Bei fast jeder Applikation stellt sich die Frage, wo werden meine Daten gespeichert? Brauche ich einen Cache? Ist die Datenbank oder der Speicherort mein Bottleneck? Heute wollen wir uns Redis genauer anschauen, die Vor- & Nachteile erkunden und das ideale Einsatzgebiet ausloten.
Redis
Redis selbst beschreibt sich als open source, in-memory data structure store, welche man als Datenbank, Cache oder Message Broker einsetzen kann. Einfach gesagt läuft irgendwo ein Server, welche die Speicherung von sehr schnell zu lesenden Daten übernimmt.
Im Jahr 2009 entstand Redis, geschrieben in C, aus der Idee, dass ein Cache gleichzeitig auch ein dauerhafter Speicherort sein kann. Damals versuchte Redis das Problem der zu langsamen, relationalen Datenbanken zu lösen, indem Cache & dauerhafter Speicher ein System wurden.
So ist Redis also ein Remote Dictionary Server, welcher Daten sehr schnell über den RAM (Memory) liest und verändert. Gleichzeit werden die Daten aber auf der, im Gegensatz zum Memory langsameren Disk, gespeichert um Daten bei z. B. einem Restart o. ä. rekonstruieren zu können.
Man spricht hier auch von Hot Values (RAM) und Warm Values (Disk).
Technisch gesehen werden die Daten in Key-Value-Pairs gespeichert, wobei die Value aus einem vom unterschiedlichsten Datentypen bestehen kann. Standardmässig unterstützt Redis die gängigsten Datentypen wie String, Lists, Sets und Maps (Hashes).
Selbstverständlich lässt sich Redis auch in unterschiedlichen High Availability Architekturen betreiben. #Datenspeicherung Wie speichert Redis genau seine Daten?
Grundlegend gibt es vier unterschiedliche Arten, wir Redis seine Daten speichert bzw. wie und wann die Daten wieder verfügbar sind.
No Persistence
Die erste uns einfachste Speicherung ist die no persistence oder ephemeral Storage. Hierbei sind alle Daten verloren, sobald der Server neu gestartet wird. Nutzt man ein Application Cache ohne Redis hat man meist den gleichen Effekt, die Daten werden im Memory der Applikation abgelegt, bei einem Restart ist alles weg.
RDB
Die sogenannte Redis Database erlaubt es uns, Daten zu persistieren. Dabei wird die Lese und Schreiboperationen weiterhin in Memory abgehandelt, es wird zusätzlich in einem bestimmten Interval ein Snapshot generiert. Auch bei einem normalen, graceful Shutdown wird ein Snapshot geschrieben. Dieser Snapshot wird auf einem durable (dauerhaften) Storage wie z. B. einem File-Mount gemacht. Standardmässig handelt es sich hierbei um ein JSON File, welches beim erneuten Starten des Redis Servers eingelesen wird.
Vorteile:
- einfaches, “normales” Snapshot Backup
- konfigurierbares Interval
Nachteile:
- Das Risiko eines geringen Datenverlustes besteht! Konfiguriert man das Snapshotting auf fünf Minuten und es kommt nach vier Minuten zu einem ausserordentlichen Shutdown des Servers verliert man die Daten der letzten vier Minuten.
- Bei sehr grossen Datenmengen kann es zu Peeks in der Performance kommen, da grosse Mengen an Daten auf eine Festplatte (Disk IO) geschrieben werden müssen
AOF
Der sogenannte Append Only File Mechanismus schreibt alle an Redis kommenden Schreiboperationen in ein Log und führt diese beim Serverstart wieder aus. Hierfür wird das gleiche Format genutzt wie beim eigentlichen Redis Protokoll. Auch hier kann ein Interval konfiguriert werden, per default werden die Anweisungen jede Sekunde geschrieben (fsync). Es kann aber auch konfiguriert werden, dass jede Query direkt geloggt wird.
