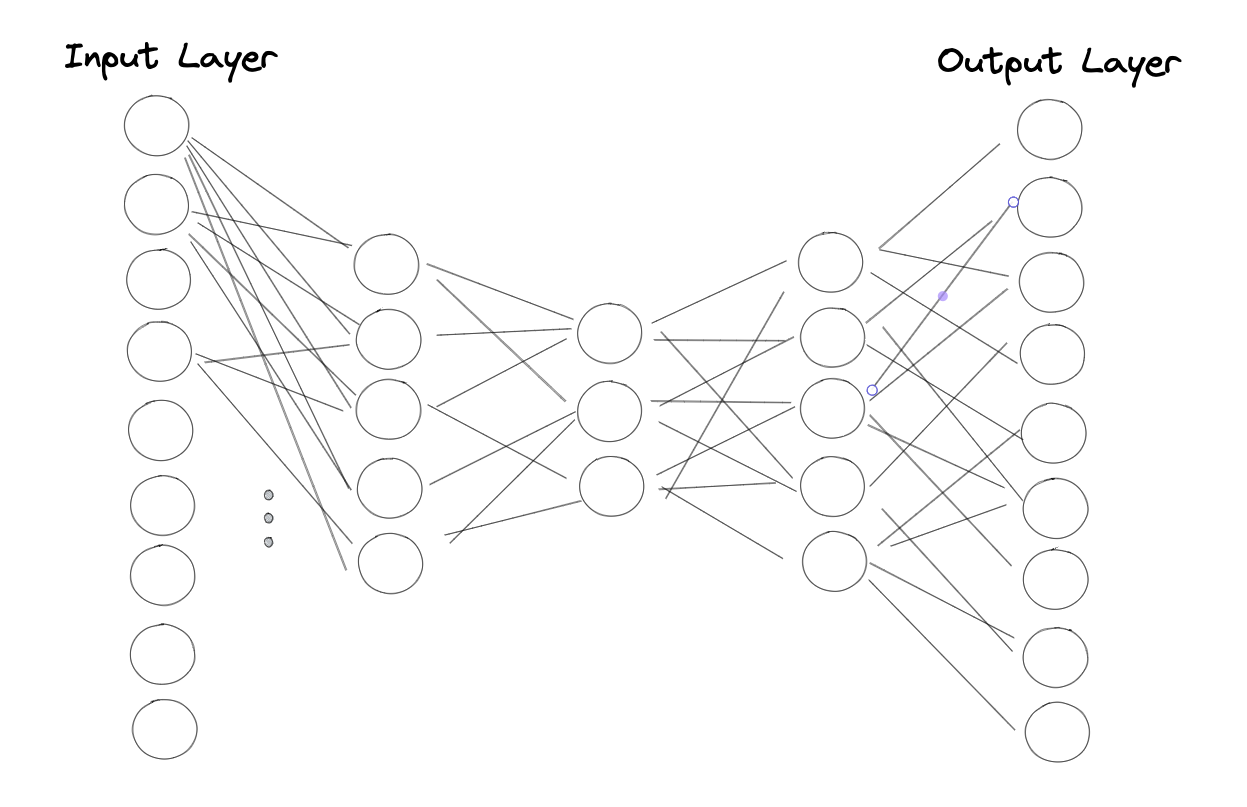
Wir sehen ein neuronales Netz mit einem Input, einem Output und drei Hidden-Layers. Alle Layer sind vollständig vernetzt, das heißt, alle Neuronen sind mit allen Neuronen der vorherigen und nachfolgenden Layers verbunden. Wie man sieht, verringert sich die Anzahl der Neuronen von Layer zu Layer und das Netz ist in der Mitte gespiegelt.
Das Besondere an Autoencodern ist die Art und Weise, wie sie trainiert werden. Das Netz wird darauf trainiert, denselben Output wie Input zu liefern. Nehmen wir als Beispiel unseren Datensatz, würden wir für jedes Merkmal in jedem Datenpunkt die gleichen Werte im Output erwarten. Die Verjüngung der Layers führt dazu, dass das Netz die Input-Daten auf die wichtigsten Eigenschaften bzw. Informationen komprimieren muss, um diese im Output wieder zu reproduzieren.
Das trainierte Modell hat nun die Struktur der Trainingsdaten gelernt und kann neue Datenpunkte anhand dieser Struktur klassifizieren. Möchte man jetzt einen neuen Datenpunkt klassifizieren, so wird dieser durch das Netz gepushed und die Ausgabe des Netzwerks wird mit dem Input verglichen. Je größer der Unterschied zwischen Input und Output ist, desto stärker weicht der Datenpunkt von der Struktur der Trainingsdaten ab und desto wahrscheinlicher ist es, dass es sich um eine Anomalie handelt. Cool, oder? 😎
Im Folgenden trainieren wir einen Autoencoder mit PyTorch und verwenden diesen, um neue Datenpunkte zu klassifizieren.
|
|
Das trainierte Modell können wir jetzt mit den vorklassifizierten Datenpunkten evaluieren. Hierfür vergleichen wir die Differenzen zwischen dem Input und Output des Autoencoders (Loss) von einem Subset der Nicht-Fraud-Datenpunkte mit denen der Fraud-Datenpunkte. Je grösser der Unterschied zwischen den beiden Datensätzen ist, desto besser ist das Modell darin, Anomalien zu erkennen.
|
|
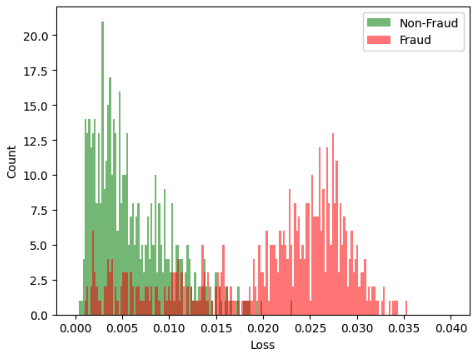
Wie man in der Abbildung schön sehen kann, unterscheiden sich die Loss-Werte der Fraud-Datenpunkte zu einem grossen Teil deutlich von denen der Nicht-Fraud-Datenpunkte. Wir können nun einen Schwellenwert definieren, ab welchem ein Datenpunkt als Anomalie klassifiziert wird.
Natürlich ist unsere Klassifikation nicht optimal, was anhand der Überlappung der beiden Histogramme zu sehen ist. Ob Autoencoder bei der Erkennnung von Anomalien das richtige Werkzeug sind, hängt stark von den Daten ab und muss immer individuell evaluiert werden.
Fazit
Ich hoffe ich konnte euch mit diesem TechUp einen interessanten Einblick in den Bereich Anomaly Detection geben. Es gibt viele Bereiche in welchen man durch das Erkennen von Datenpunkten, welche von der (vermeintlichen) Norm abweichen, wertvolle Informationen gewinnen kann. Bleib dran! 🙌
Lies doch gleich noch Stefans TechUp zu den Grundlagen neuronaler Netze! 🚀