
Folgende Fragen wollen wir uns in diesem TechUp beantworten:
- Was ist Rook❓
- Was ist Ceph❓
- Wie hängen Rook und Ceph zusammen❓
- Wie kann ich Rook in meinem Kubernetes-Cluster einsetzen❓
- Wann macht es Sinn, Rook einzusetzen❓
Was ist Rook❓
Rook ist ein Open-Source, cloud-native Speicher-Orchestrator für Kubernetes, welcher das Management von Speicher in Kubernetes-Clustern vereinfacht. 💡
Schauen wir uns doch dazu ein Bild an…
Figure: Source: DALL-E, OpenAI
Gut, zugegeben, DALL-E hat zwar ein schönes und eindrückliches Bild generiert, aber wirklich schlau werden wir daraus nicht. 🤓 Also Back to Basics:
Klassischerweise wird Speicher vom Cloud-Provider bereitgestellt und man muss sich keine Gedanken darum machen. Was aber, wenn man Speicher in seinem eigenen Kubernetes-Cluster benötigt? Hier kommt Rook ins Spiel.
Hinter Rook stecken Maintainer von Cybozu, IBM, RedHat, Koor, Upbound und viele andere. Insgesamt sind es über 400 aktive Contributors, die das golang-Projekt vorantreiben.
Auf der CNCF Landscape ist Rook in der Kategorie “Cloud Native Storage” zu finden und dort als einziges Projekt mit dem Status “Graduated” gelistet. Vom Sandbox Status im Januar 2018 vergingen gut zwei Jahre, bis Rook im Oktober 2020 den “Graduated” Status erhielt.
Rook liefert Minor Releases alle 4 Monate, Patch Releases alle 2 Wochen. Dies spricht für eine aktive Community und ein gesundes Projekt.
Rook verfolgt folgende Ziele:
- Speicher im Kubernetes-Cluster nativ (PVCs) bereitstellen
- Automatische Deployments, Configs & Upgrades
- Management des Speichers mit einem Operator und CRDs (Custom Resource Definitions)
- Open Source!
- Auf Ceph aufbauend
- High Availability & Disaster Recovery
Rook kann überall installiert werden, wo Kubernetes läuft! Zu den Voraussetzungen zählen aktuell eine Kubernetes-Version zwischen v1.26 und v1.31. Ausserdem benötigt man Disks, welche nicht partitioniert oder formatiert sind und auf die Rook zugreifen kann.
Ok gut, verstanden, Rook ist ein Storage-Orchestrator für Kubernetes, aber was ist Ceph❓
Was ist Ceph❓
Ceph ist ein Open-Source, Distributed Storage System, welches 2007 in Kalifornien vorgestellt wurde. Die Firma hinter Ceph wurde 2014 von RedHat übernommen und wird dort heute noch weiterentwickelt. Ceph selbst ist in C++ geschrieben.
Grundlegend ist Ceph im Aufbau hochverfügbar; mehrere Ceph Nodes bilden einen Ceph Cluster. Dateien werden redundant gespeichert, was die Ausfallsicherheit erhöht. Persistente Daten liegen immer auf mehreren Nodes, sodass ein Ausfall einer Node keine Auswirkungen auf die Datenverfügbarkeit hat.
Ceph ist in der Industrie stark verbreitet; eins der grössten Ceph-Cluster steht beim CERN in Genf.
Ceph bietet drei Arten von Speicher:
- Block Storage mittels RBD (Rados Block Device)
- File Storage mittels CephFS (Ceph File System)
- S3 & Swift Object Storage mittels RGW (Rados Gateway)
Dadurch kann Ceph für zahlreiche Anwendungsfälle eingesetzt werden, von Datenbanken über File-Server bis hin zu Backups.
