
Das Jahr 2022 steht für mich persönlich ganz im Zeichen von Distributed Systems, zu Deutsch verteilte Systeme. Aus diesem Grund befasse ich mich in einer neuen TechUp-Serie mit verteilten Systemen im Allgemeinen, wie auch deren Konzipierung mit Elixir und dessen Ökosystem. Zuerst legen wir den Fokus auf Elixir, um Grundkonzepte von verteilten Systemen praktisch mit einer Programmiersprache dingfest zu machen. Danach werden wir uns theoretische Konzepte sowie weiterführende Themen rund um verteilte Systeme anschauen. Dies wird in die folgenden zwei TechUp-Serien aufgeteilt:
- Elixir Series
- Distributed System Series
Dies ist Teil 2 der Elixir-Series. Falls du nicht schon von dort kommst, empfehle ich dir unbedingt erst Teil 1 zu lesen, wo wir den Fokus auf Elixir gelegt haben, um Grundkonzepte von verteilten Systemen praktisch mit einer Programmiersprache dingfest zu machen. Nun werden wir uns die theoretischen Konzepte sowie weiterführende Themen rund um verteilte Systeme anschauen und Elixir anhand eines Kartenspiel-Projekts in Aktion sehen. Viel spass!
Elixir und sein Debüt
Elixir ist genau wie Erlang eine Programmiersprache welche auf der BEAM läuft. Elixir ist sozusagen Erlang für das 20. Jahrhundert und wurde durch José Valim im Jahr 2014 im Rahmen der brasilianischen Firma Plataformatec konzipiert und entwickelt. Die ursprüngliche Idee hinter Elixir war, die BEAM-Plattform zugänglicher zu machen, indem man eine Sprache entwickelt, welche leicht erweiterbar und mit der man schnell produktiv ist. Zudem sollte die Sprache mit dem Erlang-Rucksack geeignet sein, um robuste large-scale Webapplikationen bauen zu können.
Ein Hello World in Elixir ist das einfachste und kann direkt in der REPL geschrieben werden:
|
|
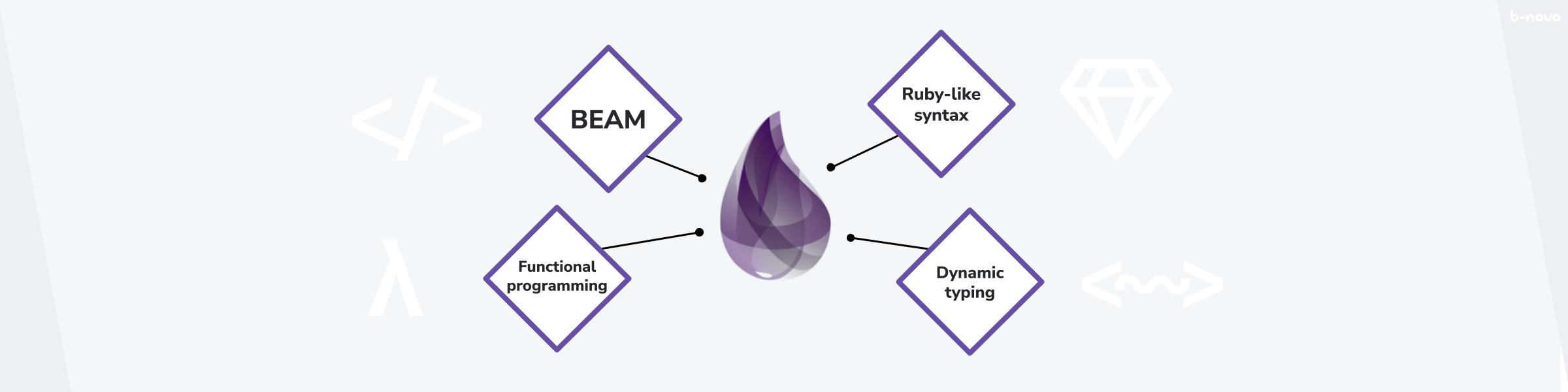
Elixir zeichnet sich in erster Stelle durch folgende 4 Kerneigenschaften aus:
-
Functional programming: Elixir ist genau wie Erlang eine funktionale Sprache. Was das heisst wird hier gleich im Anschluss erläutert.
-
BEAM: Die BEAM basiert auf dem Actor-Model, welches wir im weiteren Verlauf genauer anschauen werden.
-
Ruby-like Syntax: Elixir setzt auf zeitgenössischen Syntax und orientiert sich dazu an Ruby und seine Leserlichkeit.
-
Dynamische Typisierung: Elixir weist eine strenge aber dynamische Typisierung auf.
Jetzt werden wir die verschiedenen Punkte, welche an Elixir ein wenig exotisch wirken könnten abarbeiten, dabei erklären, worum es überhaupt geht, und schlussendlich verdeutlichen, dass Elixir keine Raketenwissenschaft ist und mit ein wenig Zeit und Geduld einfach erlernbar ist.
Das Funktionale Paradigma
Funktionales Programmieren ist definitiv kein Fremdwort in der Programmierwelt, dennoch ist es für viele noch unerschlossenes Terrain. Im Rahmen dieses TechUp’s möchte ich diesen Aspekt etwas besser durchleuchten und die Prinzipien des funktionalen Programmierparadigmas aufzeigen. Das funktionale Paradigma ist so grundlegend anders, dass zuerst die konventionelle Art und Weise der Programmierung betrachtet werden muss. Konventionelles Programmieren geht vom Modell der Von-Neumann-Architektur aus, welche den Computer, den Rechner, in den Vordergrund stellt und die Einspeisung einer Sequenz von Instruktionen an die Recheneinheit, der CPU, über eine Input-Eingabe vornimmt.
Die Progammiersprache C verkörpert dieses Prinzip der Abarbeitung von sequenziellen Instruktionen, was auch als prozedurales oder imperatives Paradigma bekannt ist. Die Mehrheit aller Objektorientierten Sprachen bauen auf dem prozeduralen Paradigma auf und erweitern diese sequenzielle Abarbeitung um Instanziierung, genannt Objekt, von im voraus bekannten Datenstrukturen, genannt Klassen. Funktional ist anders, denn es basiert nicht auf denselben Prinzipien.
