Telepresence haben wir schon im TechUp zu Ambassador angeschaut und wollen dies nun vertiefen und Hands-On ausprobieren.
Hier nochmal als kleine Erinnerung:
Was ist Telepresence?
Telepresence erlaubt es, Teile einer komplexen Kubernetes-Applikation lokal laufen zu lassen.
Cloud Native Applikationen können schnell zu gross und zu komplex werden, um sie mit allen beweglichen Teilen und Abhängigkeiten lokal zu starten. Mit Telepresence wird ein smarter Proxy genutzt, um den Traffic eines bestimmten Services (Microservice) an die lokale Entwicklungsumgebung weiterzuleiten. So wird quasi der eigene Rechner oder Laptop in das Kubernetes-Cluster eingebunden.
Aufgerufen wird die gesamte Applikation dann über die normale URL oder eine gewisse Preview-URL, welche das Routing des Zielservices an die lokale Maschine aktiviert. Technisch gesehen wird beim Aufruf dieser Preview-URL ein Header an den Request gehängt. Anhand dieses Headers entscheidet dann der Telepresence-Proxy, ob der Traffic zum echten Service oder zum lokal laufenden Service gerouted werden soll.
Telepresence wurde vor Kurzem in der Version 2.0 veröffentlicht, welche nun nicht mehr in Python, sondern in Golang geschrieben ist. Ausserdem wurde die Version 2 speziell auf den Einsatz in Corporate Netzwerken, beispielsweise in Kombination mit VPNs entwickelt.
Konkret gibt es zwei Modi welche entscheiden, wie der Traffic weitergeleitet wird. Im Default Modus wird sämtlicher Traffic direkt an die lokale Maschine geleitet, die laufende Applikation wird somit vollständig beeinflusst. Im Collaboration-Modus ist es möglich nur bestimmte Benutzer, über eine preview URL, auf die lokale laufende Instanz eines Microservices zu leiten. So bleibt die Applikation an sich unberührt und kann weiterhin normal genutzt werden.
Der grosse Vorteil dieses Konzeptes ist die Zeitersparnis. Bei kurzen Tests im Cluster muss nicht immer der komplette CI/CD-Prozess durchlaufen werden, sondern es ist möglich nur bestimmte User auf die lokale Instanz zu lotsen. So erhält man ein wesentlich schnelleres Feedback und kann sich beim Pair-Programming viel einfacher austauschen. In einem heterogenen System ist es oft umständlich ein Bug lokal nachzustellen. Auch hier schafft Telepresence Abhilfe, indem man die lokale Instanz einfach debuggen und anschliessend den erforderlichen Fix direkt im Cluster vornehmen kann.
In folgendem Bild ist die Architektur von Telepresence beschrieben. Über einen sogenannten Traffic Manager wird gesteuert, wohin bestimmter Traffic geleitet wird. Der Traffic-Agent sorgt als Sidecar-Proxy Container dafür, dass alle Container angesprochen werden können.
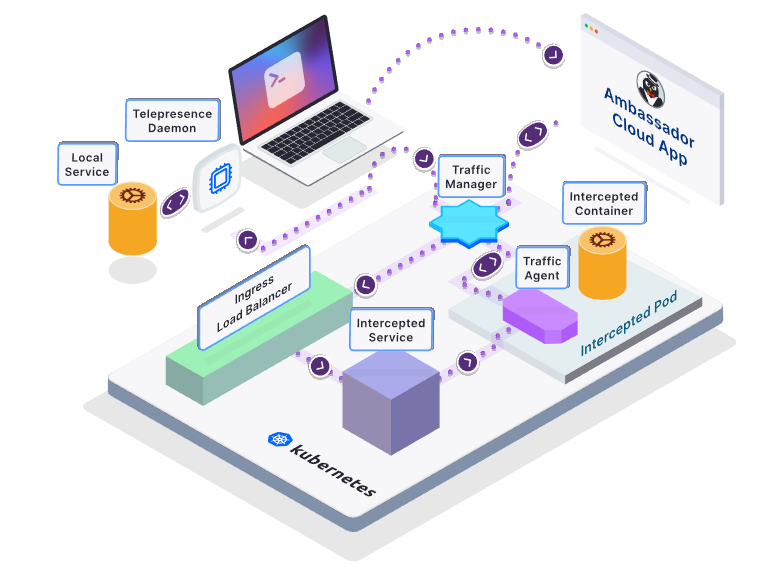
Figure: Quelle: 31.08.2021: https://www.getambassador.io/docs/telepresence/latest/reference/architecture/
Telepresence muss lokal und im Cluster installiert und konfiguriert werden. Das Forwarding kann dann vom lokalen
Rechner, mit gültiger kubeconfig, gestartet werden.
