Eines der wichtigsten Tech-Entwicklungen der letzten zehn Jahre war die Containerisierung. Damit wurde es möglich ganze Applikationsumgebungen in einem Container laufen zu lassen.
Kubernetes ist die weit verbreiteste und mit Abstand bekannteste Lösung für die Orchestrierung von Containern. Gibt es denn überhaupt eine Alternative zu Kubernetes? Ja, HashiCorps Nomad ist vielleicht die einzige Alternative zu Kubernetes. Was zeichnet Nomad aus, oder besser gesagt, was macht Nomad anders? Genau zwei Dinge:
-
Ganz nach der Art der UNIX-Philosophie: Do one thing and do it well.
-
Flexibilität bezüglich containerisierten und nicht-containerisierten Applikationen
Steigen Sie mit uns ein und lassen Sie uns zusammen schauen was Nomad kann und warum vielleicht genau Sie Nomad Kubernetes bevorzugen könnten!
Mit einem Hammer sieht alles wie ein Nagel aus

Figure: Quelle: https://atodorov.me/2021/02/27/why-you-should-take-a-look-at-nomad-before-jumping-on-kubernetes/ (aufgerufen am 03.11.2021)
Kubernetes als die gängigste Lösung für Container-Orchestrierung hat auch weniger bekannte Limitierungen. Kubernetes 5’000 Nodes mit 300’000 Containern vs. Nomad mit erfolgreichen Realversuchen von 10’000 Nodes und bis zu 2 Millionen Containern. Siehe hierfür die ‘The Two Million Container Challenge’ (https://www.hashicorp.com/c2m ). Dabei wurden 2’000’000 Docker-Container auf 6’100 Hosts in 10 unterschiedlichen AWS-Regions in einem Zeitrahmen von 22 Minuten erfolgreich ausgerollt.
Es gibt bereits zahlreiche Nomad-Nutzer wovon bekannte Unternehmen wie Cloudflare, CircleCI, SAP, eBay oder die altbekannte Internet Archive zählen.
Workload-Orchestrierung mit Nomad
Nomad punktet mit ganz eigenen Vorteilen, die Kubernetes nicht zwingend in dieser Form zusichert. Darunter kann man folgende Punkte festhalten:
-
Deployment von Containern, Legacy-Applikationen und weiteren Workload-Typen
-
Einfach und zuverlässig
-
Geräte-Plugin und GPU-Unterstützung
-
Federation von Multi-Regions und Multi-Cloud
-
Bewährte Skalierbarkeit
-
HashiCorp-Ökosystem
Die Nomad-Architektur
Genau wie bei Kubernetes oder ähnlichen weitreichenden Software-Lösungen, kommt mit Nomad ein eigenes Verständnis der Orchestrierungsarchitektur, sowie mit dem damit verbundenen Glossar mit.
Vielleicht allen anderen Erläuterungen vorausgeschickt, Nomad ist eine einzelne Binary. Diese Binary kann wahlweise auf einem Host als Prozess, jeweils als Client oder Server (die Unterscheidung wird gleich erläutert) oder als Command-Line Interface durch den Endnutzer ausgeführt werden.
