Von Proxy zu Proxy
Jeder Entwickler hat das Wort Proxy im Kontext von IT-Infrastruktur sicher schon mal zum hören bekommen. Die Frage, was ein Proxy genau ist und was dieser macht, ist die Ausgangsfrage des heutigen TechUps. Wir schauen uns Web-Proxies allgemein und insbesondere einen Subtyp davon, nämlich dem Reverse-Proxy, an. Falls du dich auch schon gefragt hast, was es damit auf sich hat, ist dieses TechUp genau an dich gerichtet. Steig ein und lerne, was sich hinter einem Proxy verbirgt.
Am Anfang war der Proxy
Das Wort Proxy kommt von lateinischen “Procuratorem”, verwandt mit dem Englischen Procurator, was zu Deutsch “für etwas Sorge tragen” steht. Sprachlich kann ein Proxy somit als Vermittler zwischen zwei Parteien angeschaut werden, was dem IT-Begriff Proxy doch sehr nahe kommt.
In der Netzwerktechnik ist mit einem Proxy das Bindeglied zwischen zwei Rechnern gemeint. In der untenstehenden Grafik kann man den Proxy in seiner einfachsten Ausführung betrachten. Dort schickt ein Computer auf der linken Seite eine Nachricht an die Destination des Computers auf der rechten Seite. Dabei fungiert ein Proxy (in rot in der Grafik) als Vermittler zwischen den beiden Geräten.
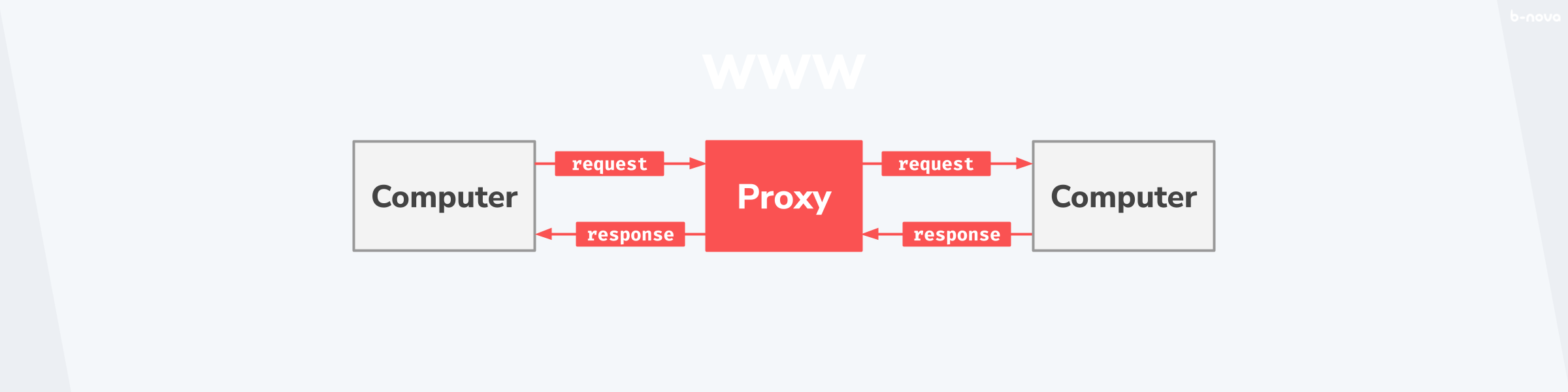
Klassischerweise ist mit dem linken Rechner einen “Client” gemeint, welcher über den Proxy eine Ressource vom Server anträgt, und diese als Antwort zugestellt bekommt. Dieser Vorgang ist so konventionell und in der Netzwerktechnik, welche heutzutage die gesamte Kommunikation in privaten und öffentlichen Netzwerken (wie dem Internet) beinhaltet, so fundamental, dass man diesen Vorgang schon früh in der Geschichte des Internets in einem Leitpapier des CERNs festgehalten hat.
