Prometheus ist ein Event Monitoring und Alerting Anwendung für Cloud-Infrastrukturen. Das Projekt ist in Go geschrieben und zählt zu den Graduated Projects in der Cloud Native Computing Foundation. Es gilt als das de-facto Monitoring in der Cloud.
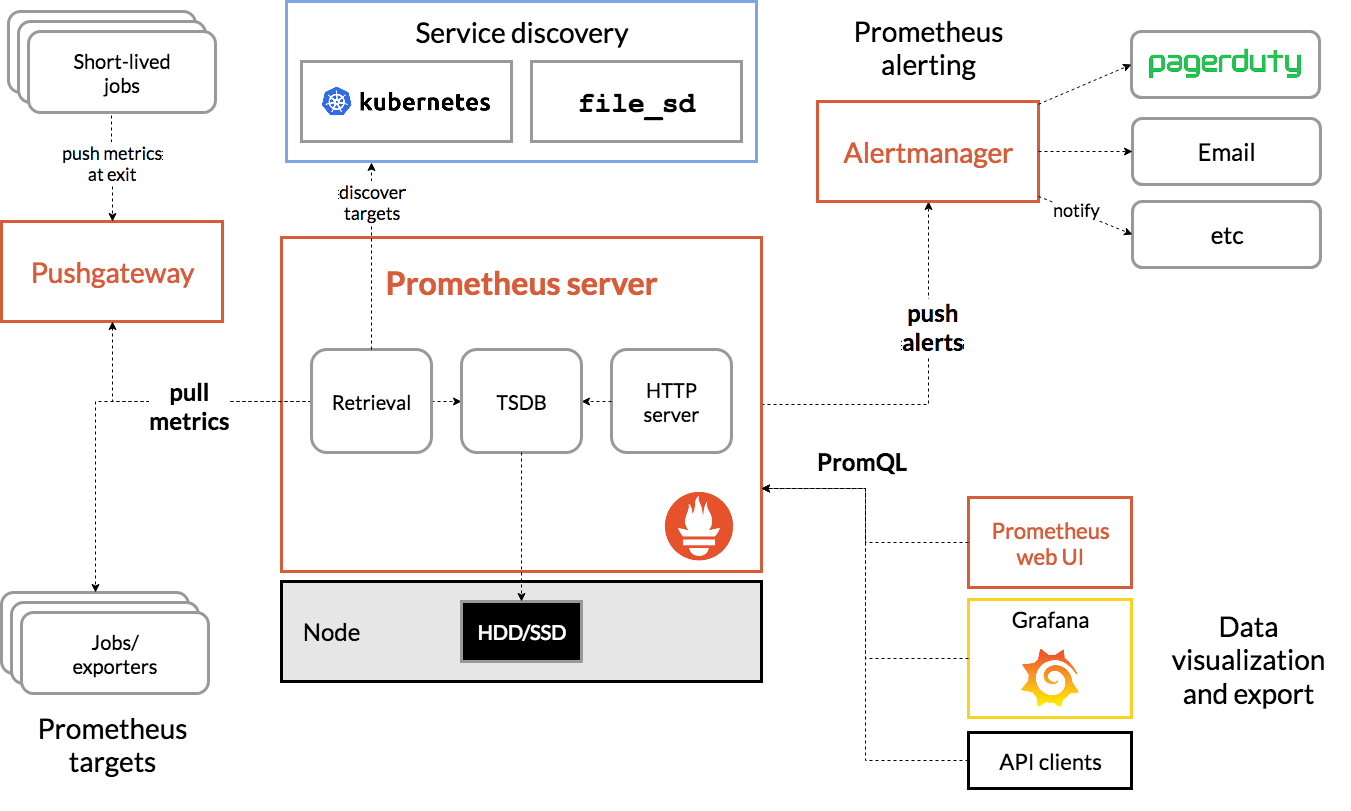
Die Idee bei Prometheus ist, dass eine zentrale Node Metriken und Alerting-Informationen aggregiert. Dabei werden die Metriken per HTTP-Pulling von einer im Vorfeld deklarierten Anzahl Nodes gezogen. Diese Nodes, auch Targets genannt, exponiert diese Informationen. Der Prometheus Server aggregiert diese in einer Zeitreihen-Datenbank, triggert wenn vorhanden push alerts, und kann die Daten zur Weiterverarbeitung durch Data visualization tools wie Grafana exposen.
Architektur in Kürze
Prometheus lokal ausprobieren
Dank seiner minimalistischen Architektur und seiner unkomplizierten Installation lässt sich Prometheus einfach ausprobieren.
Prometheus Server starten
Laden Sie die letzte Version von Prometheus herunter.