Anfang der 1930er Jahre hat Alonzo Church, ein Amerikanischer Mathematiker, eine These aufgestellt. Es ist die Church-Turing-These, besser bekannt als Lambda Calculus, zu Deutsch: Lamdba-Kalkül. In Laienworten gefasst besteht seine These auf der Grundannahme, dass eine Turing-Maschine mit einer beliebigen Vielzahl aber ausschliesslich von mathematischen Funktionen vollständig beschrieben werden kann. Dies hat zur Folge, dass die Idee einer mathematischen Funktion auf die Programmierwelt übertragen werden kann. In der Mathematik ist eine Funktion die Beziehung, die ein Element einer gegebenen Menge zu einem oder mehreren Elementen einer zweiten Menge zuordnet. Das ist mit dem Ausdruck f(x) = y gemeint, wobei x das Argument (Input) und die Variable der Ausgangsmenge darstellt und y das Element (Output) in der Zielmenge.
|
|
Somit ist eine Funktion eine Beziehung zwischen mindestens zwei Elementen aus getrennten Mengen. Eine Funktion oder Beziehung ist immer nur in eine Richtung gegeben.
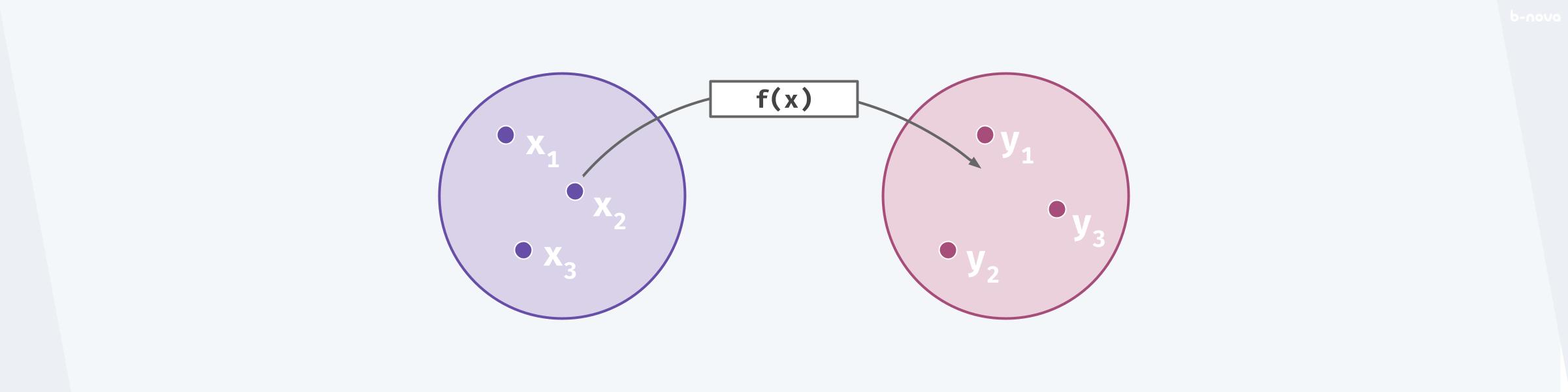
Auf die funktionale Programmierung übertragen spricht man von Referenzieller Transparenz, auf Englisch referential transparency oder referential opacity genannt, wenn eine Funktion sich wie das Abbild oben verhält. Referenzielle Transparenz heisst dass die Funktion pur ist und keine Side-Effects erlaubt. Jetzt könnte der Einwand kommen, dass jede Funktion in jeder beliebigen Programmiersprache sich genau so verhält. Dem ist aber nicht so, da das imperative Paradigma oft einen impliziten Zustand aufweisen muss, um dessen Instruktionen sinngemäss ablaufen zu lassen. Vielleicht verdeutliche ich das am besten mit einem Beispiel, dass ich mir aus dem Buch Get Programming with Haskell von Will Kurt ausleihe:
|
|
Was hier oben in Pseudocode ersichtlich ist, ist der Umstand, dass die Funktion impure_func() nicht sicherstellen kann, dass die Abfolge deren inneren Deklarationen keinen Zustand aufweisen.
|
|
Das obige Snippet ist valider Code in 3 verschiedenen Programmiersprachen, nämlich Ruby, Python und JavaScript. Erstaunlicherweise ist nicht ersichtlich was die Ergebnisse sein werden, ohne die Implementierung der jeweiligen Runtime zu kennen. Sieht und staunet selber:
|
|
Zuerst war Lambda Calculus — eine Genealogie des funktionalen Paradigma
Das funktionale Paradigma ist keine neue Entwicklung, sondern Ausdruck eines Prozesses, welcher wie oben beschrieben seinen Anfang in der theoretischen Mathematik in den 1930er Jahren nahm. Nach Alonzo Church mit seinem Lambda Calculus verfeinerte auch Curry Haskell in den 1930er Jahren die theoretischen Erkenntnisse und entwarf die Hauptaxiome der kombinatorischen Logik, welche die Grundlage für die Berechenbarkeit von Funktionen ohne Variablen und somit weiterführend die Grundlage für die funktionale Programmierung darstellt.
