Die Schnittstelle ist Alles
Schnittstellen sind mitunter eines der wichtigsten Aspekte bei der Entwicklung von Software-Systemen. Klassisch wird über eine REST-Schnittstelle Daten eines Services an zweite exponiert. In einem von uns kürzlich erschienenen Beitrag hatten wir uns angeschaut wie man eine Schnittstelle mit gRPC implementieren kann. Dabei setzt gRPC auf die Variante von einer Remote Procedure Call wobei die Schnittstelle mit Protobuf vordefiniert wurde und somit typisiert Funktionsaufrufe auf Zielsystemen ermöglicht. Dies bringt gewisse Vorteile gegenüber einer REST-Schnittstelle, da die Schnittstelle explizit deklariert wurde und die Art und Weise wie ein Funktionsaufruf gemacht wird im Verhältnis schneller ist.
Wenn nicht REST oder gRPC, dann GraphQL!
Es gibt eine weitere Art wie man Daten eines Services alternativ exponieren kann; nämlich als Suchanfrage, zu Englisch als Query Language. Die Idee dabei ist, dass die Suchanfrage, oder auch Query genannt, sich identisch wie eine Query an eine Datenbank oder an eine Suchmaschine wie Apache Solr verhält. Die Suchanfrage beinhaltet nur die Suchbegriffe, die auch für den jeweiligen Fall benötigt werden. Eines der Vorraussetzungen an das Zielsystem ist dass dieses bereits alle möglichen Suchbegriffe kennt und bereitstellt. Genau dies macht GraphQL – die Query Language für Ihre zukünftige such-fähige API.
Wie bitte nochmal?
GraphQL beschreibt den Aufbau der Schnittstelle in folgenden Schritten:
- Beschreibe deine Daten
|
|
Hier ein Datentyp Project mit 3 Einträgen, das letzere ein Array von Typ User. Die Gesamtheit aller definierten Datentypen wird Schema genannt und wird später nochmals erklärt.
- Suche nach dem was du haben möchtest
|
|
Das ist eine Query. Sie sucht nach der Tagline innerhalb des Typs project mit eindeutigen Namen “GraphQL”.
- Erhalte verständliche Suchresultate
|
|
Das Suchergebniss ist genau wie Query strukturiert und enthält hier einen vorhandene Tagline.
Das ist die einfachste und schnellste Beschreibung wie sich eine GraphQL-Schnittstelle verhalten soll.
Vorteile einer GraphQL-Schnittstelle
Also, Software-System erfordern Datenaustausch der einzelnen Systemkomponenten. Service A holt sich von Service B gewisse Daten. Oft werden in der Business-Logik nicht immer alle Daten die von Service B exponiert werden auch tatsächlich gebraucht. Somit ist das Aufbereiten und Exponieren von vorgefertigten Datenstrukturen –wie typischerweise bei einer REST-Schnittstelle– nicht immer effizient. Klar, man kann dem REST-Endpunkt eine gewisse Anzahl Parametern mitgeben um sodass gewünschte Resultat zu bekommen, aber man ist sehr eingeschränkt und unflexibel.
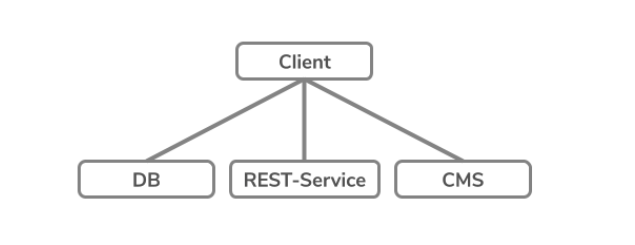
GraphQL bietet einen Zwischenschritt in Form eines GraphQL-Server, der alle Datenquellen aggregiert und diese dem Client bereitstellt.