In diesem “Paper” aus dem Jahre 1994 wird der Proxy als solches noch auf gewisse Merkmale reduziert, welche heute nur noch einen Teilbereich von dem abbilden, was eine Proxy-Lösung können muss. Die Grundidee des Vermittlerelements mit der bidirektionalen Kommunikation zwischen zwei physisch getrennten Rechnereinheiten war jedoch zielweisend. Im Paper wird der Proxy auch auf seine Fähigkeit reduziert, in HTTP, einem Application Layer Protocol, und FTP zu kommunizieren. Dies ist insofern erwähnenswert, da Proxies neben der Applikationsebene auch auf der Netzwerkebende interagieren und dort eine Vermittlerrolle übernehmen können.
Vielleicht noch wichtiger als die Unterscheidung der Abstraktionsebene, auf welcher der Proxy zu interagieren hat, ist der Umstand, dass ein Proxy selten alleine kommt, sondern eine gebene Nachricht eine Vielzahl von Proxies durchmacht, bis diese an ihre Destination ankommt. Somit kann jede Haltestelle als Proxy abstrakt vereinfacht werden. Gerade wenn die Nachricht von einem Client über das World Wide Web hin zu einem Server gehen soll, so sind die einzelnen Sprünge – sogenannte “Hops” – quantitativ in den höheren Dutzend anzusiedeln.
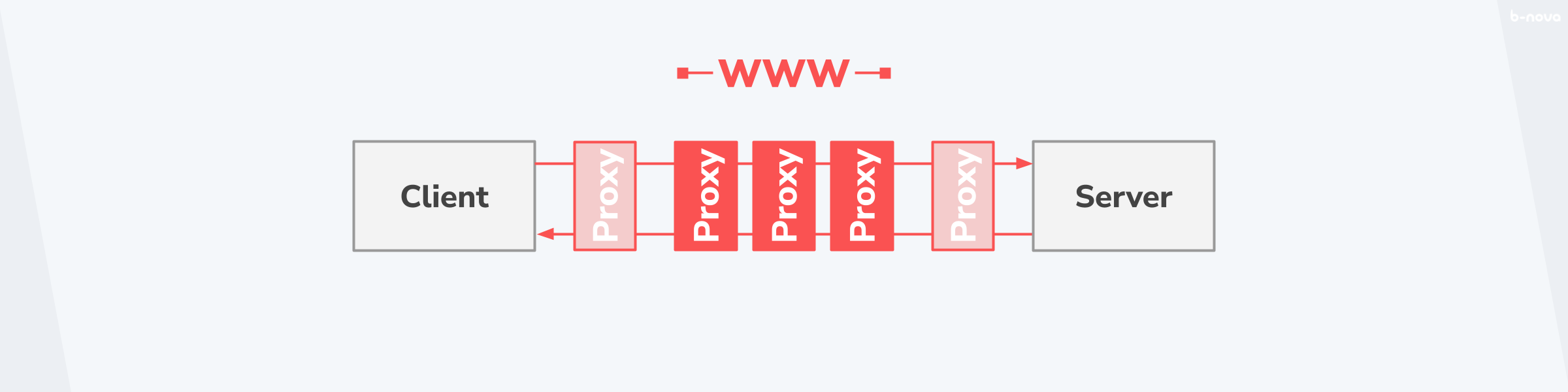
Dies ist wichtig im Hinterkopf zu behalten, da der Ausfall, beziehungsweise das Fehlverhalten eines dieser Haltestellen, die Konsequenz hat, dass die Nachricht gar nicht, oder in einem unerwünschten Zustand ankommt und dadurch für weitere Probleme sorgt, wenn damit nicht richtig umgegangen wird.
Geht es vorwärts oder rückwärts?
Der aufmerksame Leser mag sich wahrscheinlich die Frage stellen, warum es überhaupt Proxies zwischen Rechnern geben muss und was diese überhaupt genau machen. Bevor wir dies beantworten können, muss ich noch eine Unterteilung der Proxies vornehmen, nämlich eine Unterteilung je nach Positionierung des Proxies in Bezug auf die Quell- und Zielsysteme.