💡 Noch ein Wort zu Lambda: Ein Lambda ist ein Synonym für eine abstrahierte Funktion. Wenn man von Lambdas spricht, so ist immer eine quasi Kontextlose Funktion gemeint, welche idealerweise einen Input in einen vorzeitig bekannten Output transformiert. Der Grund: Die Bezeichnung der Funktion spielt keine Rolle mehr und ist damit perfekt um komplexe Transformationsprozesse in anonyme Teilfunktionen aufzulösen, Lambda-Kalkül halt. 😉
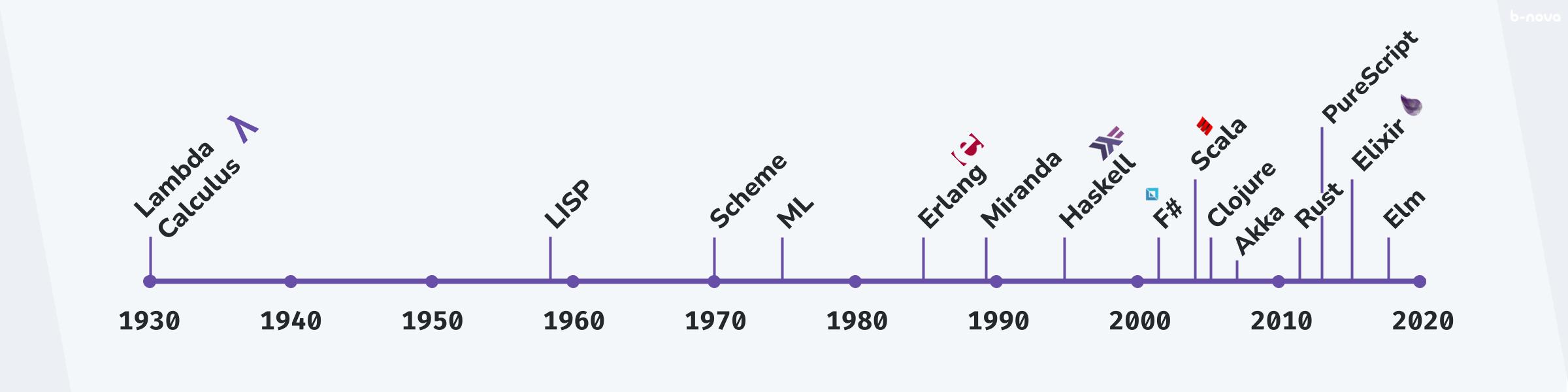
Figure: Quelle: Why Elixir Matters: A Genealogy of Functional Programming — Osayame Gaius-Obaseki, ElixirDaze 2018
Hier werde ich einige Meilensteine der funktionalen Programmiersprachenentwicklung erläutern und diese in Bezug auf die heutige Anwendung setzen:
-
Lisp (1958): Lisp ist die erste Formalisierung einer Lambda-Kalkül-basierten Programmiersprache, welche ein Familie von verschiedenen Lisp-basierten Dialekten wie Common LISP oder Scheme bildet. Erwähnenswert bei Lisp ist der Umstand, dass der Code selbst Daten abbildet und umgekehrt Daten wiederum Code sein können, auch Makro genannt. Lisp steht für List-Processor, Lisp Sprachen sind in der Regel untypisiert. Zuletzt sei vielleicht noch erwähnt, dass Lisp nach Fortran (1957) die älteste noch genutzte Programmiersprache ist.
-
ML (1973): Genau wie Lisp ist auch ML eine Formalisierung des Lambda-Kalküls und stellt eine Familie von weiteren Dialekten wie Standard ML oder CAML dar. ML ist im Gegensatz zu Lisp statisch typisiert und weist eine strengere Auswertung auf. Somit liegt der Fokus bei ML auf den Datentypen und deren funktionale Auswertung. Lisp und ML repräsentieren zwei Unterschiedliche Familien innerhalb der Familie der funktionalen Programmiersprachen, sie ergänzen aber komplementär die Entwicklung späterer Programmiersprachen massgeblich. ML steht ausserdem für Meta Language.
-
Erlang (1986): Erste nicht akademische Entwicklung einer funktionalen Programmiersprache durch Ericsson, wobei die Wahl des funktionalen Paradigma eher ein Ergebnis der nötigen Requirements war. Aus diesem Grund ist das funktionale Paradigma sehr pragmatisch implementiert und nicht allzu streng bei der Auswertung und Umsetzung von klassisch funktionalen Prinzipien.
-
Haskell (1990): Mitunter vielleicht die bekannteste und kontroverseste Umsetzung des funktionalen Paradigma. Haskell ist strikt funktional und erlaubt nur pure Funktionen ohne Side-Effects, sowie ein sehr striktes aber generisches Typensystem. Haskell hat das funktionale Paradigma mit Abstand am meisten ausgebaut und Features geboten, welche alle funktionalen wie auch nicht funktionalen Sprachen beeinflusst hat. Es ist Haskell zu verdanken, dass wir Generics (anonyme), sowie high-order-Funktionen in Java oder JavaScript nutzen können. Haskell ist bis heute auch mein ganz persönlicher Favorit und ich sehe Haskell bis heute als eine der innovativsten Programmiersprachen.
-
F#, Scala, Clojure (ab 2000): Was Osayame Gaius-Obaseki (siehe Quellenreferenz oben) die Renaissance nannte, fing mit F# an und dauert bis heute mit Neuerscheinungen wie Elm oder PureScript an. Hier werden teils funktionale bis vollwertig funktionale Programmiersprachen verwendet, um gängige Runtimes wie die JVM mit Scala und Clojure oder die .NET mit F# anzusprechen. Ein anderes Beispiel wäre die V8 als Target-Runtime mit Elm, PureScript, ClojureScript oder Reason welche nach EcmaScript (sprich JavaScript) transpiliert werden. Der Trend, bekannte, etablierte Plattformen wie JVM, .NET oder V8 mit neuen, quasi funktionalen Programmiersprachen anzusprechen, geht bis heute voran und hat in spezifischen Domänen auch einen gewissen Erfolg.
-
Akka (2009): Akka ist zwar keine Programmiersprache, sollte aber im Kontext von Erlang und Elixir dennoch einen eigenen Eintrag finden, da ab 2009 mit Akka die Verschmelzung von funktionalen Ausdrücken und einer parallelisierten (concurrent) Runtime die Möglichkeit geschaffen wurde, sehr robuste Applikationen schreiben zu können. Akka ist ein Framework (Toolkit), mit dem man in JVM-Sprachen wie Java oder Scala die Möglichkeit hat, eine Actor Model zu nutzen. Akka als zusätzlicher Layer on-top auf JVM bietet somit das, was die OTP mit Elixir/Erlang bietet. Akka wird erfolgreich im Bereich Fintech und überall dort, wo komplexe Konstellationen von Typenabhängigkeiten nötig sind, verwendet.
