Robustheit und Resilienz in der Cloud
Erst wenn Systeme unter Last gesetzt werden, können auch dessen Anfälligkeit für Ausfälle und Fehlverhalten identifiziert werden. Das Gleiche gilt für umfangreiche Software-Systeme, welche heutzutage bevorzugt dezentral, kompartmentalisiert und containerisiert in komplexen Cloud-Architekturen laufen. Wo früher noch Monolithen die Software-Landschaft dominierten, kommen heute tendenziell immer wie mehr Verbunde von modularen Software-Komponenten, wie etwa Microservices, Container-Orchestrierung und Cloud-nativen Funktionen. Diese im Verbund gesteigerte Komplexität ist anfälliger für Ausfälle und ist somit anfällig für Verlust an allgemeiner Robustheit und Resilienz.
Indem solche Systeme proaktiv unter Belastung gestellt werden, können Ausfälle und identifiziert und behoben werden. Dies nennt sich Chaos Engineering und hat zum Zweck die Stabilität und Resilienz eines Systems zu optimieren und zu gewährleisten. Es ist in der heutigen Zeit unabdingbar geworden, ungeplantes Versagen und unvorhergesehne Ausfälle zu vermeiden. Falls kein entsprechendes Chaos Engineering betrieben wird, können schnell unangenehme und kostenintensive Situationen bei den Stakeholdern und in der User Experience entstehen. Laut einer Studie von Gartner aus dem Jahr 2014 kann ein Unternehmen im Durchschnitt bis zu $336’000 pro Stunde bei einem Ausfall verlieren. Dabei sind gerade E-Commerce-Webseiten am stärksten davon betroffen, wo es punktuell bis zu $13 Mio. pro Ausfallstunde kosten kann.
Ein Wort zu Antifragilität
Fragile Systeme brechen zusammen wenn diese eine gewisse Lastgrenze überschreiten. Robuste Systeme verstehen es weiterhin zu funktionieren jenseits dieser Lastgrenze. Antifragile Systeme werden noch robuster wenn diese Last ausgesetzt sind. Nassim Nicholas Taleb hat dies in seinem Buch Antifragile: Things That Gain From Disorder ausführlich beschrieben. Taleb resümiert die Prämisse von Antifragil wie folgt:
– Some things benefit from shocks; they thrive and grow when exposed to volatility, randomness, disorder, and stressors and love adventure, risk, and uncertainty. Yet, in spite of the ubiquity of the phenomenon, there is no word for the exact opposite of fragile. Let us call it antifragile. Antifragility is beyond resilience or robustness. The resilient resists shocks and stays the same; the antifragile gets better.