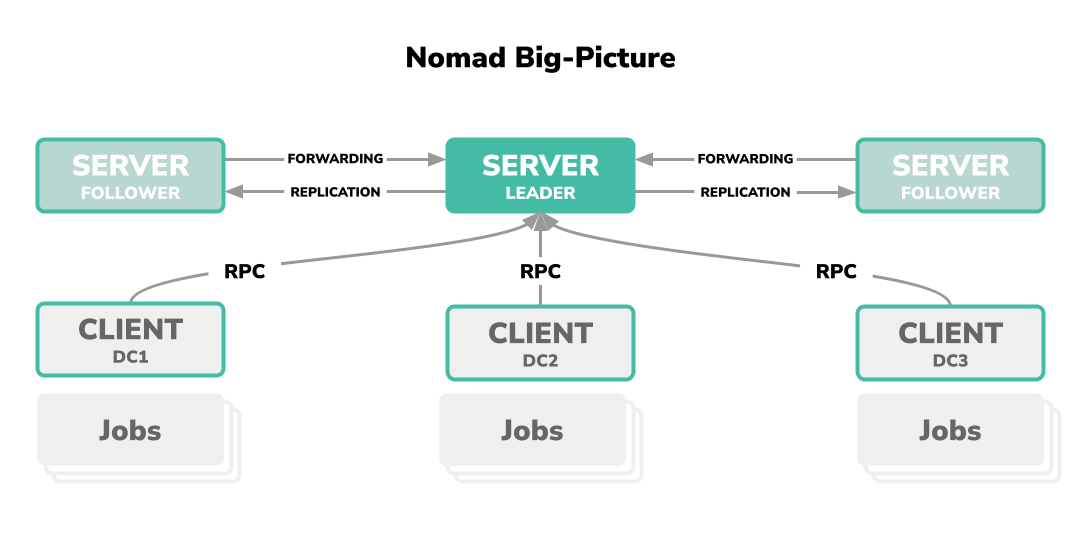
-
Server(s): Nomad-Server ist ein Verbund von mindestens 3 Server-Einheiten worauf ein Nomad-Agent im Server-Modus als Prozess läuft. Dabei ist dieser immer im Verbund der Leader und hat die Deutungshoheit über den Cluster. Diese Ordnung entspricht dem Consesus Protocol und basiert auf dem Raft-Konsensusalgorithmus.
-
Client(s): Nomad-Clients ist ein Verbund von einer Vielzahl von einzelnen Client-Einheiten worauf ein Nomad-Agent im Client-Modus als Prozess läuft. Der Client dient als Zielsystem, wenn Workload durch den Server-Verbund orchestriert werden muss. Auf einem Client wird die Workload, im Nomad-Glossar Job genannt.
-
Job: Ein Job ist eine Spezifikation, welche durch den Endnutzer deklariert wurde und als Workload auf eine Client-Einheit orchestriert und ausgerollt wird.
Job-Spezifikation
Der Job ist in erster Linie eine Spezifikation, die durch den Nutzer einmalig deklariert wird. Innerhalb eines Jobs gibt es eine Group, welche wiederum eine oder mehrere Tasks beinhalten kann. Die Hierarchie kann wie folgt zusammengefasst werden:
|
|
Job, Group und Task werden im Nomad-Jargon wie folgt definiert:
-
Job: Die Workload als deklarative Spezifikation.
-
Group: Auch Task Group genannt, ist eine Ansammlung von Tasks, welche zusammen ausgeführt werden müssen und Teil eines Jobs sind.
-
Task: Ist die kleinste Arbeitseinheit in Nomad. Tasks werden durch Driver ausgeführt und kann unterschiedliche Typen von ausführbaren Operationen beinhalten.
-
Driver: Auch Task Driver genannt, definiert was genau bei der Ausführung vorausgesetzt wird. Ein bekannter Task Driver wäre die Containerlösung Docker.
Task Driver
Somit unterstützt Nomad offiziell folgende Task Drivers:
- Docker
- Isolierte Execution (exec)
- Raw Execution (raw exec)
- JVM
- Podman
- QEMU-Virtualisierung
Dazu kommen von der Community betreute Task Drivers, welche unter anderem folgende Laufzeiten anbieten:
- containerd
- Firecracker
- LXC
- WebAssembly
- FreeBSD Jail
- Rooktout
- Singularity (Container Platform)
- systemd-nspawn
- Windows IIS
- AWS ECS als Remote-Target
Eine vollständige Auflistung kann in der offiziellen Dokumentation unter https://www.nomadproject.io/docs/drivers gefunden werden.
Beispielsdeklaration eines Nomad-Jobs
Hier sehen wir eine exemplarische Spezifikation eines Jobs mit dem Namen docs womit ein Webfrontend mithilfe eines
Docker-Image hashicorp/web-frontend als Task ausgeführt wird und zur Verfügung gestellt werden kann.
|
|
Noch ein Wort zu HCL
Die Manifeste, die wir vorhin gesehen haben sind, alle in einem relativ unbekannten Format verfasst: nämlich HCL. HCL steht als Akronym für HashiCorp Configuration Language und ist ein hauseigener Standard, welcher gerne für Konfigurationsbedürfnisse HashiCorps Produktpalette Verwendung findet.