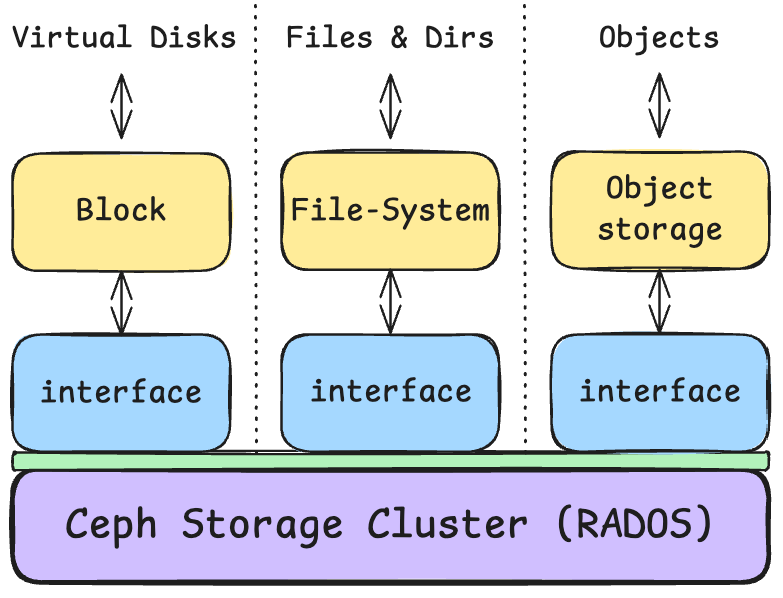
Figure: Source: Selfmade
Schön zu sehen im oberen Diagramm ist, dass alle Typen unter der Haube im RADOS (Reliable Autonomic Distributed Object Store) zusammengefasst sind. Die unterschiedlichen Typen an Speichern werden über Interfaces bereitgestellt, die auf dem RADOS-Backend aufsetzen.
Ceph kann nur auf Linux-Systemen installiert werden.
Ein Big Picture von Ceph könnte dann so aussehen:
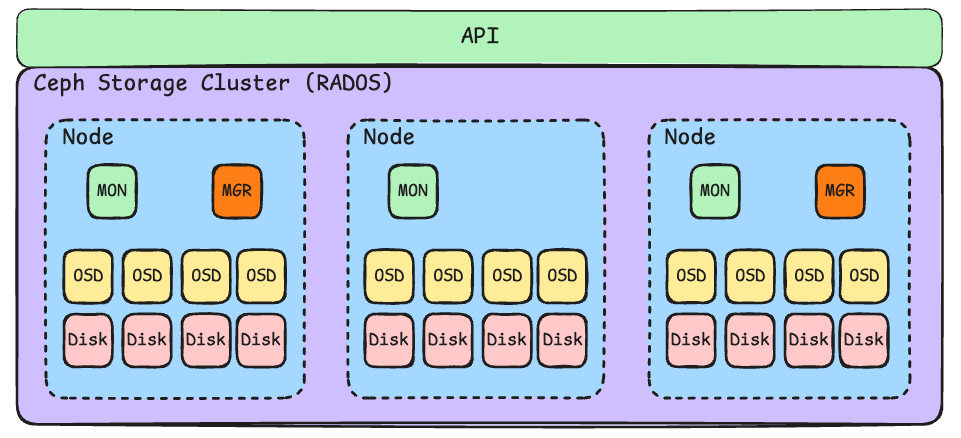
Figure: Source: Selfmade
Wie im oberen Bild schön zu sehen ist, besteht das Ceph Cluster aus mehreren Nodes, um die Ausfallsicherheit zu gewährleisten. Mehrere Clients können so über standardisierte Schnittstellen auf den Ceph-Cluster zugreifen. Die Daten werden mit den OSDs (Object Storage Devices) auf den jeweiligen Disks gespeichert und repliziert. Die Monitore (MONs) verwalten den Cluster, und die Manager (MGRs) sind für Überwachung und Reporting zuständig.
Ceph selbst ist Open-Source, jedoch bieten zahlreiche Enterprise-Vendors Lösungen an, wie z.B. RedHat mit Ceph Storage.
Selbstverständlich hat Ceph auch ein Dashboard, um den Cluster zu überwachen und zu managen.
