
In diesem Techup geht es darum, zu zeigen, wie man am besten mehrere Events in ein einzelnes Kafka-Topic schreibt. Dazu habe ich mir einen Anwendungsfall ausgedacht. Bei uns erscheinen regelmäßig Blogartikel zu verschiedenen Themen, die wir Techups nennen. Außerdem haben wir schon seit einiger Zeit unseren eigenen Podcast namens Decodify. All dies ist Teil unseres internen Forschungs- und Entwicklungsprozesses und wird in unserem Techhub gesammelt. Deshalb gibt es in diesem Beispiel ein Topic namens Techhub, das Events vom Typ Techup und Decodify empfängt.
Nachstehend ist zu sehen, dass unterschiedliche Events in das Topic TechHub geschrieben werden sollen:
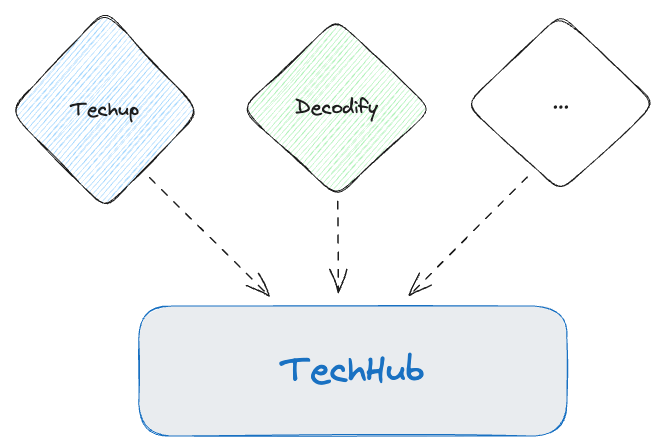
Praktische Umsetzung: Ein Kafka-Topic für mehrere Event-Typen
Dabei wird das Beispiel mit einer Quarkus Applikation in der Version 3.9 umgesetzt. Dazu kann man am besten bei Quarkus selbst das Grundgerüst erstellen.
Schema-Entwicklung: Grundlagen und Implementierung
Im ersten Schritt müssen wir unsere gewünschten Schemas erstellen, aus denen anschliessend die entsprechenden Java Klassen erstellt werden sollen.
Zunächst einmal das Techup-Schema — techup.avsc:
|
|
Ebenfalls notwendig ist unser Decodify Schema — decodify.avsc:
|
|
Damit es jedoch möglich ist, mehrere Einträge in das selbe Topic zu schreiben, benötigen wir noch ein weitere Datei, welche als eine Referenz auf die anderen beiden Schemas genutzt wird.
bnova_techup_techhub_topic_all_types.avsc:
|
|
Kafka Topics — Set-Up
Nun wird es Zeit das entsprechende Topic zu erstellen. Unser Techhub Topic muss innerhalb unseres Beispiel Projekts als Input und Output Topic definiert werden. Dies hat den Grund, dass wir später zu Testszwecken einen Endpunkt bereitstellen der in dieses Topic schreiben soll, damit wir testen können, dass auch beide Schemas ausgelesen werden können. Mittels dem Prefix mp.messaging.outgoing bzw. mp.messaging.incoming wird definiert, ob das Topic zum empfangen oder senden genutzt wird.
In unserem Beispiel wird der SmallRye Kafka Connector verwendet wird, um Nachrichten an Kafka zu senden und empfangen. Dies ermöglicht es der Anwendung, Nachrichten effizient an ein Kafka-Topic zu senden.
Die Einstellung mit dem Postfix topic definiert dabei den Namen des entsprechenden Topics. Zu dem muss der gewünschte Serializer und Deserializer definiert werden, damit die Daten korrekt verarbeitet werden können.
Damit es dem Deserializer möglich ist, das genaue Schema zu verwenden, das beim Schreiben der Daten verwendet wurde, wird specific.avro.reader aktiviert.
|
|
Essentielle Kafka-Services
Um verschieden Schemas zu nutzen benötigen wir ein Schema Registry. Dazu habe ich mich für die Lösung von Confluent entschieden. Zusammen bilden diese Services eine vollständige Kafka-Architektur, die über Docker bereitgestellt wird, und bieten eine robuste Plattform für die Nachrichtenübertragung und Schema-Verwaltung. Jeder Service spielt dabei eine spezifische Rolle:
Der Kafka Broker ist das Herzstück des Systems und verantwortlich für die Verwaltung und Speicherung von Nachrichten. Die Konfiguration legt die notwendigen Ports, Umgebungsvariablen und Listener fest, um die Kommunikation zu ermöglichen.