HCL ist ein mit JSON-verwandtes Format und wird von HashiCorp als Fortführung von JSON verstanden. Als nativer Syntax, soll HCL maschinen-, wie auch menschenfreundlich sein und effizient von beiden gelesen werden können. Weitere Informationen und Spezifikationen können in der offiziellen Github-Repo von hashicorp/hcl gefunden werden.
HashiCorp Stack
HashiCorp ist eine aus San Francisco stammende Firma, die im Jahre 2012 von namensgebenden Mitchell Hashimoto und Armon Dadgar gegründet worden ist. Diese Silicon-Valley-Firma bietet Software-Lösungen im Bereich Cloud-Computing an und haben sich einen Namen mit ihrem relativ bekannten Infrastructure-as-Code-Produkt Terraform gemacht.
Hashicorp hat neben Terraform aber noch weitere Lösungen am Start und bietet eigentlich gesonderte Teillösungen, die jeweils einen Teilbereich der Cloud-Infrastruktur abdecken, die sich aber in der Kombination eine Gesamtlösung für eine vollwertige Cloud-Umgebung eignen. Genau dies ist mit dem HashiCorp-Stack gemeint: Das Ausrollen und Betreiben einer kompletten Cloud-Infrastruktur. Eine Gesamtauflistung dieser Teilkomponenten und Produkten von HashiCorp können wie folgt zusammengefasst werden:
- Terraform: Automatisierung der Provisionierung einer Infrastruktur auf einem Cloud- und/oder Service-Provider basierend auf dem Prinzip von Infrastructure-as-Code.
- Packer: Bauen von Machine-Images als Container mit einer einzigen Source-Konfigurationsdatei.
- Vagrant: Bereitstellung von reproduzierbaren Entwicklungsumgebungen mithilfe von Virtualisierung.
- Consul: Implementierung eines klassischen Service-Mesh und DNS-basierte Service Discovery.