Vorteile:
- Kein oder kaum Datenverlust
- Append Only Files können nicht korrupt werden und sind immer lesbar, keine Merge Konflikte
- Automatischer Rewrite Mechanisms, wenn Dateien zu gross werden
- Alle Commands sind einfach in der korrekten Reihenfolge abgelegt und zu lesen Nachteile:
- Im Vergleich zu einem RDB Dataset ist die Dateigrösse hier höher
- Die Performance kann, je nach fsync Policy bei grossen Datenmengen beeinträchtigt werden. Mit
every secondist die Performance aber immer noch sehr gut - Der zugrunde liegenden Prozess ist minimal komplexer und anfälliger im Vergleich zu AOF
RDB + AOF
Es ist sogar möglich, beide Speicherarten parallel zu betreiben. Hier ist anzumerken, dass bei einem Restart das AOF File für das Rekonstruieren genutzt wird.
Die Vor- & Nachteile sind hier schwer zu beziffern, da die beiden Mechanismen ihre Nachteile gegenseitig ausmerzen.
Zusammengefasst
Grundsätzlich sollte man beide Methoden zur Datenspeicherung nutzen, wenn man eine Datensicherheit analog einer PostgreSQL Datenbank haben will. Es gibt auch Use Cases für jeden einzelnen Mechanismus, Redis selbst empfiehlt aber die Kombination aus beidem.
Langfristig will Redis beide Methoden in ein Single Persistence Model packen, damit dem Benutzer die Entscheidung abgenommen wird.
Einsatzgebiet
Cache
Damals wurde Redis lediglich als Key Value Store bezeichnet und wurde direkt als Cache eingesetzt um die Performance-intensiven Calls zu einer Datenbank abfedern zu können.
In den meisten Fällen ist es so, dass die Datenbank, beispielsweise eine Relationale SQL Datenbank wie Postgres, MySql o. ä. das Bottleneck für die Performance ist. Klassischerweise implementiert man einen sogenannten In Memory Cache, der entweder direkt in der Applikation oder dezentral liegt.
Im Cloud Umfeld bietet sich der dezentrale Ansatz, ein sogenanntes Distributed Caching an. Dies bietet viele Vorteile, unter anderem kann der Cache von mehreren MicroServices gleichzeitig verwendet werden. Ausserdem verliert man bei einem Restart oder Deployment der Applikation den Cache nicht.