|
|
Die Schema Registry von Confluent, spezifiziert im zweiten Service-Block, ist entscheidend für das Schema-Management, das in Kafka-Umgebungen benötigt wird, um die Kompatibilität und Versionierung der Schemas zu gewährleisten, die für die Nachrichtenserialisierung verwendet werden. Die Konfiguration gewährleistet, dass die Registry über die nötigen Informationen verfügt, um mit dem Kafka Broker zu kommunizieren und Schemas effektiv zu speichern und zu verwalten.
|
|
Um die Benutzerfreundlichkeit zu erhöhen und eine grafische Oberfläche für die Interaktion mit dem Kafka-Cluster zu bieten, wird der Service kafka-ui eingesetzt. Dieses Tool ermöglicht es den Benutzern, die Themen, Partitionen, Nachrichten und Schemas innerhalb des Clusters visuell zu inspizieren und zu verwalten. Es ist besonders nützlich für das Debugging und Monitoring, da es einen schnellen Überblick und einfache Steuerung der Kafka-Ressourcen ohne komplizierte Befehlszeilenoperationen bietet.
|
|
Registrierung und Nutzung von Avro-Schemas
Nachdem die Schema Registry eingerichtet ist, müssen die vorbereiteten Schemas registriert werden. Dies geschieht durch die Konfiguration in den application.properties, wo die URL der Registry wie folgt angegeben wird:
|
|
Um die Schemas effektiv zu registrieren und verwalten, ist ein zusätzliches Plugin erforderlich. Die Avro-Schemas sollten in einer spezifischen Struktur im Projektverzeichnis abgelegt werden, damit die Abhängigkeiten / Referenzen aufgelöst werden können.
|
|
Das kafka-schema-registry-maven-plugin von Confluent wird in der pom.xml-Datei des Projekts konfiguriert. Dieses Plugin ermöglicht es, die Schemas direkt aus der Projektstruktur zu registrieren und sicherzustellen, dass sie mit den im Schema Registry definierten Kompatibilitätsrichtlinien übereinstimmen. Die Konfiguration des Plugins sieht wie folgt aus:
|
|
Um sicherzustellen, dass die erforderlichen Dependencies verfügbar sind, müssen die Confluent-Repositories zur pom.xml hinzugefügt werden. Dies ermöglicht Maven, die spezifischen Confluent-Pakete zu finden und zu laden:
|
|
Mit dieser Konfiguration ist man in der Lage, die Avro-Schemas effizient zu registrieren und sicherzustellen, dass sie korrekt validiert und kompatibel mit den Anforderungen der Kafka-Anwendungen sind.
Implementierung des Consumers
Nun fokussieren wir uns auf die Implementierung eines Kafka Consumers. Der Consumer wird durch eine Java-Klasse repräsentiert, die wir schlichtweg Consumer nennen. Um auf ein spezifisches Kafka-Topic zu hören, verwenden wir die Annotation @Incoming von MicroProfile Reactive Messaging. Hiermit wird angegeben, dass diese Methode Nachrichten aus dem Topic „techhub“ empfangen soll.
Für die Flexibilität im Umgang mit verschiedenen Schemata verwenden wir den SpecificRecord als Parameter der process-Methode. SpecificRecord ist eine Schnittstelle aus dem Apache Avro Framework, die es ermöglicht, generierte Avro-Objekte zu handhaben, die jeweils ein spezifisches Schema repräsentieren.
Aktuell ist die Funktionalität des Consumers darauf beschränkt, den eine Infos des empfangenen Avro-Records zu loggen. Die Klasse ist so konfiguriert, dass sie den Namen des Java-Klassenobjekts, das den Avro-Record repräsentiert, im Log ausgibt. In unserem Szenario erwarten wir, dass die Namen com.bnova.Techup und com.bnova.Decodify im Log erscheinen, je nachdem, welches Schema in den eingehenden Nachrichten verwendet wird.
|
|
Interaktives Testen der Topics
Um das Schreiben von Nachrichten in das Kafka-Topic „Techhub“ für Testzwecke zu ermöglichen, habe ich einen REST-Endpunkt implementiert, der es erlaubt, manuell Einträge für zwei unterschiedliche Objekttypen – Techup und Decodify – zu erstellen und zu senden. Der Endpunkt bietet zwei spezifische Pfade: /test/techup/{title} für ein Techup-Objekt und /test/decodify/{title} für ein Decodify-Objekt.
