Diese Woche möchten wir uns mit dem Thema Künstliche Intelligenz, Machine Learning & Deep Learning auseinandersetzen. Dabei werde ich dir die Grundlagen dieser wichtigen Technologien, welche heute sehr oft und in den verschiedensten Bereichen Anwendung finden, erläutern. Viel Spass! 😄
Deep Learning
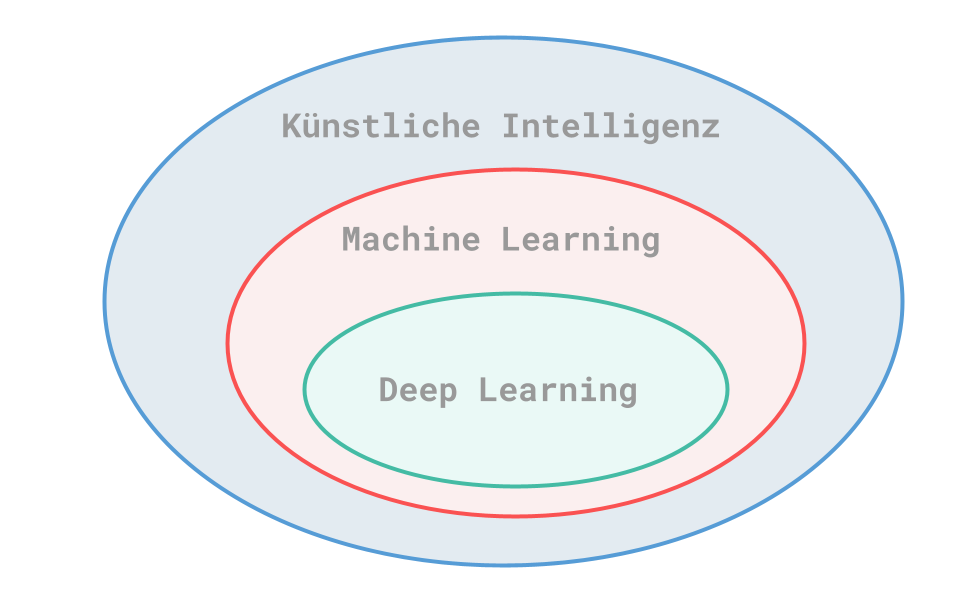
Künstliche Intelligenz
Das Thema KI entstand bereits in den 1950er Jahren, als sich damalige Informatiker fragten, ob es möglich sei, geistige Aufgaben, welche normalerweise von Menschen erledigt werden, zu automatisieren. Künstliche Intelligenz schliesst dabei die nächsten beiden Gebiete Machine Learning und Deep Learning mit ein.
Das erste Einsatzgebiet einer KI war ein Schachspiel. Hierfür gaben Programmierer einen Regelsatz vor, um die «Aufgabe» zu lösen. Daraus folgte die Überlegung, dass man eine KI auf menschliches Niveau bringen kann, indem man einen ausreichend grossen Regelsatz vorgibt. Dieser Ansatz wurde bis etwa Ende der 80er-Jahre verfolgt und ist unter dem Namen symbolische KI bekannt. Man merkte jedoch schnell, dass dies für komplexere Aufgaben nicht ausreichend war. Ein Beispiel hierfür wäre die Bilderkennung oder das Übersetzen von Fremdsprachen. Aus dieser Tatsache entstand das nächste Fachgebiet: Machine Learning.
Machine Learning
Durch die Herausgabe von Alan Turings Arbeit “Computing Machinery and Intelligence” kam es zu einer entscheidenden Wendung der Konzepte rund um das Thema Künstliche Intelligenz. Mit der sogenannten “Lady Lovelace Objection“ kam er zu dem Ergebnis, dass Allzweckcomputer in der Lage seien, selbst zu lernen. Bei der Lady Lovelace Objection geht es um Turings Gegenthese zu einer Aussage von Lady Ada Lovelace aus dem Jahre 1843: Sie sagte damals über die Analytical Engine, welche von Charles Babbage erfunden wurde, dass diese nicht das Ziel hat, neues zu erschaffen.