-
Elixir (2014): Zuletzt sei natürlich vermerkt, dass auch Elixir an der heutigen Speerspitze einer jahrzehntelangen Entwicklung steht und die Vorteile von Erlang ein neuer Audienz anbietet.
Objektorientierter Approach
Um das, was funktionale Programmierung auszeichnet aufzuzeigen, habe ich mich entschieden eine Gegenüberstellung zwischen einem klassisch Objekt-orientierten und einem funktionalen Approach zu machen. Die Ausgangslage sei hier gegeben durch ein Kartenspiel. Ein Kartenspiel besteht aus einzelnen Karten, welche in der Summe den Kartenstapel, bzw. das Kartendeck ergeben.
Im Objektorientierten Paradigma geht es darum, dass zur Laufzeit Objekte instanziiert werden, welche eine gegebene Domäne abbilden sollen. Diese Domäne hier wäre eine Vielzahl von Kartenobjekten, welche durch eine Kartenklasse deklarativ beschrieben wird. Diese Instanz sehen wir in der Grafik unten in Lila. Sie instanziiert die Klasse, welche offensichtlich die Karte mit zwei Feldern this.suit und this.value, beides von Datentyp her eine Zeichenkette (hier einfach String genannt), korrekt abbildet.
Die Instanz eines Kartendecks ist eine Vielzahl von Karten, was einem Datenfeld, bzw. einem Array von Kartenobjekten entspricht. Dies wird mit <Cards>[] exemplarisch dargestellt und ist Teil des Objekts Deck, unten in rosa. this.cards ist somit ein Feld des Deck-Objektes, welches noch weitere Methoden, also Abfolgen von Instruktionen, die zum Ziel haben den Zustand des Objektes abzubilden oder zu verändern, beinhaltet. Diese Methoden sind this.shuffle(), this.save() und this.load().
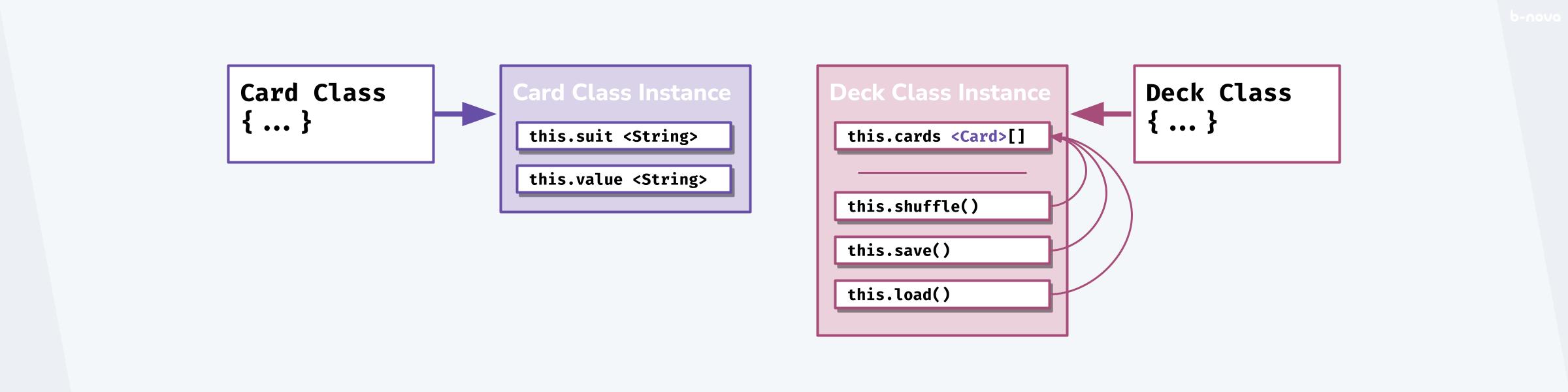
Wir haben somit Objekte welche in einem gegebenen Zustand zur Laufzeit entstehen und für die Ausführung von weiteren ausserkontextlichen Instruktionen verwendet werden. In einer Objektorientierten Programmierumgebung ist das Objekt die primäre Ressource mit der wir versuchen eine gewünschte Funktionalität abzubilden. Somit denken wir in Objekten und die Laufzeit, bzw. dem Lebenszyklus dieser Objekte. Das ist auch die gängigste Art und Weise wie heutzutage programmiert wird. Nicht weil es zwingend die beste oder die effizienteste Art ist, sondern weil sie sich über die Zeit am effektivsten etablieren konnte. Und dies auch zurecht; Es ist ziemlich intuitiv Dinge als Objekte wahrzunehmen.
Funktionaler Approach
Als Gegenstück zur Objektorientierung sei hier nun ein funktionaler Approach gegeben. Wir haben ein Modul Cards. Modul ist keine Klasse und eine Bezeichnung, welche in Elixir verwendet wird, um Funktionen thematisch zu gruppieren. Man kann das Modul auch als Domäne oder Namespace verstehen, worin eine Anzahl von thematisch verwandten Funktionen auffindbar sind. Das Modul Cards stellt in unserem Beispiel also vier Funktionen zur Verfügung, um eine ähnliche Funktionalität zu bieten wie das oben genannt Beispiel mit dessen Objekten.
create_deck() ist unsere erste Funktion und stellt bei jedem Aufruf eine Liste von Zeichenketten <String>[] bereit. Bei diesem Aufruf wird kein Objekt von einer Vielzahl von Karten instanziiert, sondern lediglich ein Bereich im Speicher mit einem Datenfeld von Zeichenketten belegt und für weitere Nutzung bereitgestellt. Bei jedem Aufruf wird ein weiterer Bereich im Speicher belegt und nicht etwa der vorgängigen Bereich referenziert. Es sei angemerkt, dass die Laufzeit der jeweiligen Implementation dies zwar technisch so tun kann, um möglichst effektiv und effizient zu arbeiten, da sie weiss, dass sich nichts am Gesamtzustand verändert hat. Genau dieses Verhalten ist jedoch insofern abstrahiert, dass dieses Denken nicht mehr nötig wird. Das ist die Unveränderlichkeit, auf Englisch auch Immutability, und eine wichtige Eigenschaft der funktionalen Programmierung, mit der Funktionen am liebsten arbeiten möchten. Der Output von create_deck() ist wiederum der Input von shuffle(), da shuffle() eine solche Datenstruktur erwartet und eine weitere unabhängige Datenstruktur als Output bereitstellt, in der die gleiche Anzahl von Karten ausgegeben wird aber in einer anderen Reihenfolge, sofern shuffle() richtig implementiert wurde.