Die Anwendung selbst fungiert hierbei als Steuerzentrale, aus welcher Datenquelle (Cache(flüchtig) oder Datenbank(dauerhaft)) die Daten genommen werden.
Dieser Ansatz ist vollkommen legitim, man muss sich aber bewusst sein, dass man mehrere Dateispeicherorte, einen höheren Traffic mit Latenz und generell eine höhere Komplexität hat.
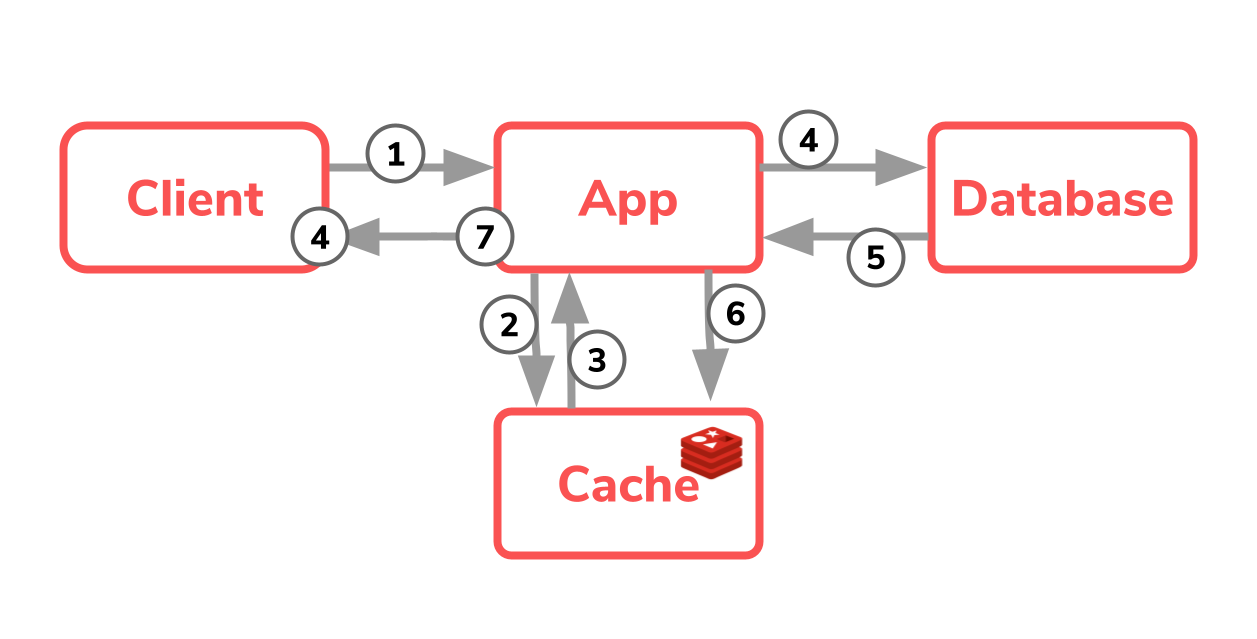
Schauen wir uns diese Architektur im Detail genauer an, stellt man schnell fest, dann vier bzw. sieben Schritte notwendig sind, um die Daten abzufragen. Die Applikation nimmt die Anfrage des Benutzers entgegen und muss erst prüfen, ob die gewünschten Daten bereits im Cache liegen. Sind diese dort vorhanden, so können diese direkt an den Benutzer zurückgegeben werden, der Request konnte mit vier Schritten sehr schnell abarbeitet werden.
Liegen die Daten aber noch nicht im Cache so muss die Applikation eine Abfrage zur ausgelasteten und langsamen Datenbank machen. Diese Daten nimmt die Applikation dann entgegen und füllt diese in den Cache ab. So konnte die Anfrage in sieben Schritten abgearbeitet werden.
Für den Entwickler selbst ist diese Architektur wichtig zu verstehen und ein ständiger “Kontextswitch” ist nötig.
Grundsätzlich hat diese Architektur ganz klar ihre Daseinsberechtigung, beispielsweise wenn man die Datenquelle nicht anpassen kann, es ein Soap- oder Rest Webservice o. ä. ist.
Primärer Datenspeicher
Am 08.01.2020 veröffentlichte Redis einen Blogpost mit dem Titel Goodbye Cache: Redis as Primary Database. Damit war klar, wohin die Reise gehen soll, heute kann und soll Redis vollständig als Primary Datastore eingesetzt werden.
Hierbei vereint man den Cache und den Datenspeicherort aus dem ersten Diagram und sort so für einen einzigen Prozess zum Schreiben und Abholen der Daten.