Chaos Engineering kann man somit mit einem antifragilisierenden Prozess gleichsetzen. Chaos Engineering zu betreiben ist dafür zu sorgen, dass ein Clusterbetrieb und dessen Services über die Zeit hinweg immer wie stabiler und resilienter laufen.
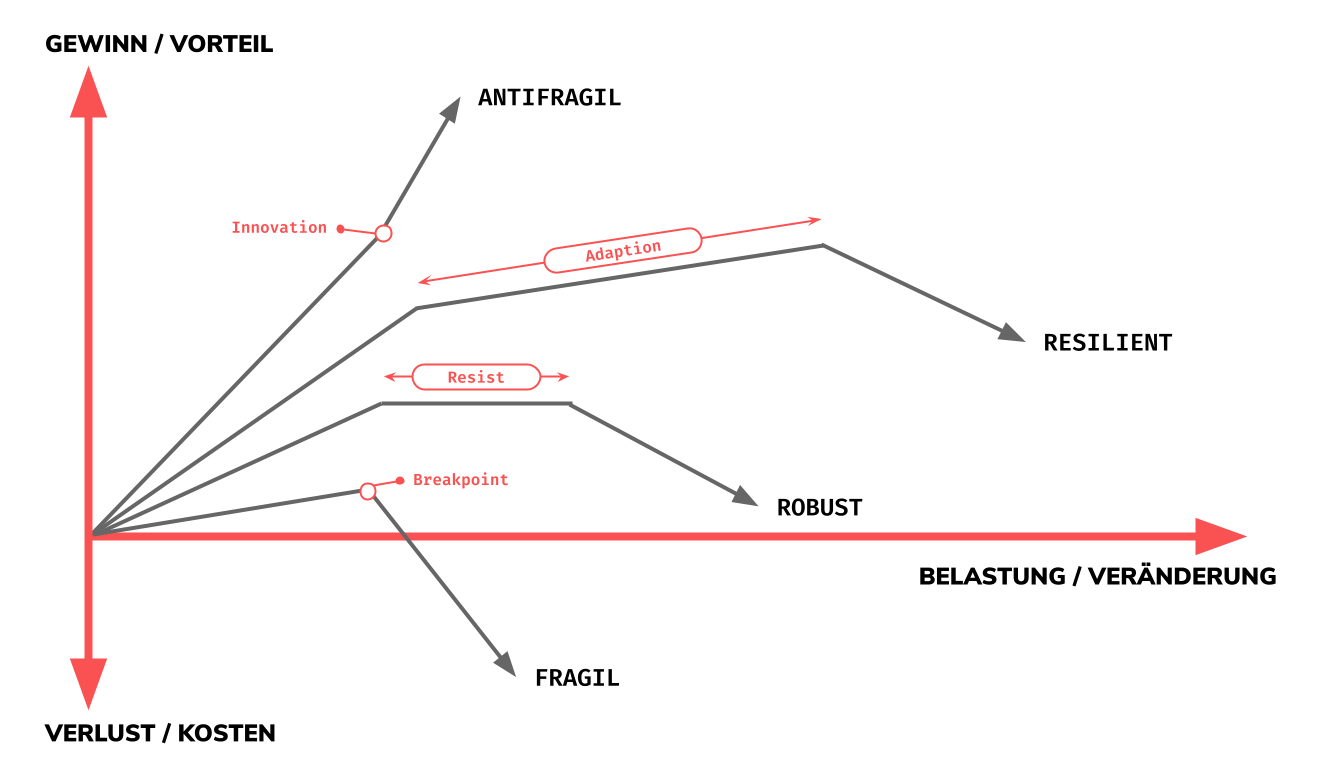
Wie im obigen Graph ersichtlich kann man 4 unterschiedliche Verhaltenstypen von Systemen unter Belastung unterscheiden:
-
Fragil: Bei fragilen Systemen gibt es eine inhärente Grenze der Belastung, einen sogenannten Breakpoint. Falls dieser Überschritten wird und das fragile System im Anschluss bricht, verursacht dass ungewollte, oft ungeplante, Mehrkosten. Diese Art von System ist gerade bei Software-Systemen zu vermeiden, da Ausfallkosten schnell signifikant werden können. Das überfüllte Glas fällt auf den Boden.
-
Robust: Bei robuste Systemen gibt es eine Phase des Wiederstandes (genannt Resist im Graph oben). Das robuste System zeichnet sich somit dadurch aus, dass es Belastung trotzen kann, diesen aber nicht etwa abwälzen kann und somit eine operationelles, sowie funktionales Plafond erreicht hat. Bei erhöhter Belastung bricht auch das robuste System zusammen. Das auf den Boden fallende Glas ist aus Zirkonium gefertigt.
-
Resilient: Bei resilienten Systemen gibt es eine Phase der Adaption. Das heisst, dass das System sich bei Belastung bis zu einem gewissen Grad anpassen kann und dadurch eine operationelle Funktionalität garantieren kann. Aber auch das resiliente System hat eine Belastungsgrenze und bricht bei zu hoher Belastung zusammen. Das auf den boden fallende Glas wird von einer ausgeklügelten Sicherheitsvorrichtung aufgefangen.
-
Antifragil: Das antifragile System verhaltet sich grundlegend anders als die 3 vorherigen Systemstypen. Das antifragile System kennt bei Belastung einen Innovationspunkt wobei es an operationeller Funktionalität zunimmt je höher dessen Belastung ausfällt. In anderen Worten gewinnt das antifragile System an Tüchtigkeit bei Belastung, da es weiss wie damit umzugehen ist. In der realen Welt sind menschengemachte antifragile Systeme oft mit einer Kultur des “We celebrate our failures”, eines im Silicon Valley verbreitetes Motto, verbunden.