Funktionale Programmierung geht am intuitivsten wenn Transformationen an Daten vorgenommen werden, dessen Input und Output im voraus feststehen. Das ist die Idee der Minimierung von Side-Effects; Nämlich, dass es keine äusserlichen Kontexte gibt, die den Zustand der Daten verändern könnten. Grundsätzlich ist es bei der Abbildung von Businesslogik so, dass die Transformationen gut abgebildet werden können, aber gerade das IO nicht. save() und load() möchte den Zustand gegen eine Persistierungslösung der Wahl (lokales Filesystem, Datenbank, REST-Schnittstelle) aus- und einspielen. Glücklicherweise sind Sprachen wie Erlang und Elixir sehr umgänglich und pragmatisch, wohingegen eine reine funktionale Programmiersprache wie Haskell auf komplexe Transformationsmethoden wie die gefürchtete Monade angewiesen sind. Wir werden hier nicht die Monade erklären aber wir halten fest, dass je strikter das Funktionale ist, umso sperriger ist dann auch die Umsetzung von nötigen Side-Effects.
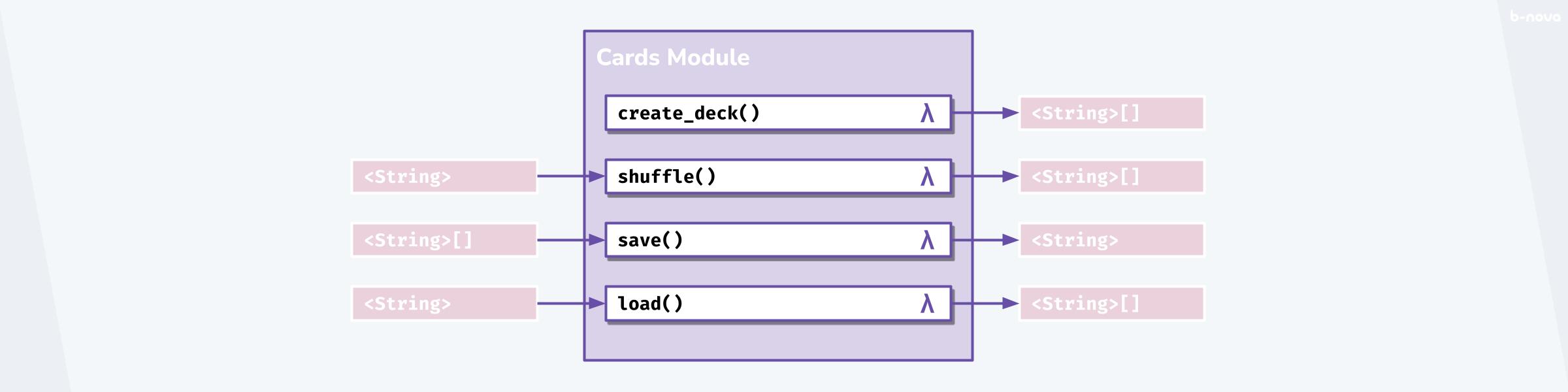
Ganz ohne Instanzen und Objekte kann man also auch eine Abfolge von Transformationen an Kartendatenstrukturen vornehmen, um den Anwendungsfall eines Kartenspiels abzubilden. Alles eine Frage der Perspektive. 🤓
Hauptmerkmale von funktionaler Programmierung
Es gibt gewisse Gemeinsamkeiten, die alle Programmiersprachen haben, welche das funktionale Paradigma teilweise oder vollständig anwenden. Diese Merkmale möchte ich hier kurz auflisten und erläutern, worum es sich dabei handelt.
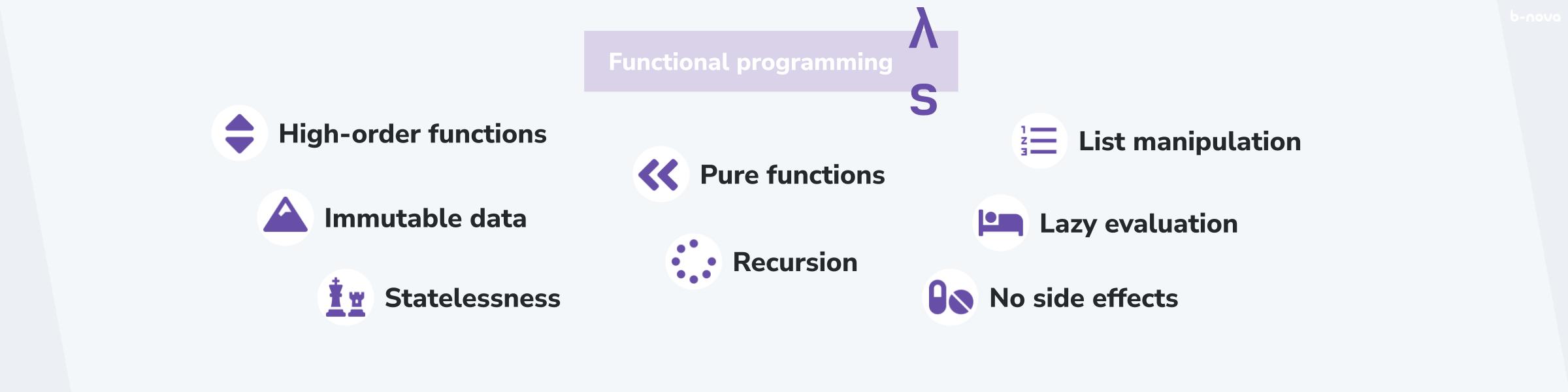
Die Hauptmerkmale von funktionaler Programmierung sind somit folgende Punkte. Sie sind nicht alle in dieser Form notwendig um eine gegebene Sprache funktional betiteln zu dürfen, aber je mehr davon Gebrauch gemacht wird und bei der tatsächlichen Programmierung eine Rolle spielt, desto eher ist die Sprache in einem funktionalen Paradigma anzusiedeln. Des weiteren sei angemerkt, dass die Definitionen hier sehr oberflächlich, bzw. in den praktischen Kontext gesetzt werden, um die funktionalen Eigenschaften so verständlich wie möglich zu gestalten.