Hands On
Um Telepresence schnell und einfach testen zu können nutzen wir das demo Kubernetes Cluster von Ambassador, genaueres ist hier beschrieben. Selbstverständlich lässt sich Telepresence auch mit einem normalen oder gar self-hosted K8s-Cluster nutzen.
Wichtig ist hier, dass kubectl entsprechend konfiguriert wird um die neue kubeconfig.yaml zu verwenden. Dies kann
beispielsweise über eine Umgebungsvariable gemacht werden:
|
|
Nun wollen wir Telepresence auf unserem MacBook installieren, wir nutzen hierfür
den Quickstart Guide als Referenz. Nachdem wir z. B.
mittels brew Telepresence installiert haben können wir mit telepresence status unsere Installation verifizieren.
Dieses Command gibt uns nützliche Informationen über den aktuellen Stand der Daemons.
Anschliessend wollen wir unseren Telepresence-Client mit dem Traffic-Manager von Telepresence im Cluster verbinden. Einfach gesagt hängen wir mit diesem Command unseren Client in das Kubernetes-Cluster, als wären diese im selben Cluster und Netzwerk.
|
|
Um verifizieren zu können, dass wir effektiv im Cluster sind, können wir beispielsweise den Kubernetes API Server anfragen. Hier erwarten wir ein ‘401 Unauthorized’-Error.
|
|
Hier sehen wir nun, dass sämtlicher Netzwerktraffic inklusive DNS Resolving usw. ins Cluster geleitet wird und wir somit eine Verbindung zum API-Server in unserem Kubernetes-Cluster haben.
Dieses Setup erlaubt es uns unter anderem:
- auf alle Cluster Services zuzugreifen und diese zu nutzen
- nur einen dedizierten Microservice lokal zu entwickeln und alle echten beweglichen Teile im Cluster zu nutzen
- auftretende Fehler direkt debuggen, analysieren und lösen zu können ohne mühsames, lokales nachstellen
Dies bedeutet auch, dass wir nicht über externe URLs o. ä. beim Entwickeln auf Ressourcen im Cluster zugreifen müssen. Wir können, gleiche wie die Applikation oder die Microservices auch, die internen DNS- oder Servicenamen nutzen. Cool, oder? 🚀
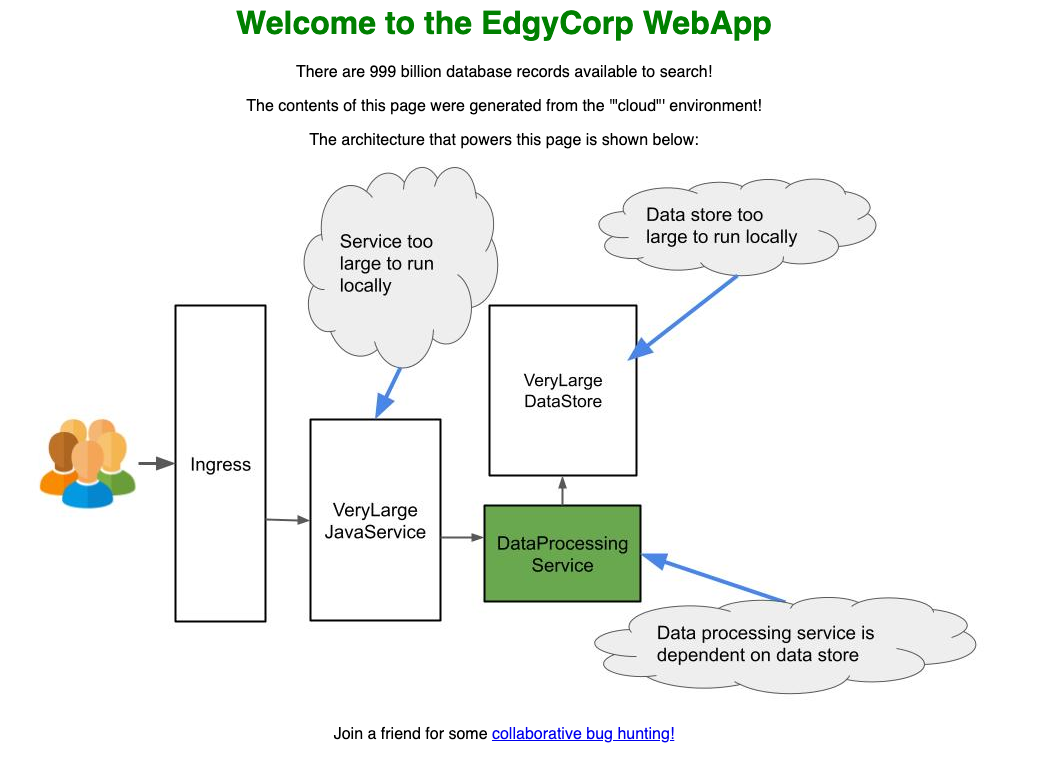