Lass uns zur Veranschaulichung eine typische Verbindung eines Clients über das Internet an einen Server nehmen. Dabei kann der Proxy an zwei Positionen im Lebenszyklus der Message vorkommen. Nämlich zwischen dem Client und dem WWW, oder zwischen dem WWW und dem Server. Im ersten Fall spricht man von einem Forward Proxy und im zweiten Fall von einem Reverse Proxy.
Schauen wir uns zuerst einmal den ersten Fall, den Forward Proxy, etwas genauer an.
Der Forward Proxy
In ganz einfachen Worten gesagt, leitet ein Forward Proxy den Traffic von Clients an das Internet weiter. Dabei übernimmt der Forward Proxy die Aufgabe zu entscheiden, ob ein gegebene Verbindung raus ins Internet darf, und persistiert gleichwertige Messages, um den allgemeinen Traffic hin zum Internet performanter zu gestalten. Somit fungiert der Forward als Vermittler zwischen Clients und dem Internet und “verschleiert” dadurch das interne Netz vor dem öffentlichen Internet.
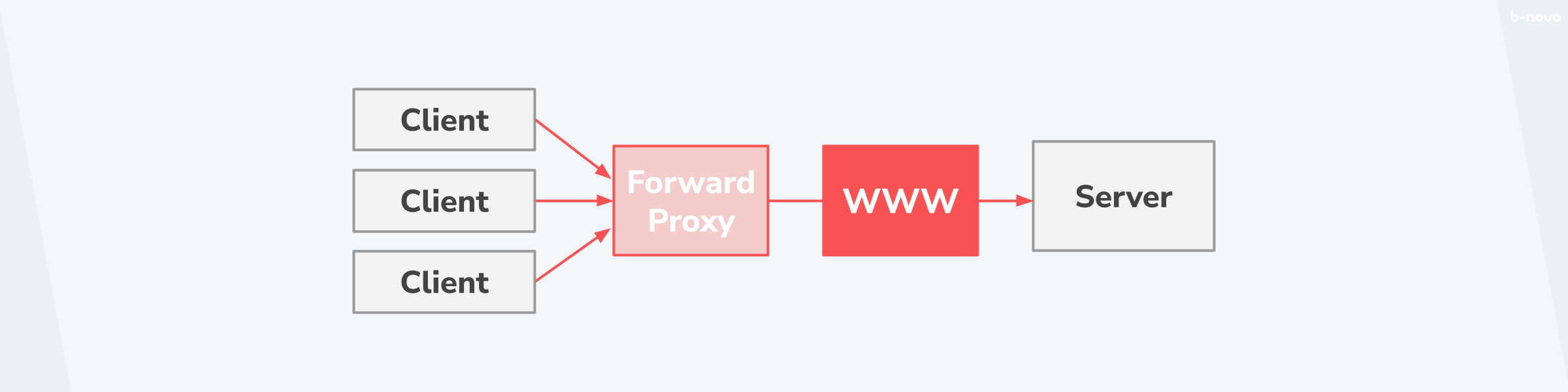
Der klassische Anwendungsbereich eines Forward Proxy ist die Anonymisierung der Quelladdresse. Eine weitere wichtige Funktion, die ein Forward Proxy übernimmt, ist als Firewall vor Anfragen an Zielsysteme über das Internet.
Gerade in Grossbetrieben ist der Forward Proxy die letzte Instanz einer gewarteten Komponente, bevor ein Request rausgeht, und eignet sich dadurch bestens, um den gesamten Web-Traffic zu überwachen, was überlicherweise auch gemacht wird.
Der Reverse Proxy
Wenn ein Forward Proxy den Traffic von einem Client in das Internet weiterleitet, dann ist der umgekehrte Prozess der Reverse Proxy. Bei einem Reverse Proxy wird der Traffic aus dem Internet an die Zieldestination weitergeleitet und der Proxy dient als Vermittler zwischen dem Internet und den Servern.