- High-order functions: Wenn eine Funktion als Parameter einer anderen Funktion übergeben werden kann und somit die Implementation einer Funktion beliebig generisch gehalten werden kann, so spricht man von High-Order Functions.
- Pure functions: Eine pure Funktion ist gegeben, wenn eine Funktion zu jeder Zeit bei gleichem Inputparameter das gleiche Ergebnis liefert. Dies setzt stets implizit voraus, dass eine gegebene Funktion keinen Eigenzustand kennt und, dass äussere Einflüsse das Ergebnis nicht beeinflussen können.
- Immutable data: Unveränderbarkeit von Datensätzen ist ein weiteres Merkmal. Es gibt keine Referenzen oder geteilte Daten. Jede nötige Datenstruktur wird neu erzeugt und im Speicher belegt.
- Statelessness: Es gibt keine unterschiedlichen Zustände innerhalb oder ausserhalb einer Funktion. Runtimes wie die BEAM stellen selbstverständlich einen Applikationszustand zur Verfügung und reine Sprachen wie Haskell haben Konstrukte wie den Monad um dies zu bewerkstelligen.
- No side-effects: Es gibt keine äussere Einflüsse, die Ergebnisse anders aussehen lassen.
- List manipulation: Listen sind die Datenstruktur der Wahl, da damit am besten strukturierte Daten abgebildet werden können. Die Manipulation von Listen steht oft auch im Vordergrund.
- Recursion: Die Idee das eine Funktion sich selber aufruft um somit die Implementierung einfacher und prägnanter (und schlussendlich mathematisch richtig) abbildet ist oft eine Kerneigenschaft.
- Lazy evalutation: Obwohl Elixir im Gegensatz zu Haskell keine explizite Lazy Evalutation (faule Auswertung) kennt, so ist dies oft ein Merkmal und heisst, dass ein Ausdruck erst ausgewertet wird, wenn dieser für die Ausführung relevant, bzw. signifikant wird.
So, dies war nun unser kurzer und hoffentlich verständlicher Ausflug in die Welt der funktionalen Programmierung. Ich hoffe, dass die Grundprinzipien nun klar sind. Es gibt noch weitere Prinzipien, die in funktionalen Programmiersprachen Anwendung finden; Dazu gehören sicherlich Generics, Macros, Monads und noch viele weitere Merkmale. Gerade Makros werden bei Elixir grosszügig genutzt und sind eigentlich die Grundpfeiler vieler Syntactic Sugars und DSL-fähigen Features.
💡 Ein kurzes Wort zu Generics:
Die Idee von Generics kam schon lange vor Java bei ML und erst richtig mit dem Konzept von erweiterbaren Types Classes bei Haskell vor. Generics sind eine spezifische Implementation von Parametric Polymorphism und bilden sogar im Allgemeinen ein eigenes Programmiersprach-Paradigma.
Das Actor Model
Eine weiteres wichtiges Konzept, um Elixir und die BEAM besser zu verstehen zu können, ist das Actor Model. Wir hatten in Teil 1 der Serie bereits die Robustheit der BEAM, der Erlang VM, mit einem praktischen Test aufgezeigt und seither mehrfach erwähnt, dass die BEAM Prozesse per Scheduling laufen lässt. Das Prinzip, welches hier zur Verwendung kommt, ist eine Sonderform eines Actor Models.
Die Definition eines Actor Models ist im Wesentlichen ganz einfach und kann wie folgt festgehalten werden: Es gibt Actors, also darstellende bzw. agierende Einheiten, welche miteinander über Nachrichten (Messages) kommunizieren. Jeder einzelne Actor hat einen Zustand, welcher komplett getrennt von anderen Actors in den jeweiligen Speicherbereichen abgebildet ist. Die Summe aller laufenden Aktoren stellt den Gesamtzustand einer gegeben Actor-Konstellation dar und kann in der Praxis als Applikationszustand begriffen werden.

Durch diese Actorbasierte Strukturierung von Informationsverarbeitung kann für eine breitflächige Nebenläufigkeit und somit Parallelisierung der Prozessverarbeitung gesorgt werden. Ein Aktor kann in diesem System drei verschiedene Reaktionen vornehmen:
-
Nachricht an andere Aktoren verschicken oder empfangen
-
Das Erzeugen von neuen Aktoren beantragen
-
Das eigene Verhalten, genauer den eigenen Zustand verändern
Des Weiteren ist sicherlich eine nette Anekdote, dass die Idee von Objekten in der Objektorientierte Programmierung ursprünglich daher kommt, dass in der ersten OOP-Programmiersprache von Alan Kay Smalltalk-Objekte Einheiten sind, welche sich untereinander Nachrichten austauschen und mit diesem Verhalten in der Summe eine gewünschte Funktionalität abbilden sollen. Vereinfacht gesagt ist das Grundidee von OOP eine generische From des Actor Models, zeichnet sich dabei also nicht in erster Linie durch Klassenbasierten Polymorphismus und Encapsulation aus. Aber ja, die Geschichte ist schlussendlich anders gekommen und heute haben sich Wahrnehmung und die entsprechenden Definitionen gewandelt.
Der Supervisor-Tree
Die BEAM nutzt eine Supervisor-Struktur. Diese Struktur ist so aufgebaut dass ein Supervisor eine gegebene Anzahl von Entitäten und wahlweise weitere Sub-Supervisors oder Prozesse besitzt. Die Gesamtheit dieser Verbindungen als sogenannter Supervisor-Tree aufgebaut. Das heisst, dass die Verbindungen Baumartig aufeinander aufbauen. Der Supervisor-Tree ist die technische Spezifikation einer Sonderfrom der Actor Model Implementation.