Wie betreibt man Chaos Engineering
“Chaos Engineering lets you compare what you think will happen to what actually happens in your systems. You literally “break things on purpose” to learn how to build more resilient systems.”
– Gremlin über Chaos Engineering
Die Grundidee bei Chaos Engineering ist es Dinge bewusst und kontrolliert in einer Cluster-Konfiguration breaken zu lassen. Das Verfahren ist dabei empirisch aufgebaut. Es verhaltet sich wie bei einem wissenschaftlichen Experiment:
-
Zuerst plant man ein Experiment. Das Experiment beinhaltet eine oder mehrere Handlungen womit man den Cluster manipulieren möchte. Dazu gehört auch die Formulierung einer Hypothese der möglichen Auswirkungen der Handlungen.
-
Beim Durchführen des Experiments muss der Schaden kontrolliert in Grenzen gehalten werden. Das nennt man den Blast Radius. Dabei startet man mit den kleinsten, minimalsten Handlungseinheiten und tastet sich progressiv an die grösseren Handlungseinheiten heran.
-
Das Experiment endet sobald ein Problem ersichtlich geworden ist. Sofern kein kein Problem entsteht, kann das Experiment weitergeführt und bei Bedarf den Blast Radius angehoben werden.
-
Bei jedem Experiment muss der Impact bestimmt werden. Dies kann man mit vordefinierten Messgrössen bemessen. Dabei soll das subjektive Verhalten beurteilt, die Funktionalität anhand von Resourcenauslastung, State, Alerts, Events, Stacktraces, Breadcrumbs beziffert und mit weiteren Instrumenten wie Durchlaufszeiten bestimmt werden.
In anderen Worten zusammengefasst, fängt man zuerst mit einer Hypothese an, wie sich das Zielsystem verhalten sollte. Im Anschluss wird ein Experiment ausgeführt welches den minimalsten Schaden ausrichten könnte. Bei dem Experiment muss festgehalten werden was noch erfolgreich funktioniert und was nicht mehr. Nach dem ersten Experiment hängt man weitere Experimente an und steigert graduell den potentiellen Schadenausmass. Bei jeder Iteration wird der tatsächliche Schaden und Erfolg festgehalten. Am Ende der gesteigerten Experimentationskette ergibt sich ein klareres Bild wie sich das System in realen Welt verhaltet. Daraus ergeben sich weitere Erkenntnis woraus man Schwachstellen identifizieren und erste Lösungsansätze formulieren kann.
Sobald die Schachstellen identifiziert und Lösungsansätze formuliert sind, gilt es die umsetzen und das Gesamtsystem somit robuster und resilienter machen. Der gesamte Prozess des Chaos Engineerings wirkt somit antifragil. Go fix it!
Best Practices als weiterführende Prinzipien
Erfahrungsgemäss gibt es noch weitere, nennenswerte Faktoren, die man bei Chaos Engineering berücksichtigen möchte.
-
Varieren von Real-World Events
-
Ausführen von Experimenten direkt auf Produktion
-
Automatisieren von kontinuierlichen Experimenten
-
Minimierung des Blasts Radius
Auf der Suche nach Unbekannten Unbekanntheiten
Bei Chaos Engineering werden Systeme auf Schwachstellen untersucht. Diese Schwachstellen sind teilweise schon im voraus bekannt und werden erst bei gezieltem Testen ersichtlich. Bevor man Chaos Engineering betreibt muss man zuerst erkennen welche Art von Schwachstellen es in einem System geben kann. Der Grund dafür ist, dass man nur auf eine supoptimale Weise Experimente formulieren und dessen Priorisierung vornehmen kann, wenn man die Art von Schwachstellen noch nicht identifiziert hat.