- Vault: Bereitstellung von Secrets Management, Encryption von Applikationsdaten und weiteren Security-Mechanismen.
- Boundary: Bereitstellung einer Plattform für Identity-based Access.
- Waypoint: Abstraktionslayer für das eine komplette Pipeline (Build&Deploy) auf unterschiedlichen Plattformen wie Kubernetes oder AWS ECS.
- Nomad: Das hier thematisierte Orchestrierungstool für Workloads aller Art.
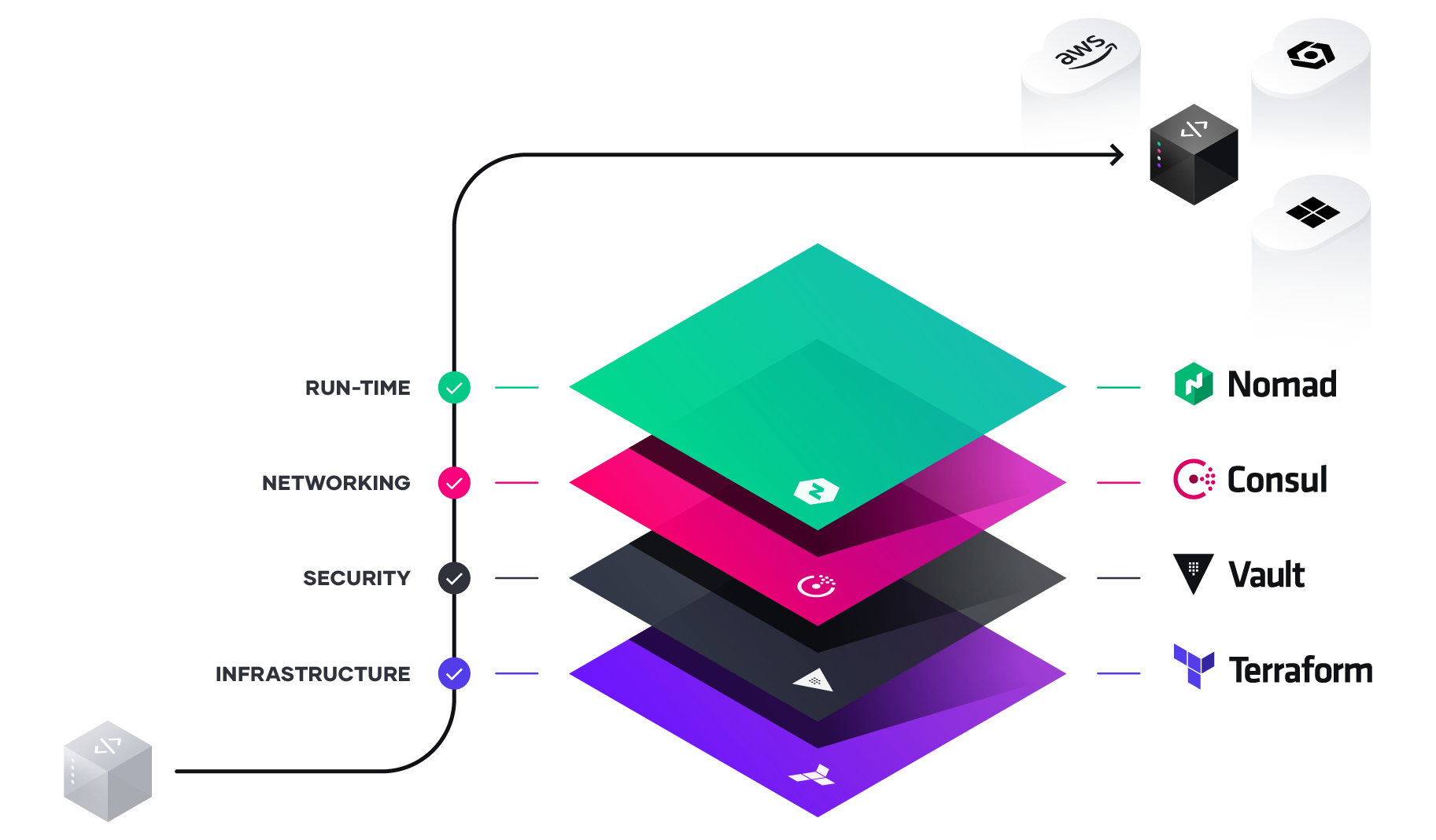
Figure: Quelle: https://www.hashicorp.com/resources/unlocking-the-cloud-operating-model-with-microsoft-azure (aufgerufen 03.11.2021)
HashiCorp Cloud Platform
Es gibt auch eine hauseigene Cloud-Platform womit man die Teillösung gleich bei HashiCorp selber hosten lassen kann: Das ist die HashiCorp Cloud Platform, oder kurz HCP.
In der jetzigen Fassung werden (noch) nicht alle Produkte als Service angeboten, aber man kann davon ausgehen, dass langfristig alle eigenen Produkte angeboten werden. Zurzeit steht noch kein Angebot zu HashiCorps Nomad zur Verfügung. Somit muss Nomad weiterhin auf einer Cloud-basierten Umgebung wie AWS ECS oder gleich auf Bare-Metals gehosted werden.
Praktischer Grundkurs mit Nomad
Installation auf macOS:
|
|
Um eine lokale Instanz von Nomad zu starten, einfach den folgenden Befehl ausführen:
|
|
Prüfe den Status von der Nomad-Instanz wie folgt:
|
|
Mit einem Abruf der Members des Servers sehen wir, dass der Agent tatsächlich im Server-Modus läuft und als Leader Teil des Gossip-Protocols ist:
|
|
Nun können wir unseren ersten Job für den Nomad-Cluster definieren. Dazu bietet die Nomad-CLI einen nützlichen Befehl.