Für das Senden dieser Objekte ins Kafka-Topic wird der Emitter-Mechanismus von MicroProfile Reactive Messaging verwendet. Dieser Emitter wird mittels der Annotation @Channel mit dem Namen des Topics verbunden, in das geschrieben werden soll. Hierdurch ist es möglich, Nachrichten direkt aus der Anwendung heraus an das spezifizierte Topic zu senden.
Im Java-Code sieht das wie folgt aus:
|
|
Durch die Implementierung dieser Endpunkte kann der Nutzer durch einfache HTTP GET-Anfragen beispielhafte Techup und Decodify Objekte erstellen und an das Kafka-Topic senden. Diese Methode eignet sich hervorragend für das Debugging und Testing von Integrations- und Verarbeitungslogiken in der Kafka-Umgebung.
Inbetriebnahme
Um die benötigte Infrastruktur für unsere Kafka- und Quarkus-Anwendung zu testen, starten wir zuerst die Services über Docker Compose. Durch den Befehl docker compose up im Verzeichnis mit unserer docker-compose.yaml-Datei werden alle notwendigen Images heruntergeladen und die Container gestartet. Die korrekte Ausführung und den Status der Container können wir anschließend mit dem Befehl docker ps überprüfen. Das Ergebnis sollte in etwa so aussehen:
|
|
Als Nächstes überprüfen wir, ob die Schema Registry erfolgreich gestartet wurde und zugänglich ist, wobei zu diesem Zeitpunkt noch keine Schemas registriert sein sollten.
![]()
Sobald die Services laufen, starten wir unsere Quarkus-Anwendung im Entwicklungsmodus mit mvn quarkus:dev. Ist dieser Vorgang erfolgreich, sollten wir in der Kafka-UI das neu angelegte Topic bnova-techup.techhub-topic.v1 sehen können.
![]()
Nun ist es Zeit, die Schemas für unsere Events zu registrieren, die wir zuvor in unserem Maven-Projekt konfiguriert haben. Dies erreichen wir durch den Ausführungsbefehl mvn schema-registry:register, der die Schemas im Schema Registry registriert:
|
|
Die erfolgreiche Registrierung kann auch direkt in der Registry überprüft werden.
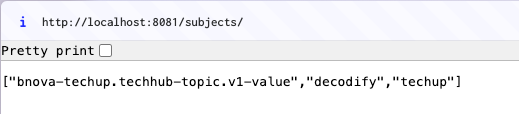
Der eigentliche Test erfolgt durch das Senden von zwei unterschiedlichen Event-Typen über unseren REST-Endpunkt. Wir verwenden hierfür Curl-Befehle, um jeweils ein Decodify- und ein Techup-Event ins Topic zu senden.
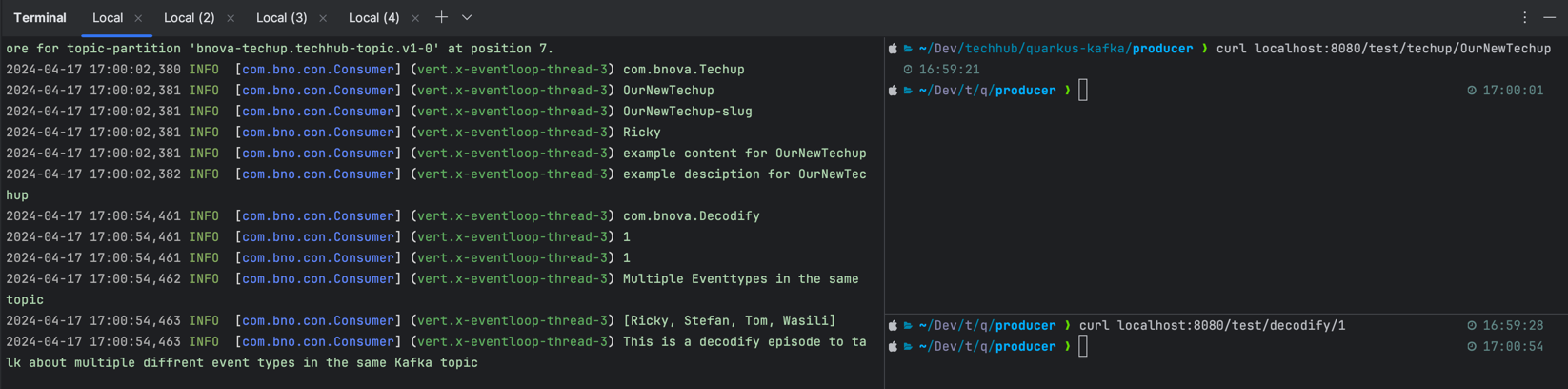
Wie man auf der rechten Seite sehen kann, wurde jeweils ein decofiy-Event und ein Techup-Event gesendet. Auf der linken sieht man den Output, der wie gewünscht die korrekten Klassen ausgibt.