In der untenstehenden Grafik ist diese Baumkonstellation ersichtlich. Ein Top-Level Supervisor überwacht hier beispielsweise zwei weitere untergeordnetet Supervisors, welche wiederum jeweils zwei Prozesse überwachen. Sobald ein Knoten, Supervisor oder Prozess ausfällt, also nicht mehr erreichbar ist, da zur Laufzeit ein einschneidiger Fehler aufgetreten ist, tritt ein Mechanismus in Kraft, welcher einen heilen Zustand durch Reviving, sprich, Wiederbelebung über einen Restart des Knotens anstrebt.
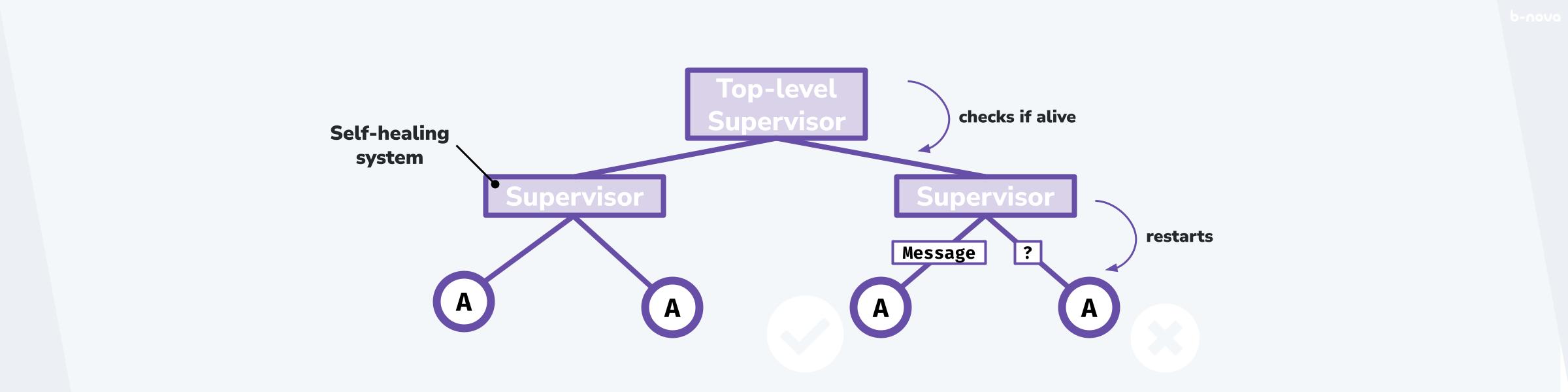
Der Wiederbelebungsmechanismus unterliegt einer vorgegebenen, im Normalfall vom Entwickler explizit deklarierten Strategie. Diese Strategien sind von der BEAM vorgegeben, die Dokumentation dazu liegt deswegen auf der Erlang-Ebene.
-
one_for_one: If a child process terminates, only that process is restarted. -
one_for_all: If a child process terminates, all other child processes are terminated, and then all child processes, including the terminated one, are restarted. -
rest_for_one: If a child process terminates, the rest of the child processes (that is, the child processes after the terminated process in start order) are terminated. Then the terminated child process and the rest of the child processes are restarted. -
simple_one_for_one: A supervisor with restart strategysimple_one_for_oneis a simplifiedone_for_onesupervisor, where all child processes are dynamically added instances of the same process.
Diese Strategie wird typischerweise direkt in einer lib/Application.ex in den jeweiligen opts = [strategy: :one_for_one, ...] deklariert und definiert das Supervisor-Verhalten der Applikation.
|
|
Die Vorteile von Elixir
Nochmals kurz zusammengefasst, was Elixir auszeichnet:
-
Elixir läuft auf der BEAM, einer Runtime auf Basis von Actor Model
-
Elixir hat einen Ruby-artigen Syntax
-
Elixir unterliegt dem funktionalen Paradigma
-
Elixir nutzt dynamische Typisierung
Elixir in Aktion
Für dieses TechUp habe ich extra ein Udemy Kurs über Elixir und Phoenix abgeschlossen. In diesem knapp 18-stündigen Kurs, The Complete Elixir and Phoenix Bootcamp von Stephen Grider wird unter anderem Elixir anhand eines Spielkarten-Projekts veranschaulicht. Dieses Projekt möchte ich jetzt auch hier verwenden, um dir die Grundzüge und die Syntax von Elixir näher zu bringen. Die dazugehörige Git-Repository ist unter hier vorfindbar. Das Problem ist, dass damals eine ältere Version von BEAM verwendet wurde, die seither nur bedingt upgedated wurde. Daher können Sie unseren b-nova-Fork davon nutzen, um hier mitmachen zu können.
Texas Hold’em mit Elixir
Zuerst teilen wir mix mit, dass wir ein neues Projekt mit dem Namen cards erstellen möchten. Mit dem untenstehenden Befehl mix new cards wird das Projekt wie erwartet in einem neuen cards-Verzeichnis erstellt und mit den wichtigsten Dateien versehen, die wir brauchen, um das Projekt zu kompilieren.
|
|
Neben einem README.md, einer .gitignore erstellt mix Elixir-spezifische Dateien und Verzeichnisse. Es gibt ein test/- sowie ein lib/-Verzeichnis. Im Letzteren befindet sich unser Einstiegspunkt in das Programm mit einer cards.ex Elixir-Sourcedatei. Diese lib/cards.ex-Datei ist mit Vorlagecode versehen und erlaubt es uns, gleich mit coden anzufangen.
lib/cards.ex
|
|
Jetzt erstellen wir unsere erste Funktion im Cards-Modul. Diese Funktion ist soll uns ein komplettes Deck von französischen Spielkarten erstellen. In Elixir sind Funktionsnamen nicht etwa wie in Java mit CamelCase zu benennen, sondern folgen der Underscore-separierten Namenskonvention.