Dadurch entstand die grundlegende Frage von Machine Learning: Kann ein Computer nicht nur auf Basis von vorgegebenen Regeln entscheidungen treffen, sondern vielleicht auch selbstständig anhand von Daten lernen?
Dabei gibt es unterschiede zwischen dem klassischen Programmierparadigma und dem des Machine Learning: Bei dem klassischen Prinzip werden Daten und Regeln als Input der Applikation vorgegeben. Aus diesen Inputparametern werden dann Antworten erstellt. Beim Prinzip von ML werden stattdessen Daten und dazugehörigen Antworten mitgegeben. Daraus sollen die Regeln erkannt werden, welche zu dem Ergebnis führen. Diese erlernten Regeln lassen sich dann nämlich auf neue Daten weiter anwenden.
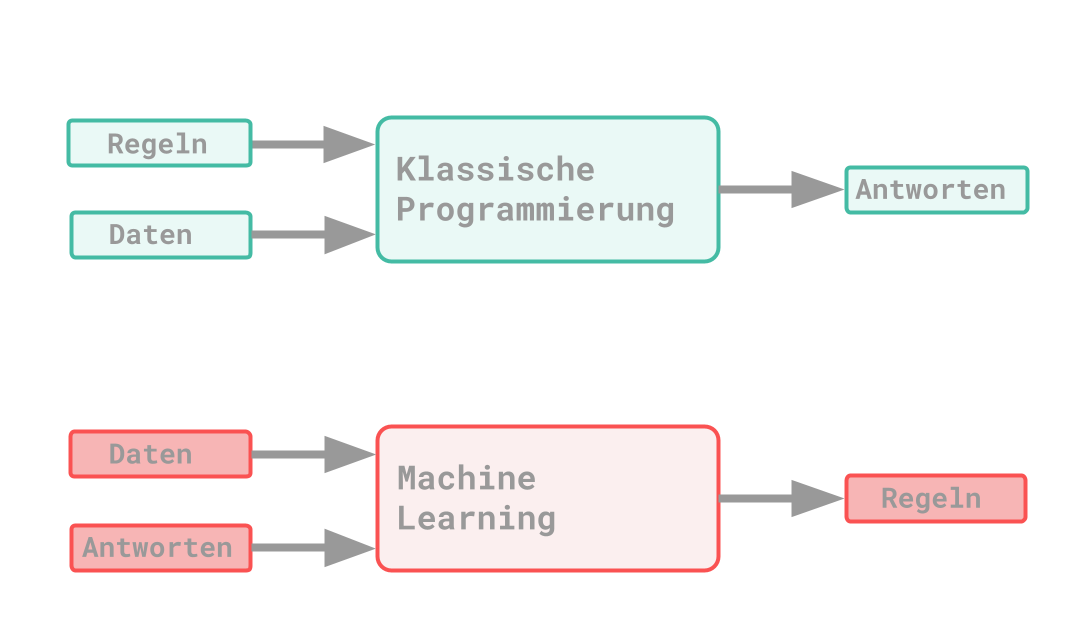
Es handelt sich hier also, im Vergleich zum klassischen Programmieren, mehr um einen Trainingsvorgang. Dabei ist ML auch mit der mathematischen Statistik verwandt. Ein grosser Unterschied ist vor allem, dass bei ML eine sehr grosse Datenmenge verarbeitet werden muss.
Repräsentationen
Während dem Lernvorgang des ML-Algorithmus müssen verschiedene Transformationen gemacht werden. Dabei muss eine Repräsentation gewählt werden, welche die Daten besser darstellt. Anhand dieser Repräsentationen können bessere Regeln gefunden werden. Vereinfacht gesagt ist ML eine Suche nach der besten Repräsentation der eingegebenen Daten.