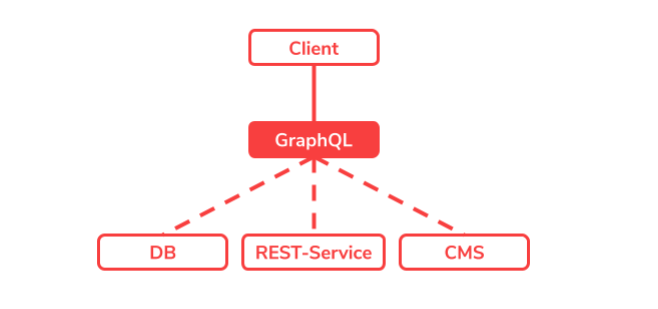
Typisierter Graph mit dem GraphQL-Schema
Das Hauptstück einer GraphQL-Implementation ist das GraphQL-Schema, ab hier einfach nur Schema genannt. Das Schema ist die Domain-Definition aller Felder die in dem Graph verbunden sind. Bei jeder GraphQL-Schnittstelle gibt es ein Schema, welches bereits im voraus definiert was alles vorhanden ist und somit bestimmt wonach man suchen kann.
Das Schema kann zum Beispiel für eine Blogpost-Schnittstelle wie folgt aussehen:
|
|
Wir sehen bereits, dass es unterschiedliche Typendefintionen gibt:
-
Query
Dertype Querybezeichnet ein aufrufbare, vorgefertige Query. In diesem Fall kann man alle Blogposts mitgetAllBlogs()oder einen einzelnen Blogpost mitgetBlogPost()anzeigen lassen wobei man mit einen id-Parameter den eindeutigen Identifiert mitgeben kann.Merke: das Bang
!beudeutet dass dieser Wert vorhanden sein muss. -
Mutation
Dertype Mutationbezeichnet eine aufrufbare, vorgefertigte Funktion, die Werte in der Schnittstelle modifizieren kann. Im Beispiel kann man überaddBlogPost()einen neuen Blogpost anlegen. Dabei muss zwingend der Parameter Titeltitle, den Inhaltcontentund den eindeutigen Autoren-IdentifierauthorIDmitgegeben werden. -
Objekt
Ein Objekt ist jedes strukturierter Typ innerhalb des Graphs. In obigen Beispiel mit der Blog-Schnittstelle wird ein ObjektBlogPostmit den Feldern id, title, content und hasAuthor und ein zweites ObjektAuthormit den Feldern id, name und hasBlog definiert. Diese kann man auch ohne eine vorgefertigte Query-Funktion parsen und auswerten. -
Skalar
Ein Skalar-Typ ist jegliches Feld innerhalb eines strukturierten Objektes. In diesem Falle kann isttitleundcontentbeispielsweise ein Skalar-Feld mit TypStringwelches nicht null sein darf. Ein Skalar-Feld kann auch ein Array von einzelnen Skalar-Werten.Merke: Die Grundtypen sind für GraphQL
Int(32-bit),Float(UTF-8),String,Boolean, und dieID(wie String serialisiert).
Zur Vollständigkeit sei angemerkt, dass es noch weitere Typen gibt. Darunter gehören Enums, Listen, Union, Interfaces, un Input Types. Diese können Sie in der offiziellen Dokumentation zum Schema und Typen nachschauen.
Underfetching und Overfetching
Ein zweiter gewichtiger Vorteil von GraphQL ist das adequate Auflösen der eigentlich geforderten Daten. Es wird nicht zu viel, genannt Overfetching, aber auch nicht zu wenig, genannt Underfetching, geliefert. Somit ist die Schnittstellen effizient und, falls richtig implementiert, stets performanter.
-
Underfetching ist wenn man nicht alle Daten in einer Response geliefert werden. Oft werden nicht alle Resources ausgegeben und nur Referenzen zu weiteren Resources angeben was weitere Requests erfordert.
Eine REST-API könne beispielsweise CMS-Daten bereitstellen. Dabei würde beim Aufruf des API-Endpunkt
/cms/getAllBlogPosts?published=yesnicht alle gewünschten Werte, sondern Referenzen die weitere REST-Aufrufe erfordern würden, der BlogPosts als Response zurückkommen. -
Overfetching ist wenn mehr als die gewollten Daten in einer Response geliefert werden. Das ist das genaue Gegenteil von Underfetching. Das heisst, dass bei einem Aufruf einer REST-API zuviele Werte in der Response stehen als gewünscht und somit die Schnittstelle nicht so effizient wäre.