|
|
Mit der Elixir Interactive Shell, kurz IEx, können zu jeder Zeit kompilierte Module wie auch die BEAM angesprochen werden.
|
|
Jetzt probieren wir versuchsweise mal das Cards-Modul mit unserer ersten Funktion create_deck aufzurufen.
|
|
Das fertige Cards-Modul soll schlussendlich wie folgt aussehen:
|
|
Unter defps deps do fügen wir jetzt eine neue Dependency hinzu, welche es uns ermöglicht, die Dokumentation bei der Kompilierung zu erzeugen. Die Dependency wird mit dem Ausdruck {:ex_doc, "~> 0.21"} definiert.
mix.exs
|
|
💡 mix deps.get holt sich die Dependencies und löst die nötigen Third-Party-Packages mit einem Package-Manager namens Hex auf. Hex ist der Package Manager sowie das Artifact Repository zugleich. Die öffentlichen Packages kann man auf Hex hier einsehen.
Kompilierung:
|
|
Erstellung Dokumentation:
|
|
Aufruf in Browser
|
|
Ähnlich wie bei Rust und Cargo wird auch hier ein vollwertige Dokumentation inklusive Styling generiert:
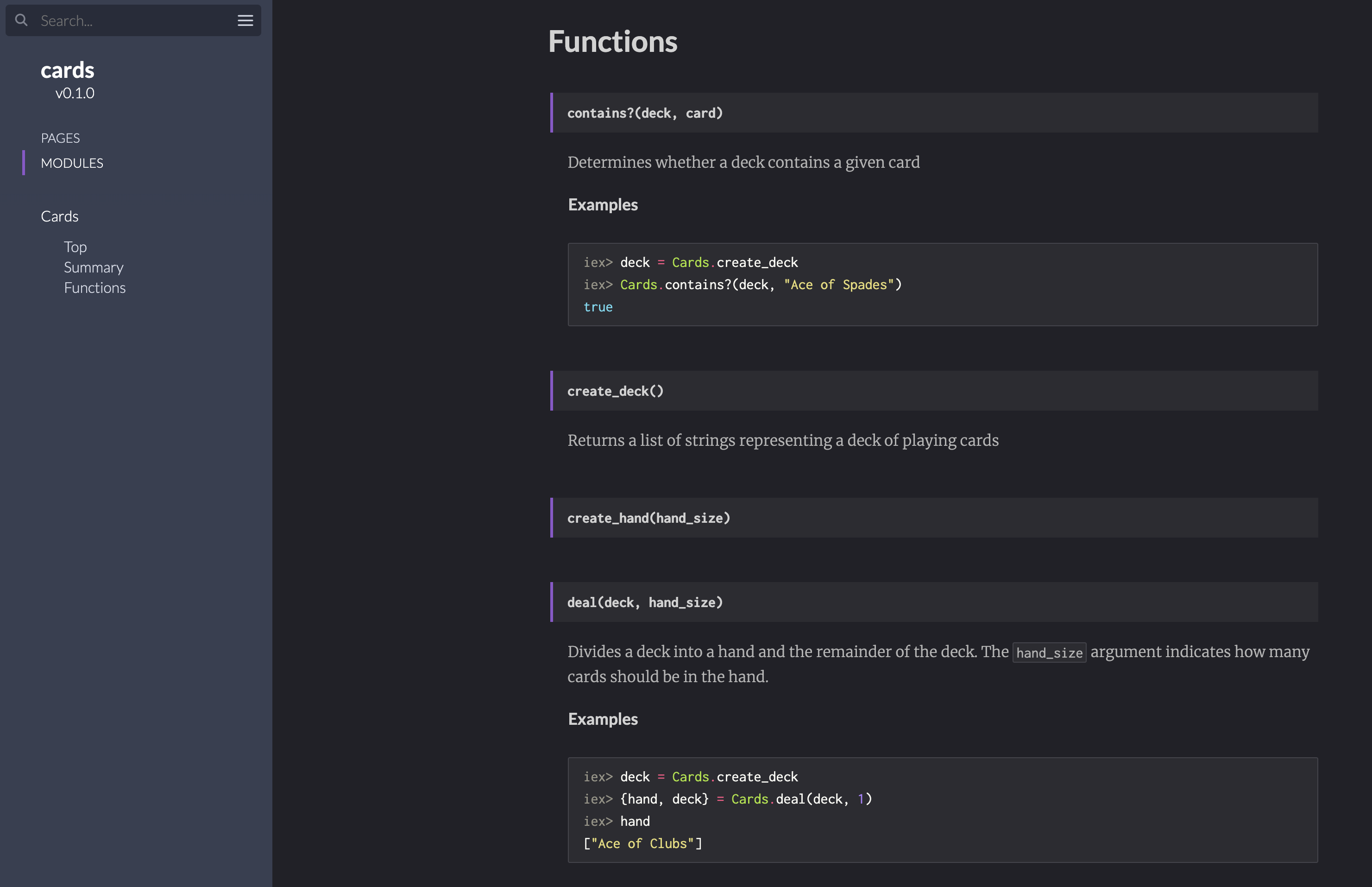
Fazit
Wir haben uns heute eine Übersicht über die Grundlagen der funktionalen Programmierung im Allgemeinen, wie auch den damit zusammenhängenden Merkmalen verschafft. Dabei haben wir gesehen, inwiefern sich funktionale Programmierung von objektorientierter Programmierung unterscheidet und gesehen, dass das funktionale Paradigma einige entscheidende Vorteile mit sich bringt. Zudem haben wir zwei weitere wichtige Merkmale von Elixir und der BEAM kennengelernt, nämlich das Actor Model und Supervisor-Trees. Zum Schluss haben wir unsere neu gewonnenen Erkenntnisse vertieft und gesehen, wie die Implementierung eines Kartenspiels in Elixir aussehen könnte. Macht spass, oder? 🤩
In Teil 3 der Elixir-Serie schauen wir uns das Hauptframework von Elixir, nämlich das Phoenix-Framework an - ein Grosses Geschütz in Sachen Web-Applikationsentwicklung. Bleib dran! 💪