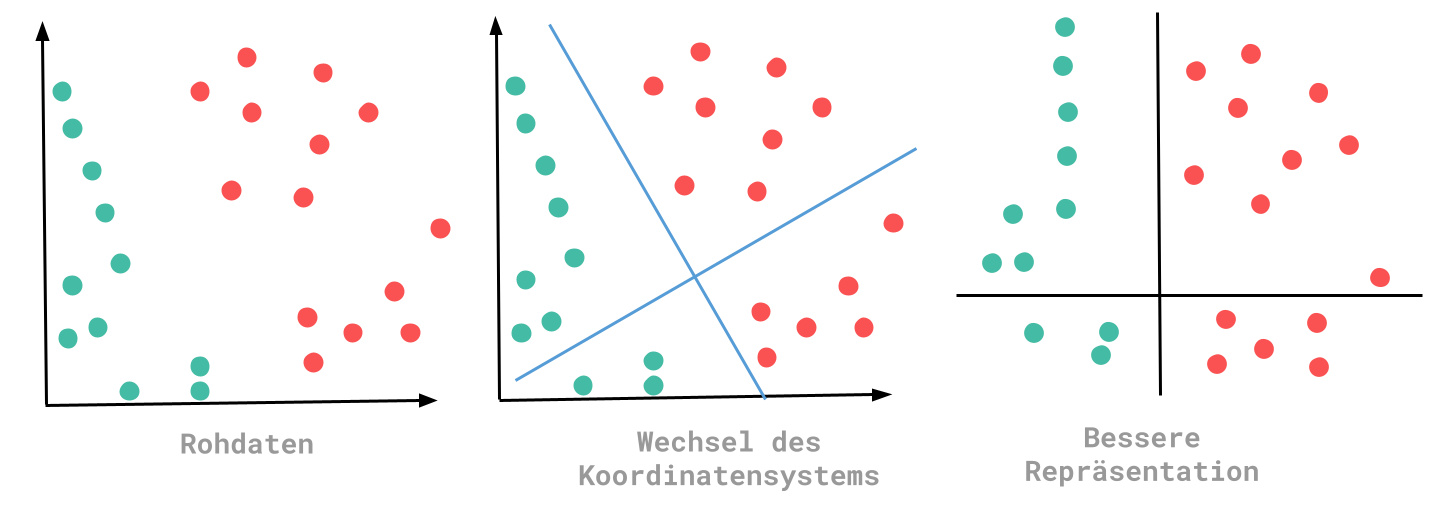
Bei diesem Beispiel kann durch die veränderte Repräsentation der Schluss gezogen werden, dass alle Punkte, die kleiner Null sind, die Farbe Grün haben. Bei den Rohdaten konnte solch eine Aussage nur schwer definiert werden.
Deep Learning
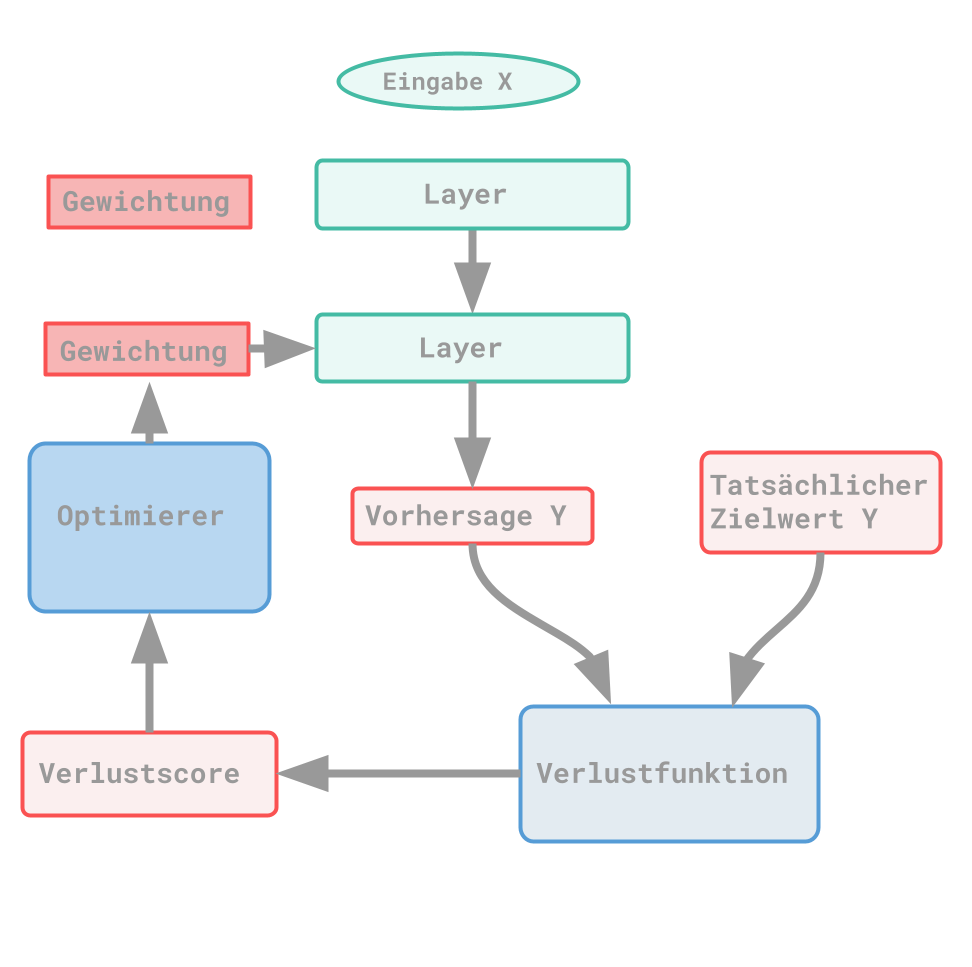
Bei Deep Learning handelt es sich um einen Ansatz von ML. Grundsätzlich sind nach den vorherigen Erkenntnissen immer drei Bestandteile notwendig: Eingabedaten, Ergebnisse und Weg zum Prüfen der Resultate. Dabei sollen mit den Daten und dem ML-Algorithmus über mehrere Layer hinweg immer passendere Repräsentationen gefunden werden. Somit steht das Deep eigentlich nur dafür, dass mehrere Repräsentationsschichten erstellt bzw. durchgearbeitet werden. Dies beschreibt die Tiefe eines Modells. Beim Deep Learning werden die verschiedenen Repräsentationen durch ein neuronales Netz (ein Modell) erlernt. Umso geringer der Wert der Verlustfunktion ist, desto genauer sind die Ergebnisse zu den Zielwerten. Dann spricht man davon, dass ein neuronales Netz trainiert ist. Der Verlustwert beschreibt die Abweichung zwischen Output und dem gewünschten Ergebnis.
Anwendungsbeispiele:
-
Bildekennung
-
Spracherkennung
-
Handschrifterkennung
-
Übersetzung
-
Digitale Assistenten
💡 Deep Learning ist nicht der einzige vorhandene Algorithmus. Weitere Beispiele wäre der naive Bayes-Klassifikator oder Logistische Regression.
Ein grosser Durchbruch wurde in einem Wettbewerb 2012 erreicht; Bei diesem Wettbewerb müssen 1.5 Millionen Bilder automatisiert 1000 verschiedenen Kategorien zugeordnet werden. Damals wurde eine Verbesserung der Korrektklassifizierungsrate von 12% erreicht (86,3%). Für die Erkennung in diesem Wettbewerb wurde auf “Deep Convolutional Neural Networks” gesetzt, welche seither gerne verwendet werden. Seit 2015 zählt der Wettbewerb mit einer Rate von 96.4% als gelöst.
Der grösste Vorteil von Deep Learning ist, dass die Merkmalerstellung, also die erstellung von Layers zur Repräsentation von Daten, automatisiert passiert. Deep Learning ist zudem von der verwendeten Hardware, Datenmengen, Benchmarks und den Algorithmen abhängig.