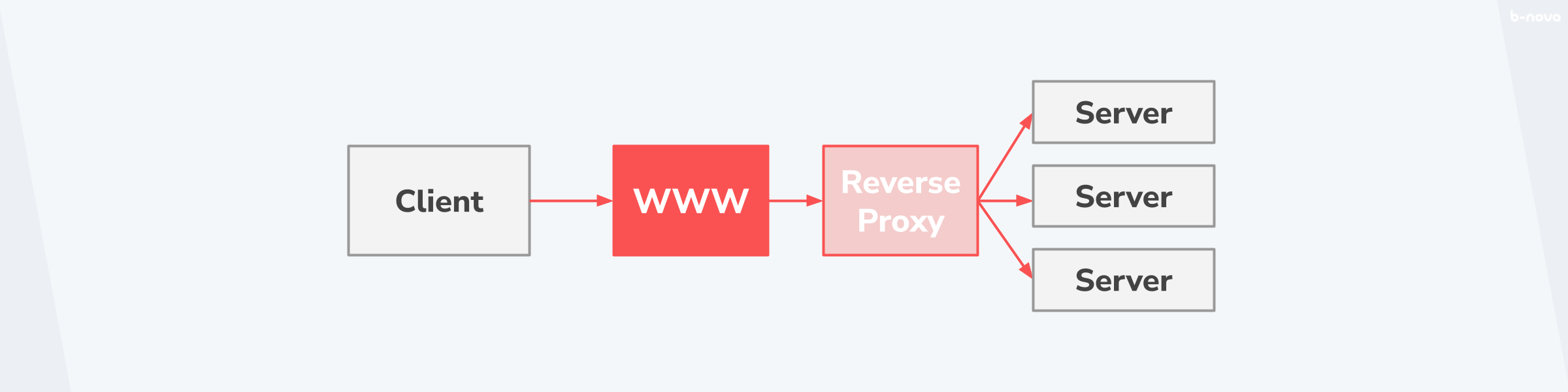
Die Anwendungsbereiche eines Reverse Proxys sind vielzählig und man findet Reverse Proxies oft in einer Vielzahl von nacheinander geschalteten Proxies, welche alle einen anderen Funktionsbereich abdecken. Dazu gehören folgende Anwendungsbereiche:
-
Encryption / SSL-Acceleration: Oft ist es nicht der Webserver, welcher für die Verschlüsselung des “Secure Sockets Layers” (SSL) verantwortlich ist, somit übernimmt dies ein Proxy. Das kann auch mit dedizierter “SSL-Acceleration-Hardware” gemacht werden, welche besonders effizient SSL-Verschüsselung vornehmen kann.
-
TLS-Terminierung / Re-Encryption: Auch die TLS-Terminierung eines HTTPS-Requests kann über einen Proxy vorgenommen werden. Dieser entschlüsselte Request kann dann auch nochmals mit einem Firmeninternen Client-Zertifikat neu verschlüsselt werden.
-
Load-Balancing: Falls der Traffic auf mehrere Zielserver verteilt werden muss, ermöglich ein Proxy einen Lastausgleich (Load-Balancing) des eintreffenden Verkehrs und spricht einen Zielserver mit einem gewünschten Scheduling-Algorithmus an. Load-Balancing kann wahlweise auf Applikationsebene, dem sogenannten Layer 7 nach dem OSI-Modell, oder auf Netzwerk-Ebene, dem Layer 4, stattfinden.
-
Caching: Ein Reverse Proxy kann auch den Traffic optimieren, indem statische Dateien wie Bilder oder Dokumente für eine gewisse Zeit gespeichert werden. Das nennt man Caching und ist Hauptbestandteil eines Content Delivery Networks (CDN). Beispiele für ein CDN sind Cloudflare oder AWS CloudFront.
-
Compression: Ein Reverse Proxy kann noch weitere Optimierungen vornehmen, indem der Inhalt komprimiert wird, was zu einer Verbesserung der Ladezeiten führt.
-
Spoon-Feeding: Reduziert den Ressourcenverbrauch des Servers, welcher durch langsame Clients verursacht wird, indem der Content “gecached” wird und dieser dem Client in kleinen “Häppchen” – Spoon-Feeding – wieder zurück kommt.