Switchen wir dazu schnell ins /tmp-Verzeichnis und führen nomad job init aus.
|
|
Das generiert uns ein Beispiels-Job ins lokale Verzeichnis mit dem Dateinamen example.nomad. Wenn wir die Datei
mit less oder cat inspecten bekommen wir Folgendes zu sehen:
|
|
Falls Sie den job init-Befehl genau gleich ausgeführt haben wie dieser oben steht, werden Sie viel mehr
Kommentarzeilen in ihrem Beispiel vorfinden. Ich habe die Ausgabe für die Ansicht hier im Artikel mit dem -short
-Flag abkürzen lassen, sodass nur für Nomad signifikante Teil generiert werden.
Der Job ist recht übersichtlich und deklariert einen Job mit dem Namen example, darin eine Group mit dem Namen cache
, sowie –als kleinste Einheit einer Nomad-Job-Definition– einen Task mit dem Namen redis, welcher das
Docker-Image redis:3.2 ausrollen soll. Ein Port, wird auch definiert, sowie eine Ressourcen-Angabe für CPU und Memory.
Wichtig hierbei anzumerken, ist die explizite Deklaration eines docker-Drivers. Wie eingangs bereits erwähnt, kann
Nomad nicht nur Docker-Images, sondern eine ganze Bandbreite von Workloads orchestrieren. Hier bleiben wir aber bei
einem klassischen Docker-Image. So weit, so gut.
Jetzt rollen wir den Job aus. Das geht ganz einfach wie folgt:
|
|
Nachdem das Image gezogen und ausgerollt wurde, prüfen wir den Status von allen vorhandenen Jobs:
|
|
Sowie spezifisch des Jobs mit der ID example:
|
|
In meinem Fall hat der Job eine Allokation mit der ID 0c88d2ef. Damit kann ich weitere Zustände prüfen.
|
|
Oder auch die Logs des Jobs mit der gleichen Allokations-ID:
|
|
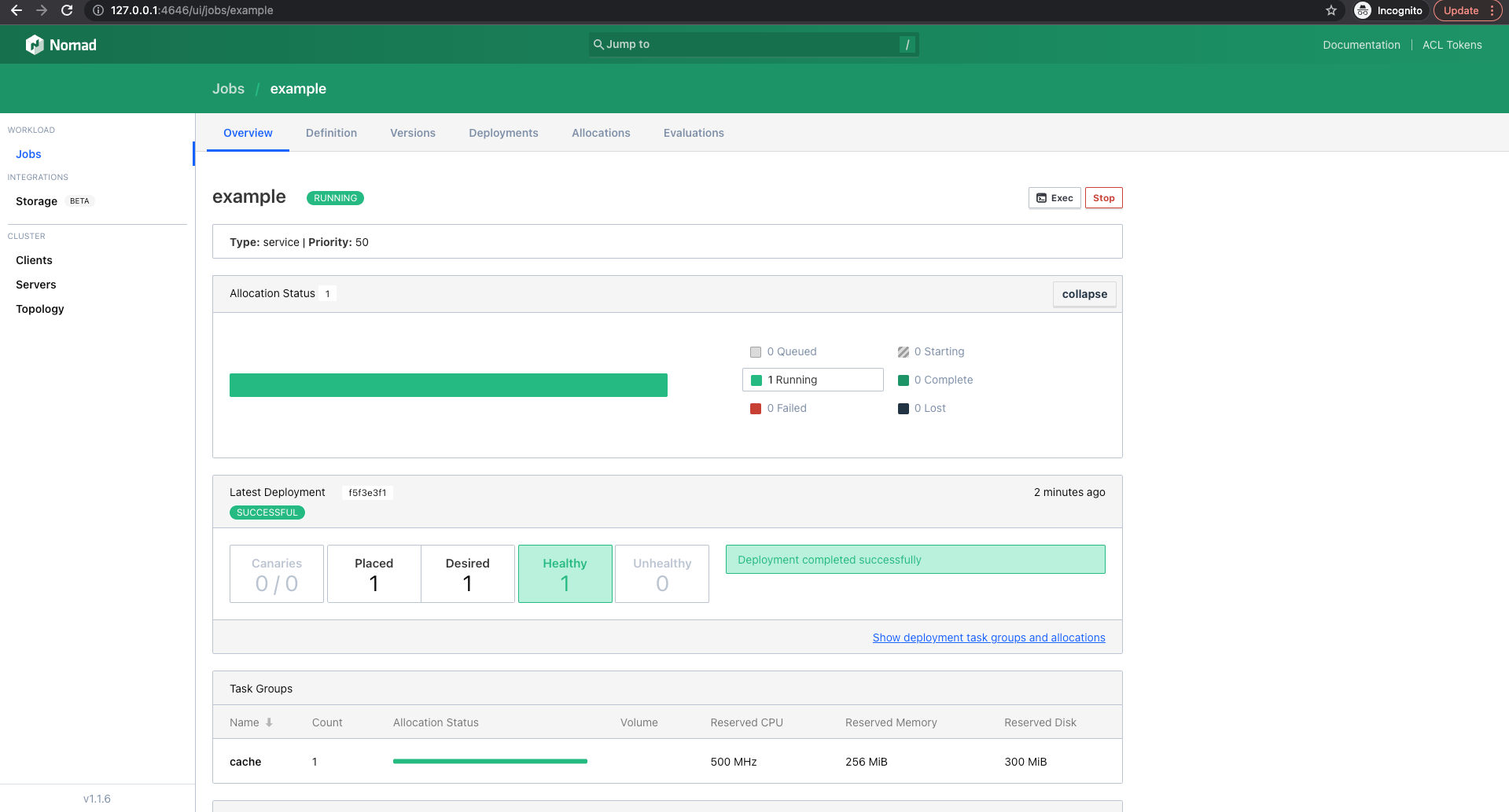
Genau wie bei Kubernetes, gibt es bei Nomad auch eine graphische Oberfläche. Diese läuft unter dem Port und kann mit folgendem Link aufgerufen werden.

Unter Jobs können wir unseren example-Workload genauer anschauen.
Fazit