Hier will ich nicht weiter in die Tiefe gehen – Ceph ist ein komplexes Thema! Weitere Infos sind hier oder hier oder in der offiziellen Doku zu finden.
Gut, Rook ist also ein Storage-Orchestrator für Kubernetes und Ceph ist ein Distributed Storage System. Wie hängen die beiden zusammen❓
Wie hängen Rook und Ceph zusammen❓
Rook ist ein Operator für Ceph, der das Management von Ceph in Kubernetes-Clustern vereinfacht. Rook baut also auf Ceph auf und bietet eine Kubernetes-native Schnittstelle für das Management von Ceph.
- Rook = Operator, der für das Management von Ceph zuständig ist
- CSI = Container Storage Interface, Standard für Speicher in Kubernetes
- Ceph = Storage-Backend, Data-Layer
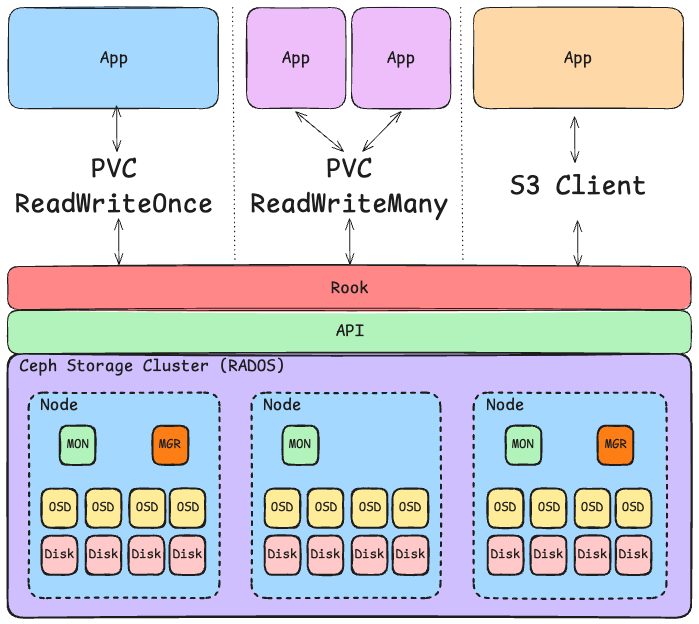
Figure: Source: Selfmade
Im oberen Bild ist das Zusammenspiel von Rook, Ceph und Kubernetes dargestellt. Unterschiedliche Apps nutzen entweder einen Persistent Volume Claim (PVC) oder einen S3 Client, um auf den Speicher zuzugreifen. Der Rook Operator abstrahiert das CSI (Container Storage Interface) Plugin und schafft eine Brücke zwischen Kubernetes und Ceph.
Rook überwacht zudem den Cluster, um sicherzustellen, dass der Storage stets verfügbar und in gutem Zustand ist. Genau dies ist eine der Hauptaufgaben des Rook Operators: Er interagiert mit Ceph und sorgt für die Verfügbarkeit des Storage.
Was passiert noch im oberen Beispiel:
- Die blaue App nutzt einen eigenen PVC vom Typ Block Storage als Volume-Mount.
- Die lila App nutzt ein gemeinsames PVC als shared Filesystem, beide Apps können so auf die gleichen Daten zugreifen, sowohl lesend als auch schreibend. Ceph stellt sicher, dass die Daten konsistent sind und es zu keinen Konflikten kommt.
- Die orange App nutzt einen Standard-S3-Client, um auf den Object-Storage zuzugreifen. In diesem Fall erstellt der Rook Operator automatisch einen Bucket und stellt die Zugangsdaten als Secret & ConfigMap bereit.
Weitere Infos sind hier zu finden: Rook Docs Storage Architecture
Wo die Daten schlussendlich physisch liegen, hängt auch immer von der Konfiguration unserer CephCluster CRD ab.