-
Authentifizierung: Ein Reverse Proxy kann auch eine Authentifizierung gegen einen Idendity-Provider vornehmen und beispielsweise JWT-Token generien lassen, welche dann an den Server weitergegeben werden.
-
Sicherheit: Ein Reverse Proxy kann natürlich auch “Web Access Lists” (ACLs) validieren lassen, um Anfragen falls notwendig komplett zu blockieren. Damit übernimmt der Proxy eine Sicherheitsfunktion.
-
HTTP-Transformationen: Ein Reverse Proxy kann auch gewisse Transformationen und Filterfunktionen an eingehende Requests und ausgehenden Responses vornehmen. Typischerweise kann man da Header-Einträge erweitern, entfernen oder einfach abändern.
-
Extranet-Publishing: Ein Reverse-Proxy kann direkt zwischen den Internet und einer betriebsinternen Firewall stehen, um somit Extranet-Funktionalität bereitzustellen. Die eigentlichen Zielserver wären dabei im internen Intranet, welche hinter der Firewall stehen würden.
Jeder oben genannte Anwendungsbereich verdient sicherlich ein eigenes TechUp, worin noch genauer auf den Use-Case eingegangen würde und man auch anschauen könnte, wie man das in einer gegeben Proxy-Technologie technisch umsetzten könnte. Das würde jedoch den Umfang diesese TechUps überschreiten. Falls dich das Thema interessiert, solltest du jedoch unbedingt einen Blick in das TechUp von Tom zum Thema AWS CloudFront werfen - ziemlich spannend.
Der Gateway und Tunneling Proxy
Es gibt noch eine dritte Gruppe von Proxies. Diese sind weder Forward, noch Reverse Proxy, sondern liegen zwischen diesen beiden Systemen. Da ist einerseits der Gateway Proxy und der abstraktere Tunneling Proxy. Ich werde darauf in diesem TechUp nicht weiter eingehen aber hier sind einige Beispiele, in denen diese dritte Gruppe von Proxies zur Verwendung kommt:
- Internet-Gateway
- NAT-Gateway
- Tunneling-Proxies im WWW wie Tor
- Switches, Router, PoPs oder weitere Internet-Hardware
Da war noch was mit HTTP
Obwohl es eine Vielzahl von Web-Protokollen gibt, ist keines so weit verbreitet und allgegenwärtig, wie das “Hypertext Transfer Protocol”, kurz HTTP. Das von Tim Berners-Lee am CERN entwickelte Protokoll ist bis heute der Web-Standard schlechthin und auch die Abstraktionsebene, auf der ein Layer 7-basierten Proxy interagiert. Aus diesem Grund möchte ich hier nur einen kleinen Auffrischer geben, wie ein HTTP-Request und dessen Response aussieht, und wie ein Proxy damit umgeht.
Grunsätzlich besteht eine HTTP-Verbindung, HTTP-Message genannt, eine Anfrage, der HTTP-Request, und eine Antwort, die HTTP-Response. Die ganze Verbindung läuft über eine TCP-Verbindung und ist in einer sogenannten “Session” containerisiert.
Ein Request könnte wie folgt aussehen:
|
|
Eine mögliche Response dazu etwa wie folgt:
|
|
Es gäbe hier noch viel zu erklären, falls man HTTP noch tiefer kennen sollte, aber im Kontext von Proxies möchten wir gerne wissen, wie ein Proxy mit HTTP umgehen kann. Lass uns also definieren, wie genau der Proxy auf eine gegebene HTTP-Message Einfluss nehmen kann.
In der folgenden Grafik ist der Lebenszyklus einer HTTP-Message aufgezeigt. Dieses Beispiel setzt nur einen Proxy voraus. In der realen Welt sind diese kaskadiert und die einzelnen Transformation haben einen Effekt auf die darauf folgende Entgegennahme der Message.
![]()
Der Client versendet einen Request, welcher über den Proxy an den Server weitergeht. Der Request erfährt eventuell eine Transformation λreq und ist vor dem Proxy im Zustand req' und nach dem Proxy im Zustand req''. Genau das gleiche Prinzip gilt für die Response, die vom Server über den Proxy zurück an den Client geht. Diese erfährt eine Transformation λres, wo der Request vor dem Proxy den Zustand res' und nach dem Proxy einen Zustand res'' hat.