Als Nächstes wollen wir ein einfaches Demo-Projekt (wir nutzen hier das Demo-Projekt von Edgey Corp) mit folgendem Kommando deployen:
|
|
Im Detail besteht dieses Demo-Projekt aus drei unterschiedlichen Services, der VeryLargeJavaService fragt
den DataProcessingServicean und rendert die Page. Vom DataProcessingService bekommt der VeryLargeJavaService die
Farbe, welche beim Rendering dann für das Bild sowie die Überschrift genutzt wird. Der DataProcessingService besteht aus
unterschiedlichen Endpunkten, ein Endpunkt frägt im Hintergrund eine Datenbank, den VeryLargeDataStore ab.
Nach kurzer Zeit sehen wir via kubectl get pods, dass alle Pods laufen und die Demo einsatzbereit ist.
Via (http://verylargejavaservice.default:8080)[http://verylargejavaservice.default:8080] können wir das Demo-Projekt
aufrufen.
Dieser Aufruf würde ohne vorheriges telepresence connect nicht funktionieren, da der DNS Name sonst unbekannt ist. Da
unsere lokale Maschine Teil des Clusters ist, können wir diese Url direkt aufrufen.
In der Demo App ist nun ein grüner Title und ein grüner Pod zu sehen.
Der erste Change
Nun ist es so weit, wir wollen einen Change an dem Demo-Projekt machen und die lokale laufende Installation dann ins
Cluster einhängen. Wir wollen die Farbe der Überschrift, welche über den DataProcessingService abgefragt wird,
verändern.
Hierfür checken wir uns zuerst das Repository aus, installieren und starten den DataProcessingService.
|
|
Sobald alles gestartet ist, können wir die lokale Version des DataProcessingService prüfen, indem
wir localhost:3000/color aufrufen. Hier sehen wir, dass die Farbe ‘blue’ zurückkommt.
Nun wollen wir unsere lokal laufenden Applikation ins Cluster hängen, dies können wir mit folgenden Command machen. Wichtig ist hier, dass es sich um den Namen des Kubernetes Services handelt und der korrekte Port, welcher intercepted werden soll, angegeben wird. In unserem Beispiel wäre dies:
|
|
Dieses Command funktioniert allerdings nur, wenn das telepresence connect vorher korrekt ausgeführt wurde und noch
aktiv ist.