Wie kann ich Rook in meinem Kubernetes-Cluster einsetzen❓
Du kannst Rook ganz einfach auf folgende Weise in deinem Kubernetes-Cluster einsetzen:
- Den Quickstart Steps folgen und das Example deployen (nicht empfohlen für Production)
- Die Helm Charts für Rook-Ceph-Operator und Rook-Ceph-Cluster nutzen
Gehen wir theoretisch Schritt für Schritt durch den Quickstart Guide:
Um Rook nutzen zu können, müssen wir zuerst die Custom Resource Definitions (CRDs) von Rook installieren.
Anschliessend wird das common.yaml File applied, das den Namespace und zahlreiche Service-Accounts sowie RBAC-Rollen und -Bindings erstellt.
Danach wird das operator.yaml File applied, das den Rook-Operator im Cluster konfiguriert und deployed.
Und dann ist unsere grundlegende Rook-Installation schon fertig! 🎉
Nun können wir ein Rook-Ceph-Cluster deployen, schauen wir uns aber erst kurz an, was dazu gehört.
Grundlegend gehören zu einer Rook-Installation folgende Komponenten:
- Mon (Monitore): Verwalten die Cluster-Topologie und sorgen für Konsistenz. Drei Monitore sind Standard für Hochverfügbarkeit.
- Mgr (Manager): Überwacht Cluster-Metriken und den Status und führt Verwaltungsfunktionen aus. Meistens mit einem aktiven und einem Standby-Manager.
- OSD (Object Storage Daemons): Speichert Daten und sorgt für deren Replikation im Cluster. Jede OSD repräsentiert eine Speichereinheit, z. B. eine Festplatte. Die OSDs laufen hier in einer Primary/Secondary Konfiguration, der Primary repliziert die Daten auf die Secondarys.
- MDS (Metadata Server): Verwalter für Metadaten im CephFS, dem dateibasierten Speicher. Notwendig für CephFS, aber nicht für Block- oder Objektspeicher.
- RBD (RADOS Block Device): Bietet blockbasierten Speicher, der direkt in Kubernetes als Persistent Volume (PV) eingebunden werden kann. Ideal für Datenbanken und Anwendungen, die konsistente und schnelle Blockspeicherung benötigen.
- RGW (RADOS Gateway / Ceph Object Gateway): Ermöglicht den Zugriff auf Objektspeicher via HTTP(S) mit S3- oder Swift-kompatiblen APIs. Perfekt für Cloud-basierten Objektspeicher, um Daten über RESTful APIs bereitzustellen.
All diese Komponenten müssen aber nicht manuell konfiguriert werden, sondern können über die Custom Resource Definitions (CRDs) von Rook konfiguriert werden.
Schauen wir uns beispielhaft mal das cluster.yaml File aus dem Quickstart-Beispiel an.
Wir sehen sofort, dass eine Custom Resource Definition (CRD) vom Typ ceph.rook.io/v1 CephCluster für den Rook-Ceph-Cluster angelegt wird. Diese Ressource konfiguriert den Cluster und legt Anzahlen, Parameter und weitere grundlegende Einstellungen fest.
- Cluster Name & Namespace: Der Cluster heisst
rook-cephund läuft im Namespacerook-ceph. - Ceph Version: Die Image-Version ist
quay.io/ceph/ceph:v18.2.4, hiermit definieren wir die Version von Ceph und Rook. - Monitore (Mon): Drei Monitore für Ausfallsicherheit, jeweils auf separaten Nodes. Mit
allowMultiplePerNodekönnten wir erlauben, dass mehrere Monitore auf einem Node laufen, was in Production jedoch keinen Sinn ergibt, da ein Ausfall des Nodes den gesamten Cluster gefährden würde. - Manager (Mgr): In diesem Setup werden zwei Manager gestartet; einer ist aktiv und einer passiv im Standby-Modus. Hier muss noch
rookals Module aktiviert werden. - Dashboard & SSL: Das Ceph-Dashboard ist aktiviert und über SSL gesichert.
- Monitoring: Hier können wir noch Prometheus aktivieren, um den Cluster zu überwachen. Weiter unten im File werden dann noch Configs zum Speicher, Failover und Health-Checks definiert.