Beispielsweise in der Version 2.22.2 direkt über das Terminal wie hier gezeigt:
|
|
Entpacken Sie nun das Archiv, switchen Sie in das entpackte Verzeichnis und starten Sie Prometheus per
prometheus-Binary:
|
|
Nun kann der Prometheus Server über localhost:9090 aufgerufen werden. Dieser redirectet gleich auf eine
UI-Oberfläche unter /graph. Ein weiterer Endpunkt der alle aggregierten Metrics exponiert ist unter /metrics
einsehbar. Das UI sieht so aus:
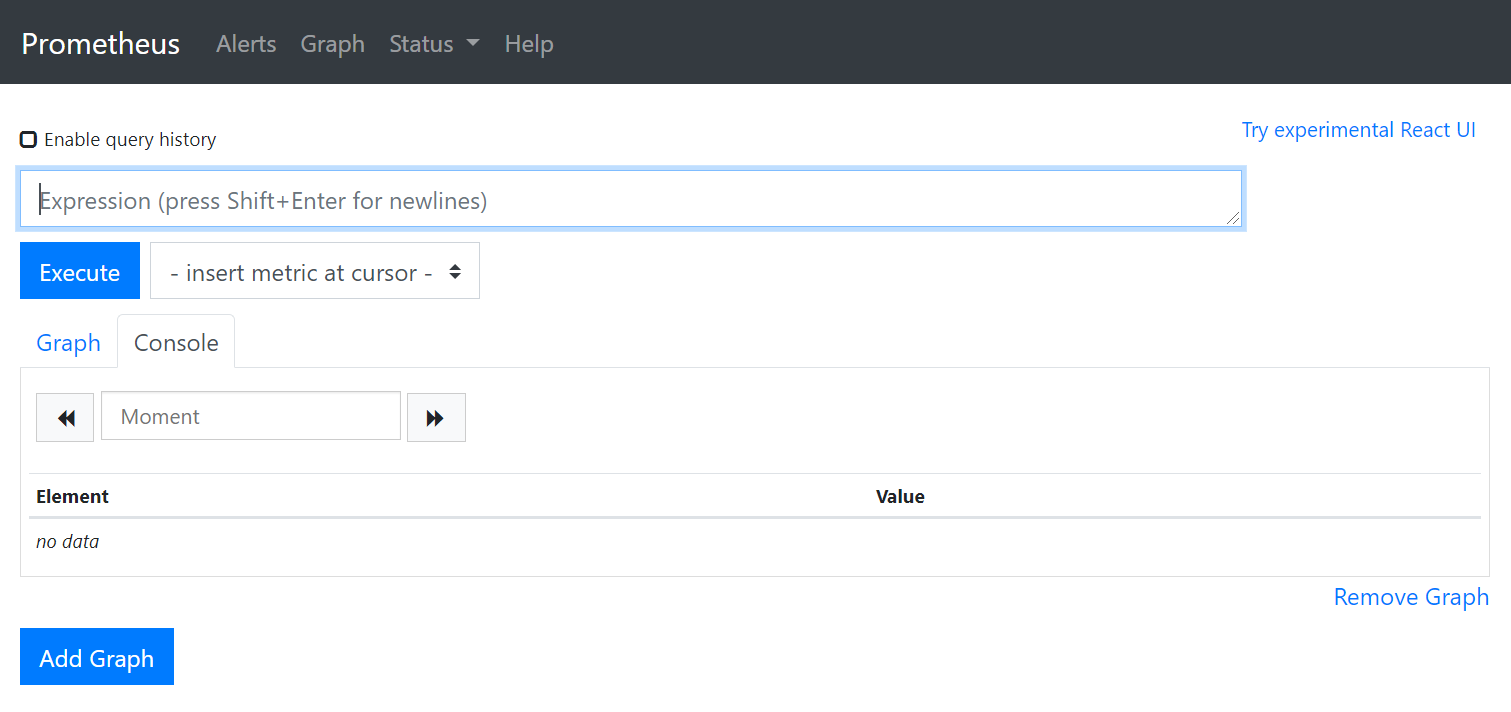
In der UI kann man mit der hauseigenen Query-Language PromQL Abfragen ausführen. Zurzeit werden bis auf die Server eigenen
Metriken keine anderen aggregiert. Um die PromQL zu testen, können Sie eine sum(prometheus_http_requests_total) -Query laufen lassen die uns die Anzahl von HTTP-Aufrufe summiert.
Herzstück der Konfiguration von Prometheus ist die prometheus.yml die sich im extrahierten Verzeichnis befindet.
Per Default sieht diese wie folgt aus:
|
|
Darin erkennt man, dass Prometheus alle 15 Sekunden das Scraping auslöst, was wiederum alle Metriken aller Targets
zieht (pull). Targets sind die Zielsysteme woraus die Metriken aggregiert werden. Nun, wir haben noch keine Targets
die gescraped werden, da wir erst noch welche exponieren müssen. Dies können Sie erreichen, in dem Sie auf den
Zielsystemen einen sogenannten node_exporter laufen lassen.
Targets exponieren
Da wir Prometheus lokal ausprobieren, werden wir das Target auf dem gleichen Rechner laufen lassen worauf auch der Prometheus Server läuft.
Laden Sie die letzte Version vom node_exporer herunter. Hier
noch in der Version 1.0.1:
|
|
Genau gleich wie vorhin, entpacken Sie das Archiv, switchen Sie in das Verzeichnis und lassen Sie den
node_exporter wie folgt laufen:
|
|
Sobald dieser läuft, können die Metriken unter localhost:9100/metrics eingesehen werden.
|
|
Der Output des obigen curl sollte in etwa sowas ausgeben:
|
|
Dieser exponiert per Default in dieser Form lediglich Maschinenmetriken. Um weitere Informationen auf Prozess-
oder Applikationsebene zu exponieren müssen diese dem node_exporter explizit gegeben werden.
Jetzt müssen Sie noch dem Prometheus Server sagen, dass er diese Node pullen kann. Hierzu muss die oben exponierte
Node dem prometheus.yml hinzugefügt werden:
|
|
Nach jedem Pull aggregiert nun der Prometheus Server die Metriken die über die Node hineinkommen.
Next Steps
Der nächste Schritt wären, wie man Grafana mit Monitoring aus Prometheus visuell darstellen kann. Das folgt im nächsten Blog-Beitrag dazu.
Weiterführende Links:
Prometheus | GitHub Prometheus | Cloud Computin 2020 Exercises Prometheus in Kubernetes | CoreOS Blog