Die Ergebnisse dieser Aktionen können wir nicht nur in der Konsole sehen, sondern auch in der Kafka-UI, wo die eingegangenen Nachrichten dargestellt sind.
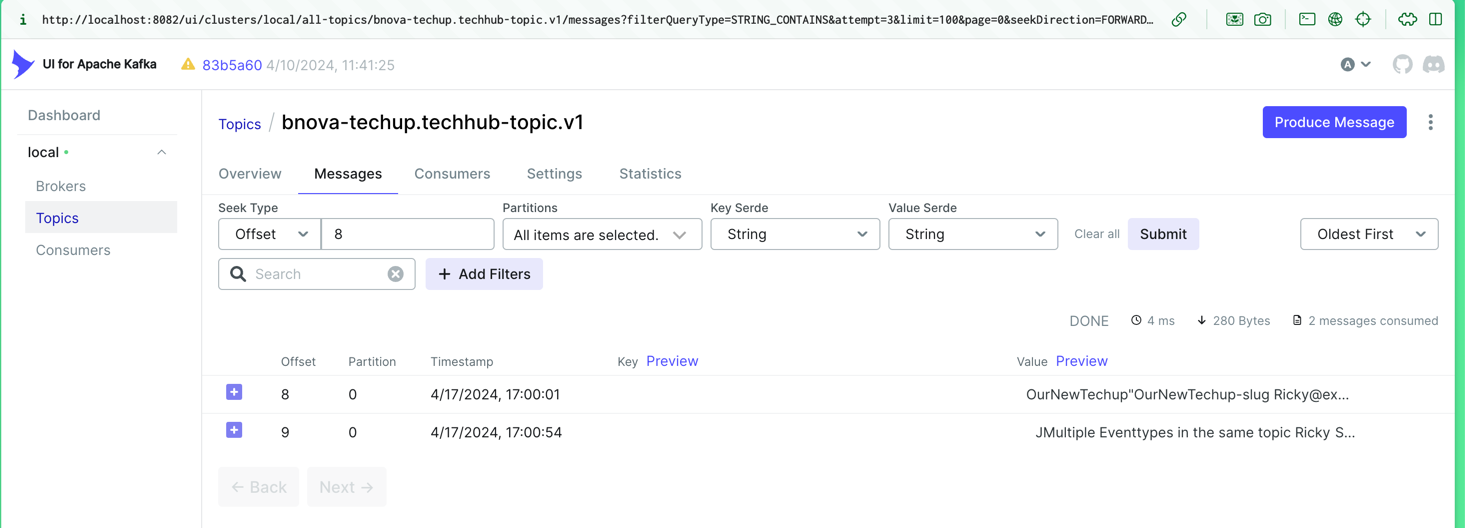
[!TIP]
Der gesamte Code kann auch über user Techhub Repository angeschaut werden
Fazit
In der Umsetzung dieses Ansatzes treten sowohl Herausforderungen als auch deutliche Vorteile auf. Technisch gesehen erhöht die Vereinfachung durch ein einzelnes Topic zunächst die Komplexität, insbesondere während der anfänglichen Konfiguration. Ein spezifischer Typ wird nicht direkt aus dem Topic ausgelesen, sondern als SpecificRecord verarbeitet, der vor der Weiterverarbeitung überprüft werden muss. Die Nutzung von Avro-Schemas schränkt zudem die Verwendung generischer Klassen oder Vererbungsstrukturen ein.
Auf der positiven Seite steht die signifikante Reduktion von Verwaltungsaufwand und Kosten, da weniger Topics gepflegt werden müssen und die Kosten oft pro Topic berechnet werden. Zudem erlaubt die Struktur eine flexible Erweiterung um neue Typen ohne großen Aufwand: Es sind lediglich das Erstellen eines neuen Schemas, dessen Registrierung und eventuell die Anpassung der Businesslogik notwendig. Dieser Ansatz bietet also eine effiziente Lösung für dynamische und skalierbare Datenarchitekturen in modernen Anwendungen.