Diese Transformationen können das Hinzufügen oder das Entfernen eines Header-Feldes sein, eine Kompression des Bodys oder gar eine TLS-Verschlüsselung der gesamten Message. Diese Möglichkeit ist wichtig im Hinterkopf zu behalten, wenn man das Verhalten einer Gesamtarchitektur mit mehreren Proxies beurteilen möchte, um vielleicht etwa eine fehlerhafte Transformation per Debugging zu identifizieren und zu isolieren.
Proxy in der Praxis
Als Entwickler oder DevOps-Engineer hat man typischerweise mit dem Reverse Proxy zu tun. Das kann beispielsweise ein Load Balancer sein, welcher den eintreffenden Traffic auf eine Vielzahl von Instanzen des Applikationsservers aufteilt. Dieser Lastenverteiler kann mit verschiedenen Technologien bereitgestellt werden. Jetzt möchten wir mal einen kleinen Überblick geben, was für zeitgemässe Reverse Proxy-Lösungen es überhaupt auf dem Markt gibt und wie diese sich voneinander unterscheiden.
Eine Proxy-Technologie ist zeitgemäss, wenn diese weiterhin entwickelt wird sowie einerseits die neuen Web-Standards unterstützt und andererseits das Feature-Set gewisse Cloud- und Containerisierungsansätze mitliefert. Mit dieser Definition kommt man auf folgende Technologien (Stand 2022):
- F5’s NGIИX
- HAProxy
- Traefik
- Envoy
- Cloud-Provider-Lösungen wie der AWS Elastic Load Balancing oder der Google Cloud Load Balancing
Nehmen wir mal einen Reverse Proxy aus dieser Liste raus und setzen ihn mal lokal auf dem Rechner auf. Obwohl der NGINX mittlerweile weit verbreitet ist, ist der HAProxy mitunter die populärste und bekannteste Lösung. Lass uns deswegen mal mit einem idiomatischen HAProxy durchstarten.
HAProxy in Aktion
Da wir bei b-nova in der Cloud-Welt unterwegs sind und gerne mit Anwendungen in einer containerisierten Form umgehen möchten, sei schonmal im Voraus gesagt, dass HAProxy offizielle Images auf der Docker-Registry anbietet.
Dort gibt es Stand beim Verfassen dieses Aufsatzes die Version 2.5 als Image. In der Beschreibung auf der offiziellen Docker-Registry-Seite von HAProxy wird beschrieben, wie man die Konfiguration vornimmt und diese in ein Image reinbringt. Das sieht wie folgt aus:
|
|
Weiter wird gezeigt, wie man das Image baut und wie man die Konfiguration über eine Container-Instanz des gebauten Images validieren lässt. Zuletzt ist noch die Ausführung des Containers beschrieben. Dies sieht in der Kommandozeile wie folgt aus:
|
|