Neuronale Netzwerke
Wenn du dich mit dem Thema Neuronale Netzwerke befasst, wirst du häufig über die folgenden Begriffe stolpern:
- NIST: National Institute of Standard and Technology. (MNIST: zusätzlich Modified)
- MNIST-Datenbank: Klassische Datensammlung mit Trainings- & Testbildern. Vergleichbar mit Hello World-Programmen bei Programmiersprachen.
- Klassen: Hiermit werden Kategorien beschrieben.
- Samples: Hierbei handelt es sich um Datenpunkte.
- Label / Klassenbezeichnung: Dies bestimmt die zum Sample gehörende Klasse.
Tensor
Dabei handelt es sich um einen Container für Daten. Diese Daten sind in den meisten Fällen Zahlen. Tensoren sind eine Verallgemeinerung von Matrizen. Wenn man von Tensoren spricht, kommt oft auch der Begriff Dimension vor, was die Achse definiert. Tensor ist übrigens auch der Namensgeber für TensorFlow.
Sollte der Tensor nur eine Zahl enthalten, spricht man von einem Skalar (Nulldimensionaler Tensor). Hat man jedoch ein Array mit Zahlen, handelt es sich um ein Vektor (1D-Tensor). Eine weitere Variante sind 2D-Tensoren, welche Matrizen genannt werden. Dieser Name bleibt auch unabhängig davon, ob noch mehr Dimensionen dazu kommen. In der Regel findet man 0D-Tensoren bis 4D-Tensoren. Wichtige Attribute für Tensoren sind die Anzahl der Achsen, der “Shape” und der Datentyp.
Praxisbeispiele
-
Vektordaten
- (100000, 3) → 100'000 Personen mit 3 Informationen zur Person
-
Zeitreihen oder sequentielle Daten
- (100000, 280, 128) → 100’000 Tweets mit einer Zeichenlänge von 280 und 128 unterschiedlichen Zeichen
-
Bilddaten
- (128, 256, 256, 3) → 128 Farbbilder, Grösse von 256 x 256 und Info zum Farbtiefe
-
Videodaten
- (4, 240, 144, 3) → 4 Videos, 240 Frames, Grösse von 144 x 256 und Info zur Farbtiefe
Wichtig zu wissen ist ebenfalls, dass es Tensoroperationen gibt, welche die Grundlage eines neuronalen Netzes bilden. Bei einem normalen Computerprogramm wären diese mit binären Operationen (AND, OR, XOR, …) zu vergleichen. Da Tensoren wie Koordinaten eines Koordinatensystems angesehen werden können, lassen sich Tensoroperationen auch geometrisch interpretieren. Deshalb kann man auch vereinfacht sagen, dass ein neuronales Netz eine sehr komplexe geometrische Transformation ist.
Verlustfunktionen
Mit der Verlustfunktion wird beschrieben, wie gut ein neuronales Netz für eine Aufgabe ist. Mit der Funktion an sich wird der Wert berechnet, der die Trainingsdaten beurteilt. Je geringer dieser Wert ist, desto genauer ist das Ergebnis.
Optimierer
Mit dem Optimierer wird festgelegt, wie die Gewichtung aufgrund des Verlustscores angepasst wird. Dieser Vorgang geschieht automatisiert, damit das neuronale Netzwerk selbst lernt.
Aufbau
Keras
Bei Keras handelt es sich um eine Deep Learning API, welche in Python geschrieben wurde. Sie bietet eine leichte und schnelle Implementierung von neuronalen Netzwerken. Durch Keras hast du die Möglichkeit, deinen Code auf der CPU sowie GPU auszuführen.