Ein kurzes Wort zu Caching
Natürlich stellt sich schnell die Frage ob GraphQL auch das Caching von Abfragen übernehmen kann. Der GraphQL-Server, welcher die Datensätze aggregiert speichert nicht diese aber nicht. Deswegen ist Client-seitiges Caching oder gar Server-seitiges Caching separat zu implementieren und zu berücksichtigen.
Mit GraphiQL ein paar Queries testen
GraphiQL ist die offizielle Referenz-Implementation einer GraphQL-IDE. Damit kann man Queries schreiben, testen und analysieren. Die IDE kann man somit für die eigene Schnittstelle zur Verfügung stellen um eine graphische Oberfläche zu bieten.
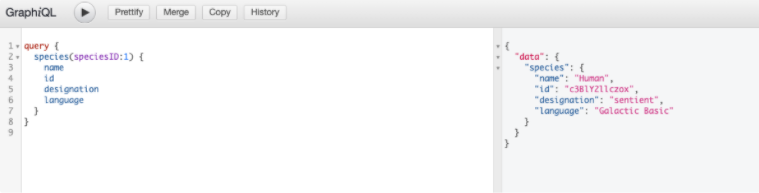
Wie man oben sehr schön sehen kann, gibt es auch eine Live-Demo davon, womit man sehr gut die ersten Schritte mit GraphQL wagen kann. Mit GraphiQL lassen sich alle möglichen Queries testen und man kann auch das Schema komplett darstellen. Das Schema lässt sich in Fenster rechts betrachten. Das sieht hier etwa so aus:
Versuchshalber habe ich folgende Query geschrieben, welche für die Spezies mit speciesID:1 dessen Namen name, dessen Identifier id, dessen Bezeichnung designation und dessen Sprache language als Resultat ausgeben soll.
|
|
Die Query, falls korrekt ausgeführt, liefert folgendes eher spassiges Ergebnis:
|
|
Die Spezies mit Name “Human”, Identifier “c3BlY2llczox“, Bezeichnung “sentient“ und Sprache “Galactic Basic“ ist das Resultat selbsterklärend. Man bekommt somit immer genau die Daten, die man initial über die Query auch bekommen will, nicht mehr und nicht weniger.
GraphQL ist nur eine Spezifikation
Implementieren müssen Sie GraphQL immer noch selber. Zum Glück gibt es bereits etablierte Libraries, die man nutzen kann, aber grundsätzlich muss die Schnittstelle immer noch selber geschrieben werden.
Das White Paper der Spezifikation ist auf der offiziellen Webseite abrufbar und beinhaltet die komplette Definition was eine vollwertige GraphQL-Implementation aufweisen muss. Der erste Paragraph der Einleitung liest sich wie folgt:
– “GraphQL is a query language designed to build client applications by providing an intuitive and flexible syntax and system for describing their data requirements and interactions.”
Implementierung einer GraphQL-Schnittstelle
Query-Resolvers schreiben
Ein Resolver ist ein Code-Baustein, dass die Werte für ein GraphQL-Objekt auflöst. In Java ist ein Resolver eine Java-Klasse, die von einer GraphQL-Resolver-Klasse erbt und die gewünschten Objekte über die Daten-Anbindungen (Connectors) zusammenbaut.