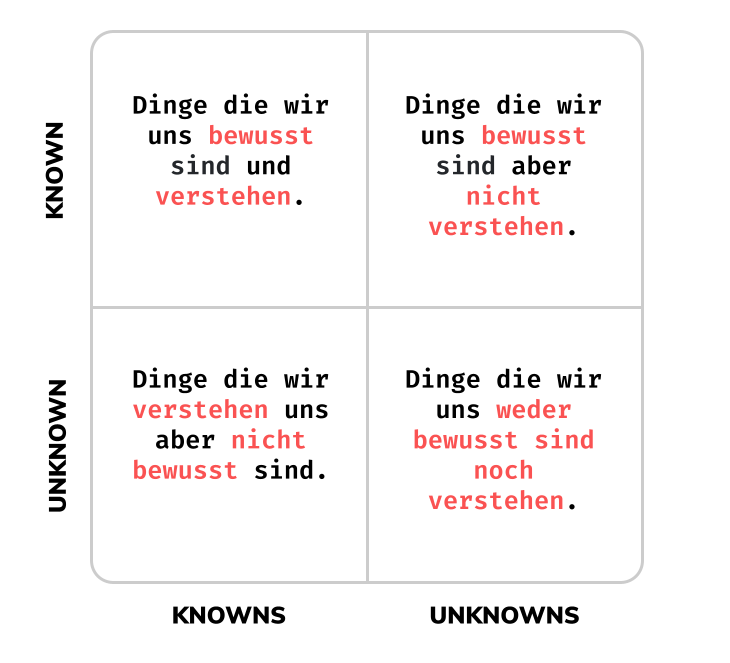
Dazu haben wir hier eine 4-Quadranten-Graphik gezeichnet womit man einfach 4 verschiedene Typen von Schwachstellen einordnen kann:
-
Known-Knowns: Dinge die wir uns bewusst sind und auch verstehen. Zum Beispiel: Wenn eine Instanz eines Services failed, wird durch einen Replication Controller eine zweite Instanz hochgefahren.
-
Known-Unknowns: Dinge die wir uns bewusst sind aber nicht zwingend verstehen. Zum Beispiel: Wenn der Cluster eine Meldung teilt, dass ein Pod seit 5 Minuten mit nur 1 Instanz fährt. Dabei wissen wir nicht ob die 5 Minuten die optimale Zeitspanne für den Betrieb darstellt.
-
Unknown-Knowns: Dinge die wir verstehen uns aber nicht bewusst sind. Zum Beispiel: Wenn zwei Replicas in einem Cluster gleichzeitig herunterfahren, wissen wir nicht zwingend wie lange es Montagmorgen dauern kann bis 2 neue Replicas anhand der Primary-Replica wieder hoch gefahren sein werden.
-
Unknown-Unknows: Dinge die wir uns weder bewusst sind noch verstehen. Zum Beispiel: Wir wissen nicht was genau passiert wenn ein ganzer Cluster in der Main-Region eines Cloud-Providers heruntergefahren wird.
Anhand von diesen 4 Kategorien kann man für ein Zielsystem Experimente formulieren, die genau diese Situationen im Realfall zu nachstellen versuchen, um die Unbekannten Variablen ins Bekannte zu rücken. Somit ist bei der Formulierung von Experimenten immer hilfreich diese Unterscheidung im Hinterkopf zu haben.
4 Experimente zum Beginnen
In einem Beitrag von Matt Jacobs, einem Software Engineer bei Gremlin, erläutert er mit welchen Experimenten, bei Gremlin auch Recipes genannt, man am besten die ersten Versuche von Chaos Engineering am eigenen Cluster vornehmen sollte. Diese läutern wir hier kurz auf um die Formulieren von sinnvollen Experimenten zu versinnbildlichen:
Experiment 1: Resourcen-Erschöpfung
Resourcen auf Computersystemen sind endlich. Ein Container in einem Cluster hat auch nur begrenzte Resourcen zur Verfügung, somit ist die containerisierte Applikationen verpflichtet der ihr zur Verfügung gestellten Resourcen zu nutzen. Die Idee des Experiments ist dabei die CPU-Zyklen zu blockieren und die Applikation mit normaler Customer-facing Last laufen zu lassen.