Dabei bietet Keras eine Bibliothek für Modelle an und kann auf Backend-Engines wie TensorFlow, Theano-Backend oder CNTK zurückgreifen. Ein Beispiel für einen typischen Keras Workflow ist das Definieren der Trainingsdaten mittels Eingabetensoren inklusive der Zielwerttensoren. Im Anschluss muss das Modell, also das neuronale Netzwerk, mithilfe von Layern bestimmt werden. Als dritter Schritt ist das Konfigurieren des Lernvorgangs notwendig. In diesem wird die Verlustfunktion, der Optimierer und die zu überwachende Kennzahl festgelegt. Zum Schluss kann der Trainingsvorgang gestartet werden.
Machine Learning
Teilgebiete des Machine Learnings
Überwachtes Lernen
Dies ist die meistverbreitete Art des Lernens mit Neuronalen Netzen. Dabei werden Eingabedaten anhand von Beispieldaten bestimmten Zielwerten zugeordnet.
Beispiele:
-
Binäre Klassifizierung
-
Mehrfachklassifizierung
-
Skalare Regression
-
Sequenzerzeugung: Hinzufügen einer Bildbeschreibung.
-
Vorhersage von Syntaxbäumen: Sätze in ihre Bestandteile zerlegen.
-
Objekterkennung: Objekt innerhalb eines Bildes erkennen.
-
Bildsegmentierung
Unüberwachtes Lernen
Dieses Verfahren kommt meist bei der Visualisierung, Komprimierung und Bereinigung von Daten zum Einsatz. Vor allem Datenanalytiker nutzen dies häufig.
Selbstüberwachtes Lernen
Dies ist sehr eng mit dem überwachten Lernen verbunden. Der Unterschied ist aber, dass keine Klassenbezeichnungen von Menschen vorgegeben werden. Diese werden stattdessen anhand der Eingabedaten erzeugt. Ein Beispiel hierfür wären Autoencoder.
Verstärktes Lernen
Dabei werden Aktionen beispielsweise dadurch erlernt, dass ein neuronales Netzwerk einen Bildschirm eines Videospiels beobachtet und für die Maximierung des Punktestandes Steuerungsanweisungen ausgibt.
Training und Bewertung
Wenn man ein neuronales Netzwerk trainiert, sollte man jedes Mal zwischen Trainingsdaten und Testdaten unterscheiden und diese unterteilen. Mit den Trainingsdaten soll das Netz trainiert werden und passende Regeln erkennen. Mit den Regeln sollen anschliessend vorhersagen getroffen werden und anhand von Testdaten überprüft werden, wie gut die Vorhersage ist. Benutzt man die Trainingsdaten auch zum Überprüfen, werden die Vorhersagen bei neuen Daten schlechter. Dabei redet man dann von einer Überanpassung. Aus diesem Grund sollte man Daten in Trainings-, Validierungs- und Testdaten aufteilen. Dabei werden die Trainingsdaten für das reine trainieren verwendet. Die Leistung des Netzes wird mittels der Validierungsmengen überprüft. Sobald das Training abgeschlossen wird, gibt es einen Testlauf mit Testdaten.
Hierfür gibt es auch einige Bewertungsverfahren, die man kennen sollte:
Holdout-Methode
Bei dieser Methode geht es einfach darum, dass Sie von der gesamten Menge an Daten einen kleinen Teil für Testzwecke aufbehalten sollten. Oft gibt es hier das Problem, dass es nicht genug Testdaten bzw. Trainingsdaten gibt.