Gut, das war ein kurzer Einblick in die Konfiguration eines Rook-Ceph-Clusters. Brauche ich Rook in meine Kubernetes-Clsuter? 🤓
Wann macht es Sinn, Rook einzusetzen❓
Gut, jetzt wissen wir grob und theoretisch, wie Rook funktioniert und wie es mit Ceph zusammenhängt. Aber wann macht es Sinn, Rook einzusetzen❓
Rook eignet sich hervorragend für Cloud-native Umgebungen, insbesondere Kubernetes-Cluster, die flexiblen und skalierbaren Speicher benötigen. Da Rook Ceph als Speicher-Backend verwendet, bietet es eine Lösung für Block-, Datei- und Objektspeicher in einem einzigen System. Dies macht es ideal für Umgebungen, die verschiedene Speicherarten benötigen und auf Automatisierung, Selbstheilung und Skalierbarkeit setzen. Besonders in On-Premises-Kubernetes-Clustern, die keinen direkten Cloudspeicherzugriff haben, ist Rook eine wertvolle Ergänzung. Bei Managed Clustern in einem PaaS (Platform as a Service) ist Rook oft nicht notwendig, da der Cloud-Provider bereits Speicherlösungen bereitstellt.
Für einfache Workloads, die keine hohen Speicheranforderungen haben, ist Rook jedoch oft overkill. Da Ceph vor allem bei grossen Datenmengen effizient arbeitet, kann der Einsatz in kleinen Umgebungen ineffizient und schwerfällig sein. Auch für extrem latenzkritische Anwendungen ist Rook weniger geeignet, da Ceph durch seine Architektur die Latenz erhöhen kann. Wenn ein Unternehmen bereits über einen gut funktionierenden externen Speicherservice verfügt, ist Rook oft nicht notwendig und erhöht nur die Komplexität.
Wie so oft also: Use-Case abhängig! 🤓
Schauen wir uns noch kurz die Vor- und Nachteile von Rook an:
Vorteile von Rook
- Integriert und Cloud-native: Nahtlose Integration in Kubernetes, der DevOps Engineer bekommt eigentlich nichts von Rook und Ceph mit.
- Multi-Protokoll-Unterstützung: Bietet Dateispeicher (CephFS), Blockspeicher (RBD) und Objektspeicher (RGW) in einem.
- Automatische Skalierung und Replikation: Bietet Selbstheilung und Datenreplikation zum Schutz vor Datenverlust.
- Flexible Konfiguration: Kann an verschiedene Workloads und Storage-Typen angepasst werden.
Nachteile von Rook
- Komplexe Verwaltung: Ceph ist mächtig, aber auch anspruchsvoll in der Konfiguration und Wartung.
- Hoher Ressourcenverbrauch: Beansprucht viele Ressourcen, was kleine Cluster überlasten kann.
- Latenz und Performance: Bei extrem niedrigen Latenzanforderungen weniger performant als spezialisierte Speicherlösungen.
- Fehlender Support für kleine Umgebungen: Für kleinere Umgebungen oft overkill und ineffizient.
Fazit
Theoretisch vielversprechend, wenn man es braucht und darauf angewiesen ist!
Aus meiner Sicht hat Rook den Graduated-Status bei der CNCF verdient und ist ein solides Projekt, das in vielen Kubernetes-Clustern eingesetzt wird. Die Integration von Ceph in Kubernetes ist ein mächtiges Werkzeug, um flexiblen und skalierbaren Speicher bereitzustellen. Für Unternehmen, die auf der Suche nach einer Cloud-nativen Speicherlösung sind, ist Rook definitiv einen Blick wert. Für kleinere Umgebungen oder latenzkritische Anwendungen ist Rook jedoch oft nicht die beste Wahl.
Nutzt man einen Managed Kubernetes-Cluster, ist Rook oft nicht notwendig, da der Cloud-Provider bereits Speicherlösungen bereitstellt.