Soweit, so gut. Damit möchten wir aber gerne die ganze Strecke vom Aufruf einer HTTP-Message über den HAProxy hin zu einem Zielserver simulieren und nachbilden. Das Zielsystem dabei, der Origin-Server, wird in unserem Fall ein Instanz von ealenn/echo-server sein. Der Proxy wird bei einem Aufruf den HTTP-Request an diesen echo-server weiterleiten und die HTTP-Response davon wieder zurück an den Absender zurücksenden. Der Aufruf für diese Simulation kommt nicht etwa aus dem Internet, sondern klassisch über den curl-Befehl. Grob kann man diese Konstellation in einem kleinen Skizzierung wie folgt aussehen lassen:
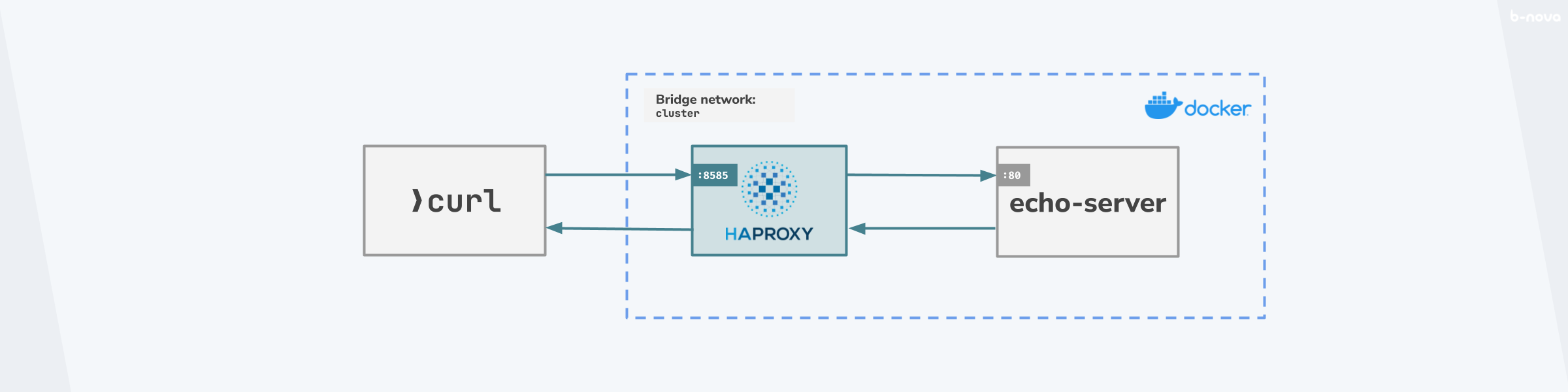
Die Idee ist gegeben, jetzt können wir starten und uns die Komponenten zusammenbauen. Zuallererst brauchen wir eine valide haproxy.cfg-Konfigurationsdatei für den HAProxy.
I. Die Konfiguration
Die haproxy.cfg-Konfigurationsdatei ist das Herzstück unserer Simulation, da dort so ziemlich alle Variablen abgebildet sind. Das Format einer solcher haproxy.cfg ist HAProxy-spezifisch und ist in der Dokumentation ausführlich beschrieben.
|
|
Die haproxy.cfg-Konfigurationsdatei hat 4 Sektionen, oder auch “Stanzas” genannt. Diese sind in einem offiziellen Beitrag über The Four Essential Sections of an HAProxy Configuration sehr gut beschrieben. Hier nur ein kleiner Abriss davon:
-
global: Unter demglobal-Stanza werden prozessübergreifende, low-level Konfigurationen, die sich für Sicherheits- oder Performance-Tunings eignen, zusammengefasst. Im diesen Beispiel haben wir nur einenlog-Eintrag, welcherinfo-LogLevel in denStandard Outputherausloggt. -
defaults: Unter demdefaults-Stanza werden Defaultwerte definiert, die dann von spezifischeren Sektionen überschrieben werden können. Dies ist hilfreich bei grösseren Konfigurationsdateien, die viele Backend- oder Frontendstanzas haben. Im Beispiel nutzen wirmode http, was heisst, dass alles auf der Applikationsebene bzw. auf OSI-Level 7 als Default laufen soll. Der Alternativwert wäremode tcp. Ansonsten gibt es noch gewissetimeout-Werte für die entsprechenden Vorgänge. -
frontend: Neben denglobal- unddefaults-Stanzas gibt es zwei wichtige Sektionen, die zwingend benötigt werden. Dasfrontend-Stanza definiert, wie der HAProxy eintreffende Requests abhört. Im Beispiel wird der Port8585für den “Incoming Traffic” gebunden. Dieser wird an ein Default-Backend-Serverbe_srvrweitergereicht. -
backend: Dasbackend-Stanza definiert das oder die Zielsystem(e), wohin der eintreffende Verkehr weitergeleitet werden muss. In unserem Beispiel gibt es keine Lastverteilung, da wir hierfür mindestens zwei Backend-Server angeben müssten. Es gibt aber einen Serversrvr0mit der Adresse127.0.0.1:80.