-
Attack: CPU / Arbeitsspeicher / Speichermedium
-
Scope: Einzelne Instanz
-
Erwartetes Verhalten: Response-Rate geht zurück, Fehler vermehren sich auf allen Ebenen, Brownout-Modus betreten (falls implementiert), Alerts gefeuert (falls konfiguriert), Load-Balancer leitet den Traffic anderweitig weiter (falls anwendbar)
Experiment 2: Unzuverlässiges Netzwerk
Verbindungen zu anderen Services im Verbund über ein Netzwerk ist Alltag bei verteilten Systemen. Netzwerke sind im realen Betrieb oft unzuverlässig. Genau dieser Fehlerfall darf nicht unterschätzt werden. Wenn für eine Applikationen eine Abhängigkeit ausfällt, so ist genau zu Ermitteln was die Folge davon sein kann. Die Unverfügbarkeit von Netwerk-Punkten (Services) wird auch Network Blackhole genannt.
-
Attack: Network Blackhole / Latenz
-
Scope: Einzelne Instanz
-
Erwartetes Verhalten: Traffic zur Abhängigkeit geht auf 0 herab (oder wird langsamer), Applikatorische Metriken bleiben im Steady-State unberührt, Startup erfolgt ohne Fehler, Traffic zum Fallback-Systemen läuft und wird als erfolgreich gemeldet
Experiment 3: Speichersättigung
Viele relevante Applikationen in einem System bedienen sich mindestens einer Art von Speicher, oft aber auch mehrere. Die Rede ist hier von Datenbanken, File-Systemen, und weiteren Typen von Datastores. Das Management zwischen Speichermedium und Applikation ist für die Healthiness der Gesamtapplikation von grösster Relevanz. Es gibt unterschiedliche Weisen wie man das am besten beanspruchen kann. Etwa über eine Unverfügbarkeit (Network Blackhole) des Speichermediums, oder reduzierter Latenz zum Speicherzielort oder dessen I/O-Bandbreite.
-
Attack: Network Blackhole / Latenz / IO
-
Scope: Einzelne Instanz
-
Erwartetes Verhalten: Traffic zum Datastore ist langsamer und/oder unnerreichbarer, Timeouts und Concurrency-Limits schalten ein, Alerts und Pages feuern
Experiment 4: DNS-Nichtverfügbarkeit
Die DNS ist bei Netzwerk-orientierten Systemen auch eine sehr wichtige Komponente. Im Oktober 2016 kam es weltweit zu einem grossen DNS-Ausfall. Wenn auch selten und somit weniger risikoreich, so kann ein DNS-Ausfall sehr kostenintensiv sein. In unserem 4. Recipe möchte man ein DNS Blackhole, d.h. den Ausfall des DNS, erzeugen und schauen wie man ein Backup über direkte IP-Adressen einsetzen könnte. Weiterführend kann man hier auch interne Service Discovery-Komponenten (etcd, Eureka, Consul, usw.) ausschalten und schauen wie sich das Gesamtsystem verhält.
-
Attack: DNS Blackhole
-
Scope: Einzelne Instanz
-
Erwartetes Verhalten: Eintreffender Traffic wird gedropped, Traffic zu externen Systemen schlägt fehl, Startup erfolgt nicht erfolgreich
Diese 4 Recipes sind sicherlich gute Einstiegspunkte in das reale Chaos Engineering und lassen sich gut für weiterführende Experimente anpassen. Wichtig sei hier auch angemerkt, dass Wie ein Recipe hier definiert wurde, nämlich mit einer Defintion des Art des Angriffs (Attack), des Angriffumfangs (Scope) sowie das erwartete Verhalten (auch Expected Results). Es lohnt sich die Recipes so SMART wie möglich zu definieren und die Resultate genau so akribisch festzuhalten.
So jetzt haben wir genug Theorie über das Chaos Engineering gehabt. Lassen Sie uns zusammen Tools anschauen, womit man am besten Chaos Engineering als Prozess in Ihrem Betrieb betreiben kann! Hierzu schauen wir uns 3 Software-Projekte an, womit man Chaos Engineering nutzen kann: chaoskube, Chaos Mesh und Gremlin.
Pod-Ausfälle mit chaoskube
chaoskube ist eine kleines, einfaches Open-Source Projekt womit man sehr einfach für Pod-Ausfälle sorgen kann. chaoskube ist ein CNCF Sandbox Project und ist in Go geschrieben.