Die Schema-Definition
Nehmen wir ein Schema, dass über eine GraphQL-Schnittstelle Blog-Posts exponieren soll. Das Schema würde ein Objekt BlogPost mit mindestens einem Titel und ein Feld für den Content beinhalten. Dabei wollen wir über eine Query alle Blog-Posts aggregiert bekommen. Das könnte dann etwa so aussehen:
|
|
So, das GraphQL-Schema und somit die Domain-Definition haben wir. Jetzt wollen wir unseren Java-basierten GraphQL-Server mit Resolvern versehen, um diese Daten alle zu aggregieren. Zuerst müssen wir das Objekt BlogPost in Java nachbilden. Am besten machen wir eine POJO-Klasse mit dem gleichen Namen und Feldern:
|
|
Jetzt müssen wir eine Aggregationsklasse bauen, welche alle BlogPosts zur Verfügung stellt. Diese Klasse ist notwendig, da wir für das Beispiel keine Datenbank-Anbindung verwenden werden und nur exemplarisch die Daten bereitstellen. Nennen wir die BlogPostRepository. Sie verwaltet alle BlogPosts und kann diese über eine entsprechende Methode getAllBlogPosts() ausgeben und fügt neue BlogPosts über eine Methode addNewBlogPost() hinzu.
|
|
Jetzt haben wir sozusagen unsere Daten, sowie dessen Anbindung gemocked. Der nächste Schritt ist der Resolver für die BlogPosts. Dieser implementiert hier GraphQLRootResolver (graphql-java) und trägt den Klassennamen des aufzulösenden Objektes BlogPostResolver. Diese Klasse implementiert unsere getAllBlogPost()-Query.
|
|
Jetzt können wir diesen Resolver in unserer Schnittstelle einbinden. Dazu bauen wir ein Servlet, welches die SimpleGraphQLServlet-Klasse implementiert. Der angestrebte Endpunkt ist /graphql. Wir müssen uns ein Objekt von Typ GraphQLSchema erstellen welches über das Schema-File verfügt, sowie die entsprechenden Resolvern, hier der BlogPostResolver, kennt. Das sieht wie folgt aus:
|
|
Datasources anbinden
Normalerweise möchte man mehrere Datenquellen, sogenannte Datasources anbinden. Dazu muss man für jede Datenquelle einen entsprechenden Connector schreiben. Der Connector übergibt dann dem jeweiligen Resolver die nötigen Werte. Die Werte ist über die Domain-Definition vom Schema der GraphQL-Schnittstelle bereits im voraus bekannt.
Fertige Implementationen und Tools
GraphQL wurde ursprünglich von Facebook entwickelt. Die Entstehungsgeschichte kann in einem aufschlussreichen 30-Minütigen Dokumentarfilm bestaunt werden. Die Quintessenz ist die, dass durch das komplexen Requirements der bekannten Facebook-Wall einer flexibleren und effizienteren Schnittstelle zu den eigentlichen Daten erforderlich war und dadurch intern an einer Lösung, heute bekannt als GraphQL, gearbeitet wurde. 2015 wurde die Implementation Open-Source gemacht und die Weiterentwicklung in eine eigene GraphQL Foundation verlagert. Es gibt wie für die Cloud Native Foundation auch für die GraphQL Foundation eine Landscape.
Da GraphQL eigentlich nur ein White Paper, eine Spezifikation ist, gibt es zahlreiche Implementationen. Mit der Zeit haben sich gewisse Libraries und Implementation bewährt. Hier eine kleine Auflistung des Ökosystems rund um GraphQL:
GraphQL Ökosystem
-
Apollo ist die die Referenzimplementation einer GraphQL-Plattform
Webseite: apollographql.com/
Git-Repo: github.com/apollographql -
Java-Libraries gibt es für Spring Boot, Quarkus und weitere JVM-Frameworks
Quarkus: quarkus.io/guides/smallrye-graphql
Spring Boot: github.com/graphql-java/graphql-java -
Go-Libraries gibt es auch mehr als eine
graphql-go: github.com/graphql-go/graphql
Es gibt noch viel mehr über GraphQL zu schreiben, aber hier haben wir die Grundlagen erläutert wie man GraphQL nutzen kann und wie man damit die adäquate Schnittstelle für ihr nächstes Projekt konzipieren kann.
Stay tuned!
Weiterführende Links und Ressourcen
So what’s this GraphQL thing I keep hearing about? | freeCodeCamp
GraphQL concepts I wish someone explained to me a year ago | Naresh Bhatia @ Medium
GraphQL Explained in 100 Seconds | Fireship