Die Konfigurationsdatei unterstützt native das Einspeisen von Umgebungsvariablen. Das ist sehr nützlich, wenn man die Containerisierung flexibel halten möchte. In unserem Fall ist es von Vorteil, die Quell- und Zielvariablen dynamisch zu handhaben und diese zur Laufzeit des containerisierten HAProxy mitzugeben. Aus diesem Grund nehmen wir eine leichte Anpassung an der obigen haproxy.cfg-Konfigurationsdatei vor und ersetzen den Bind-Port in der frontend-Stanza, sowie der Server-Adresse (dort jeweils die IP und den dazugehörigen Port) in der backend-Stanza.
Die zwei Stanzas in der haproxy.cfg sehen dann wie folgt aus:
|
|
Falls man haproxy als Dependency bereits irgendwo installiert haben sollte, kann man mit haproxy -c -f /path/to/haproxy.cfg die Konfiguration validieren lassen. Falls nicht, geht das auch mit dem Container, den wir jetzt gleich aufsetzen werden.
II. Die Containerisierung
Das Dockerfile ist bereits gegeben und wir können dies eigentlich so belassen, wie es bereits als Vorlage ausgewiesen wurde. Der Default-Pfad der haproxy.cfg-Konfigurationsdatei ist /usr/local/etc/haproxy/haproxy.cfg. Wichtig ist, dass die oben erstellte Konfigurationsdatei im gleichen Verzeichnis liegt, wie auch die jetzt erstelle Dockerfile.
|
|
III. Die Simulation
Da wir nur ungerne eine Vielzahl von Shell-Befehlen kaskadieren, schlage ich vor wir nehmen alle nötigen Schritte in einem Bash-Skript auf. Dadurch wird der ganze Prozess transparenter, nachvollziehbarer und leicht anpassbar.
Die Idee hier ist, dass man mit Docker und dem Dockerfile ein Image b-nova-techup/haproxy:0.0.0 bauen lässt, welches dann die haproxy.cfg-Konfigurationsdatei validiert und im Anschluss ein Docker-Netzwerk startet, worin dann einmal der HAProxy und einmal der echo-server läuft. Danach wird per curl mit ausführlichem Output zehn Mal ein HTTP-Request gegen den HAProxy abgefeuert, welcher im Idealfall die Requests weiter an den echo-server ohne nennenswerte Transformationen weiterleitet. Zu guter letzt werden die Container gestoppt und das Netzwerk abgebaut.
Und so kann das in einem Bash-Skript aussehen. Das Skript nennt man am besten run.sh. Erwähnenswert ist der Umstand, dass der Port, worauf HAProxy hört, 8585 ist. Der Rest des Skripts – so denke ich – ist relativ selbsterklärend.
|
|
Ja, jetzt sind wir bereit, die Simulation durch das Ausführen des Bash-Skripts durch ./run.sh zu starten.
|
|
Im stdout wird curl die entsprechenden HTTP-Requests und -Responses als Output ausgeben. Somit haben wir erfolgreich die Grundfunktionalität des HAProxy, nämlich der Vermittlung einer HTTP-Message zwischen einem Quell- und Zielsystem, implementiert. Selbstverständlich kann der HAProxy noch viel mehr und genau ab diesem Punkt wäre es interessant, Transformationen an dem Request oder der Response vorzunehmen, eine Authenfizierungsflow gegen einen Identity-Provider oder gar ein Traffic-Shadowing vorzunehmen. All dies ist mit HAProxy (oder einen anderen Proxy-Lösung wie NGINX) möglich.
Diese Ideen würde ich aber gerne in einem zweiten, weiterführenden TechUp thematisieren. Ich hoffe, du weisst jetzt etwas besser, was ein Proxy, insbesondere ein Reverse Proxy, ist und wie man einen solchen Proxy mit HAProxy aufsetzen kann.
Das obige praktische Beispiel habe ich in eine Git-Repository auf GitHub platziert, man kann es entsprechend einfach nutzen.
Weiterführende Links und Ressourcen
Proxy servers and tunneling | MDN Web Docs