Features
-
Killt in einer definierten Periodizität zufällig einen Pod im Kubernetes-Cluster
-
Erlaubt Filter nach Namespaces, Kinds, Labels, Pod-namen, Annotations, usw.
-
Helm-Chart
Installation und Konfiguration
Für chaoskube gibt es ein Helm-Chart stable/chaoskube welches man ganz einfach im Ihrem Cluster wie folgt installieren kann:
|
|
Recipes
chaoskube wird direkt über dessen Deployment-Manifest konfiguriert. Dies kann zum Beispiel wie in der example-Repo von linki/chaoskube/examples wie folgt aussehen:
|
|
Recipes ausführen
Da das Recipe von chaoskube nur das Ausschalten von Pods erlaubt und dessen Konfiguration direkt über das Manifest auf den eingespielt wird, kann man das Recipe auch nur für diesen Fall laufen lassen.
In der obigen Deployment.yaml erkennt über die Konfiguration von chaoskubbe (args:) dass alle 10 Minuten ein Pod in einer Environment mit Wert test, mit der Annotationchaos.alpha.kubernetes.io/enabled=truenur unter der Woche und weiteren Bedingungen erfolgt. Somit kann man relativ einfach ein einfachen Chaos Engineering-Prozess einführen und eine ‘We Celebrate Failure’-Kultur betreiben.
Noch mehr Failures auf Kubernetes mit Chaos Mesh
Chaos Mesh ist wie chaoskube, kann aber eine Vielzahl von Chaos-Recipes ausführen. Chaos Mesh ist genau wie chaoskube auch ein CNCF Sandbox Project und ist auch in Go geschrieben.
Features
-
Liefert vordefinierte, anpassbare Chaos-Experimente aus
-
Erlaubt somit eine Vielfalt von verschiedenen Recipes (Pod, Network, IO, DNS, AWS, usw.)
-
Erlaubt Selektion nach Namespace, Label, Annotation, Field und Pod
-
Nutzt CRDs für die Operator-Definition der Chaos-Experimente
-
Helm-Chart
-
Liefert ein Chaos-Dashboard mit
Installation und Konfiguration
Chaos Mesh kann man ganz gemütlich über Helm installieren. Dazu fügt man zuerst die Helm-Repository von Chaos Mesh hinzu:
|
|
Danach man die Installation wie folgt vornehmen (ersetzte dabei <NAMESPACE> mit einem geeigneten Namen wie chaos-testing):
|
|
Prüfe danach ob die Pods von Chaos Mesh laufen:
|
|
Recipes
Chaos Mesh bietet folgende Recipe-Vorlagen. Diese werden bei Chaos Mesh auch Chaos-Experimente genannt:
-
PodChaos: Erlaubt den
pod-failure,pod-killsowie dencontainer-killvon Pods. -
NetworkChaos: Erlaubt die Network Partition (Zweiteilung in unabhängige Subnets) und die Network Emulation (Netem) Chaos des Clusters. Das letztere ermöglicht es Delays, Duplucation, Losses und Corruption von Verbindungen zu erzeugen.
-
StressChaos: Erlaubt es Stress/Belastung durch CPU-Auslastung auf einem Set von Pods zu erzeugen.
-
TimeChaos: Erlaubt es den Wert von
clock_gettimezu ändern, was wiederum ein Offset von Go’stime.Now()oder Rust’sstd::time::Instant::now()und weiteren Zeit-Definitionen erzeugt. -
IOChaos: Erlaubt es File-System-Fehler wie IO-Delays oder Read/Write-Errors zu erzeugen.
-
KernelChaos: Damit kann man die Performance von Pods durch KernelPanics beeinflussen. Es ist davon abgeraten dies auf Produktion zu tun, da es zu Side-Effekten und/oder Folgereaktionen kommen kann.
-
DNSChaos: Erlaubt es fehlerhafte DNS-Responses zu verschicken oder das Resolven von willkürlichen IP-Adressen zu forcieren.
-
AwsChaos: Erlaubt es EC2-Instanzen zu stoppen (
ec2-stop), zu restarten (ec2-restart) und Volumes zu entfernen (detach-volume).