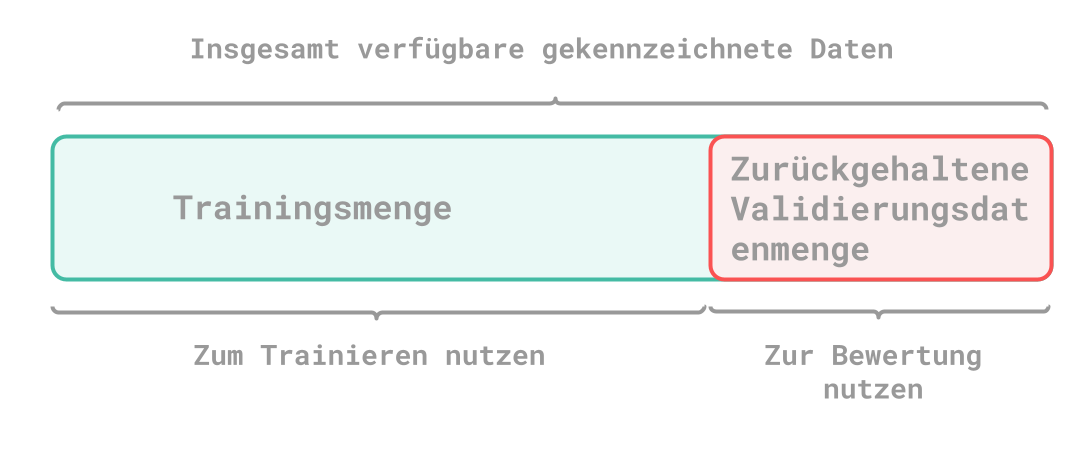
K-fache Kreuzvalidierung
Eine weitere Variante ist die Kreuzvalidierung. Dabei werden die vorhandenen Daten in mehrere Teilmengen (K) aufgeteilt. Dann wird ein Teil für das Testen verwendet und K-1 Teile für das Trainieren. Am Ende ergibt sich der gesamte Score aus den Scores der einzelnen Durchläufe.

Falls du jedoch nicht genug Testdaten haben solltest, wäre die K-fache Kreuzvalidierung mit Durchmischen eine weitere Variante, die du verwenden könntest. Dabei kommt ein weiterer Schritt dazu, der die Daten jedes Mal vor dem Aufteilen durchmischt. Hier ist jedoch zu erwähnen, dass auch der Rechenaufwand um einiges höher ist.
Auswahl von Trainingsdaten
Beim Auswählen von Trainingsdaten gibt es einige Dinge, die du auf jeden Fall beachten solltest. Vor allem muss es sich bei der Aufteilung um sinnvolle Daten handeln. Ist dein neuronales Netzwerk beispielsweise für die Erkennung von Zahlen gedacht und du teilst deine Daten so auf, dass in den Trainingsdaten die Ziffern 0-6 und in der Testdaten die Ziffern 7-9 sind, dann sind die Daten nicht wirklich repräsentativ.
Ein weiterer Punkt, der beachtet werden sollte, ist der zeitliche Aspekt. Ein Beispiel hierfür wäre ein Modell für die Wettervorhersage, denn hier müssen die Test- und Validierungsdaten in der Vergangenheit liegen, um überprüfen zu können, ob die Vorhersagen auch stimmen.
Ebenfalls solltest du beachten, dass es keine doppelten Daten geben sollte. In diesem Fall kann es nämlich dazu kommen, dass du mit Trainings- und Testdaten trainierst, was unbedingt zu vermeiden ist.
Datenvorbereitung
Damit du deine Daten auch für neuronale Netzwerke nutzen kannst, müssen diese in eine bestimmte Form gebracht werden.
Vektorisierung
Bei der Datenvektorisierung geht es darum, deine Eingabewerte sowie Zielwerte so umzuformen, dass diese innerhalb von Tensoren verwendet werden können. Dabei handelt es sich um Fliesskommazahlen oder ganze Zahlen. Sollte es sich beispielsweise um Texte handeln, dann könne diese als Integerlisten, welche für Wortsequenzen stehen, dargestellt werden. Diese können wiederum in float32-Tensoren umgewandelt werden.
Normierung
Bei der Normierung geht es eigentlich darum, dass passende Werte vorliegen. Dabei sollten kleine Wert gewählt werden, welche im Bereich zwischen 0 und 1 liegen. Dies kann beispielsweise durch eine Division der Daten vor dem Hinzufügen erreicht werden. Ein weiteres Merkmal sollte die Verwendung von gleichartigen Werten sein. Dies bedeutet, dass die Werte etwa demselben Wertebereich entsprechen sollten.