Laden wir nun unsere Page erneut sehen wir, dass die Überschrift blau ist, der neue Wert von unserem lokalen Microservice.
Technisch gesehen leitet dieses Command sämtlichen Datenverkehr, welcher im Cluster auf dataprocessingservice:3000
kommt weiter an localhost:3000 auf unserem lokalen Client. Läuft unsere Applikation lokal nicht oder auf einem anderen
Port kann keine Verbindung aufgebaut werden, dies erkennen wir an den null Werten im Beispiel und generell der Farbe '
grau’ im Bild.
Nun können wir auch hingehen und die Farbe beispielsweise auf ‘purple’ ändern. Hierfür passen wir die
Konstante DEFAULT_COLOR in der Datei edgey-corp-nodejs/DataProcessingService/app.js an. Der NodeJS-Server erkennt
automatisch die Änderung und compiled und restarted sich. Der Change ist dann nach kurzer Wartezeit direkt über die
normale Cluster Url sichtbar.
Zu guter Letzt können wir mit telepresence leave dataprocessingservice die aktuelle Interception wieder beenden.
Hierbei gibt man wieder den Namen vom Kubernetes-Service an.
Selbstverständlich lassen sich mehrere Interceptions gleichzeitig aufbauen, diese kann man sich mit telepresence list
auslisten lassen.
Eigene Preview Url
Im vorherigen Beispiel haben wir nun den kompletten Netzwerktraffic intercepted, der laufende Service im Cluster ist
somit komplett umgegangen worden. Oft hat man aber den UseCase, Changes erstmal nur einer dedizierten Person oder Gruppe
zu zeigen, hierfür bietet Telepresence eine sogenannte preview url. Hierfür muss man bei Ambassador angemeldet sein,
dies geschieht mit dem Command telepresence login.
Anschliessend starten wir einen neuen Intercept und werden nach weiteren Konfigurationen gefragt. Wir
nutzen verylargejavaservice.default, 8080 und n als Parameter. Den vierten Parameter können wir auf dem
Standard-Wert belassen.
In der Ausgabe des Commands bekommen wir dann eine Preview-URL. Die komplette Ein- und Ausgabe sollte dann ungefähr wie folgt aussehen:
|
|
Hier können wir nun über unsere Preview URL die lokal laufende Version ansehen und dies ohne, dass die
Cluster-URL http://verylargejavaservice.default:8080/ beeinflusst wird. Technisch gesehen fungiert das über einen
Header, welcher beim Aufruf der Preview Url gesetzt wird. Der Ingress- & Traffic-Controller erkennt anhand dieses
Header, wohin der Request geleitet werden soll.
Natürlich können wir den Header auch manuell an den Request appenden und müssen so die URL nicht umstellen.
Fehlerhandling
Bei uns kam es beim Ausprobieren immer wieder zu Abbrüchen bzw. Performanzproblemen. Augenscheinlich kommt es nach
längerer Wartezeit oder Inaktivität zu Timeouts bzw. Verbindungsabbrüchen. Also mögliche Lösung kann man
mit telepresence quit die aktuelle Sitzung komplett beenden und anschliessend wieder mit telepresence connect erneut
starten.
Fazit
Telepresence ist eine klasse Idee, um immer wieder auftretende Probleme oder Use-Cases schnell und einfach zu lösen. Leider kam es beim Evaluieren immer wieder zu Performance oder Stabilitätsproblemen, hier ist sicher noch Luft nach oben.
Nichtsdestotrotz ist der Einsatz von Telepresence zu empfehlen, sobald langwierige oder komplexe CI/CD-Prozesse Teil des Projektes sind. Grundsätzlich muss man sich aber die Frage stellen, ob man mit den echten Ressourcen im Cluster entwickeln will. Mit einem grossen Entwicklerteam kann es schnell zu Konflikten oder kaputten, falschen States kommen, hier könne man über den Einsatz von lokalen Mocks-Servern o. ä. nachdenken.
Stay tuned! 🚀