Beispiel eines Pod Kill-Recipes
Um einen Pod Kill als Experiment mit Chaos Mesh ausführen zu lassen müssen wir den PodChaos-Operator nutzen und ein Manifest schreiben das wie folgt aussehen könnte:
|
|
Wie im obigen Manifest ersichtlich wird hier ein PodChaos-Operator definiert, welcher über den scheduler einen cron-Expression von @every 1m hat. Dabei wird über den selector definiert was davon betroffen sein kann, namespaces und labelSelectors.
Mit Chaos Mesh kann man somit relativ einfach unterschiedliche Recipes definieren und auf dem Zielcluster ausführen lassen. Chaos Mesh eignet sich gerade dann wenn man mehr als nur Pod Kills erzeugen möchte.
Gremlin – Chaos-As-a-Service
Gremlin ist eine Enterprise-fähige Chaos Engineering Platform und somit der Platzhirsch auf dem Affenthron. Gremlin ist ein CNCF Sandbox Project und Closed-Source. Gremlin basiert auf Chaos Monkey und ist eine Weiterführung davon.
Chaos Monkey war in 2010 von Netflix designte Custom Resiliency Tool, das wegweisend Chaos Engineering definiert gehabt hatte. Als Netflix 2010 auf den Cloud-Provider Amazon Web Services umgestiegen war, war es den Site Reliability Engineers (kurz SRE) wichtig die Verfügbarkeit der Netflix-Streams als ihr Markenzeichen zu gewährleisten können. Das Tool entwickelte sich dabei zu einer Zweitversion, genannt Simian Army. Damit wurde Chaos Engineering noch weiter ausgebaut und ausgreift und umfasste Leute aus dem DevOps-, Engineering- und SRE-Bereich. Bis heute lebt Chaos Monkey und dessen Weiterführung als Simian Army in Gremlin weiter und wurde somit der Marktführer.
Installation und Konfiguration
Machen Sie sich zuerst einen Account auf Gremlin. Gremlin kann man auch per Helm auf Ihrem Cluster wie folgt installieren. Dazu fügen wir zuerst die Helm-Repo gremlin wie folgt hinzu:
|
|
Danach installieren wir die Gremlin Helm-Chart. Hier verwende ich den Namespace-Namen gremlin. Ergänzen Sie dazu die Secrets (clusterId und teamSecret):
|
|
Loggen Sie sich im Anschluss in ihrem Gremlin-Dashboard ein. Das Dashboard sieht wie folgt aus:
Fazit – Wie man den Cluster-Betrieb resilient macht
Heute haben wir angeschaut wie man eine ‘We Celebrate Failure’-Kultur mit Chaos Engineering einführen kann. Chaos Engineering macht Ihren Betrieb resilienter und im Besten Fall antifragil. Es gibt unterschiedliche Tools, chaoskube, Chaos Mesh oder gar Gremlin, wie man Chaos Engineering betreiben kann, aber alle Tools haben das gleiche Vorgehen: Man beschreibt ein Experiment, stellt Vermutungen an, führt das Experiment aus und zeichnet mit wie sich der Cluster tatsächlich verhält. Hat man die Fehlerquellen identifiziert, fixt man die den Fehler um so das Gesamtsystem für den nächsten Ausfall vorzubereiten und gewinnt somit an Resilienz. Gerade im Cloud-Betrieb darf man den Nutzen von gezieltem Chaos Engineering und weiterführendem Site Reliability Engineering nicht unterschätzen.
Falls Sie noch mehr zu Chaos Engineering, Resilienz im Cloud-Betrieb und Failure-Kultur im DevOps erfahren möchten, so melden Sie sich direkt bei uns! Wir bei b-nova sind stets daran interessiert Wissen und Erfahrung für uns und somit Mehrwert für ihren Betrieb zu schaffen. Stay tuned!
Weiterführende Ressourcen und Quellen
https://principlesofchaos.org/
https://www.gremlin.com/community/tutorials/chaos-engineering-the-history-principles-and-practice/
https://www.gremlin.com/state-of-chaos-engineering/2021/?ref=footer
https://www.gremlin.com/roi/?ref=footer
https://github.com/dastergon/awesome-chaos-engineering