Fehlende Werte
Sollten dir bei den Beispieldaten Werte fehlen, so kannst du dafür einfach 0 einsetzten. Das gilt jedoch nur, solange 0 keine Bedeutung hat. Durch das setzen von 0 wird das neuronale Netz lernen, dass es sich dabei um fehlende Werte handelt. Wenn du diesen Fall auf diese Art abdeckst, sollten auf jeden Fall auch Testdaten mit fehlenden Werten hinzufügt werden.
Merkmalerstellung
Hierbei geht es darum, die Aufgabe im Voraus schon so zu formulieren, damit sie so einfach wie möglich gelöst werden kann. Dadurch, dass du die Transformation bereits mitgibst, lässt sich Rechenleistung sparen. Dies war besonders früher oft notwendig, weil einige Algorithmen gar nicht die Möglichkeit hatten, bestimmte Merkmale zu erlernen.
Verbessern von Modellen
Bei dem Auswerten bzw. dem Vorhersagen von Werten kommt es ab einem bestimmten Zeitpunkt immer zu einer Überanpassung, falls man nichts dagegen unternimmt. Dabei ist das Thema Optimierung wichtig, denn so lassen sich Anpassungen an einem Modell vornehmen, um bei den Testdaten das optimale Ergebnis zu erreichen.
Ein weiterer wichtiger Punkt ist die Verallgemeinerungsfähigkeit, welche beschreibt, wie gut die Ergebnisse mit unbekannten Daten ausfallen. Während den ersten Trainingsläufen verbessert sich die Verallgemeinerungsfähigkeit. Wiederholt man dies jedoch zu oft, fällt der Validierungsscore und man hat eine Überanpassung. Dies passiert, weil das Model bestimmte Muster in den Trainingsdaten erkennt und diese zur Gewohnheit werden. Dadurch sind diese Muster für neue Daten nun nicht mehr so wichtig. Um dem entgegenzuwirken, kann man dem Modell neue Trainingsdaten hinzufügen, um die Verallgemeinerungsfähigkeit wieder zu verbessern.
Eine weitere Variante ist das Begrenzen von Informationsspeicherung, wodurch sich das Modell auf auffälligere Muster konzentrieren soll. Dies wäre eine Regularisierung, für die es einige Beispiele gibt wie das verkleinern von Neuronalen Netzwerken, die Anpassung der Gewichtung oder die Drop-out-Regularisierung.
Machine Learning Workflow
Als ersten Schritt solltest du die Aufgabe genau definieren. Dazu gehört die Bestimmung der verwendeten Eingabedaten und der Vorhersage, die getroffen werden soll. Um dies auch darstellen zu können, bzw. erst einmal erlernen zu können, solltest du entsprechende Trainingsdaten zu Verfügung haben. Ebenfalls solltest du dir Gedanken zum Aufgabentyp machen. Der Aufgabentyp gilt als Grundlage für die Modellarchitektur und weitere Parameter.
Anschliessend solltest du dir überlegen, wie du überprüfen kannst, ob die Vorhersagen erfolgreich sind oder nicht. Daraus kannst du weitere Entscheidungen über die Wahl der Verlustfunktion treffen. Ebenfalls solltest du dich auch für eine Bewertungsmethode entscheiden.
Sobald diese Entscheidungen getroffen sind, geht es nun darum, deine Daten vorzubereiten. Dazu gehört das Umformen in Tensoren, die richtigen Werte für deine Daten zu finden, und zu entscheiden, ob eine Merkmalerstellung notwendig ist.
Fazit
Mit diesem Techup konnte ich dir hoffentlich die Grundlagen für das Thema meines nächsten TechUp, TensorFlow, etwas näherbringen. Das soll dir helfen zu verstehen, was Dinge wie Machine Learning oder Deep Learning überhaupt sind. Ebenfalls hast du nun schonmal die wichtigsten Begriffe gehört, welche dir den Einstieg in das nächste Thema vereinfachen werden. Weiter so!