Nomad hat bei uns einen guten Eindruck hinterlassen. Es hat weder die Grösse, noch die Masse eines Kubernetes, aber glänzt durch seinen Minimalismus mit Flexibilität und Effizienz. Nomad kann nicht alles, aber was es kann, macht es gut. In unserer Einschätzung eignet sich Nomad in spezifischen Use-Cases wo Kubernetes etwa zu gross und zu träge wäre. Das beinhaltet kleine Entwickler-Teams oder die Notwendigkeit eine gewisse Flexibilität bei der Verwendung von Applikationsumgebungen –wo ein Container vielleicht nicht zwingend der kürzeste Weg zum Ziel ist– haben zu wollen.
Ein weiterer Use-Case ist sicherlich der Umstand, dass Nomad direkt auf GPU-Leistung zugreifen kann und somit Workloads interessant werden, welche auf dessen Leistung angewiesen sind . Darunter fallen zum Beispiel Applikationen wie Machine Learning, Cryptocurrency-Mining oder allgemein Ressourcen-intensives Scientific Computing.
Wir bei b-nova haben Nomad zwar nicht im Einsatz, denken aber, dass sich Nomad am besten für kleine Startup-Teams, KMU im Allgemeinen oder in ganz spezifischen Nischenbereichen einsetzen lässt. In den meisten anderen Fällen ist Kubernetes sicherlich die bessere Lösung. Falls Sie Beratung und Unterstützung bei Nomad, Kubernetes oder allgemein im Container- und Cloud-Umfeld brauchen, so stehen wir Ihnen jederzeit zur Verfügung. Stay tuned!
Weiterführende Links und Ressourcen
https://learn.hashicorp.com/nomad
https://learn.hashicorp.com/collections/nomad/get-started
https://www.hashicorp.com/blog/a-kubernetes-user-s-guide-to-hashicorp-nomad
https://atodorov.me/2021/02/27/why-you-should-take-a-look-at-nomad-before-jumping-on-kubernetes/
https://endler.dev/2019/maybe-you-dont-need-kubernetes/
https://medium.com/hashicorp-engineering/hashicorp-nomad-from-zero-to-wow-1615345aa539
https://aws.amazon.com/quickstart/architecture/nomad/
https://manicminer.io/posts/getting-started-with-hashicorp-nomad/