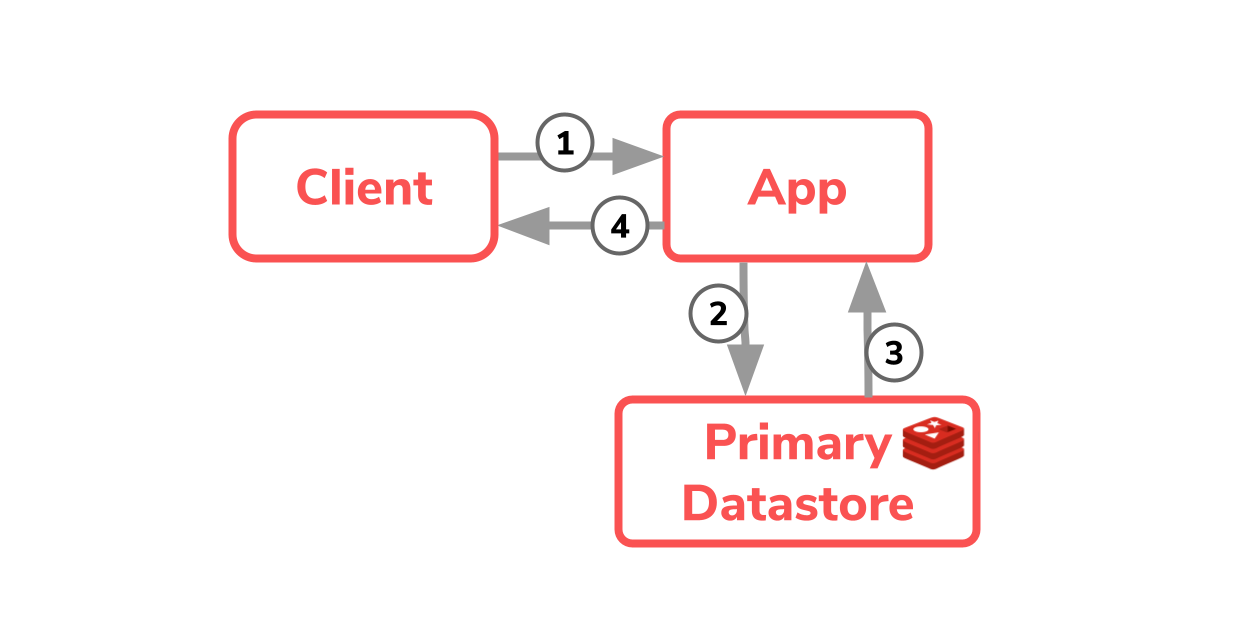
So können in nur vier Schritten die Daten abgefragt werden, ohne weitere fachliche oder technische Logik wie beim Caching in der Applikation. Ausserdem widerspiegelt Redis hier sie sogenannte Single Source of Truth, die Daten liegen nur an einem einzigen Ort.
Die Vorteile diese Lösung liegen somit klar auf der Hand:
- Einfacher Datenspeicherprozess, kein Context-Switching für den Entwickler
- sehr schneller, skalierbarer, flexibler, NoSQL Datenspeicher
- Stark und beliebt in der Community, Redis wurde zum Dritten Mal in Folge zur Most loved database gewählt
Wie bei jeder Komponente in der Softwareentwicklung sollte man sich auch hier vorab fragen, ob Redis die passende Lösung ist. In den meisten Fällen ist die Datenstruktur sowie die Komplexität der Querys sehr simple, hier ist Redis wie gemacht für diesen Use Case. Kommt es zu komplexeren Datenstrukturen und vor allem Querys wie Joins usw. sollte man den Einsatz von Redis als primären Datenspeicher nochmals überdenken.
Nachteile, ausser in sehr komplexen UseCases, bringt dieser Ansatz eigentlich nicht mit sich. Konfiguriert man die Datenspeicherung von Redis selbst hat man eine sehr schnelle Im Memory mit 100 % Datensicherheit als primäre Datenquelle! 🚀
Wichtig ist noch zu erwähnen, dass Redis mit sogenannten Modules erweitern werden kann. So kann man beispielsweise eine Full Text Search installieren oder direkt JSON Werte in Redis speichern. Die Modules beschränken sich hierbei teilweise auf die Redis Enterprise Version.
Redis in der Praxis
Nun wollen wir beide Use Cases in der Praxis anschauen. In diesen TechUp wollen wir bewusst nicht zu Quarkus oder Golang als Beispielapplikation greifen. Aufgrund langjähriger Erfahrung und eines konkreten UseCases bei einem Kunden wollen wir Redis in Kombination mit Spring Boot kennenlernen.
Wir nutzen hier im Beispiel ein Spring Boot Maven Projekt, welches wir direkt über IntelliJ starten.
Redis läuft in einem Docker Container, der einfachheit halber nutzen wir:
|
|
Caching
Zuerst wollen wir einen exemplarische Spring Boot Anwendung, schreiben und diese mit einem Cache versehen. Hierfür haben wir bereits ein Projekt vorbereitet, welches einen Endpunkt /api/getvalue exponiert, einen Key entgegennimmt und anhand dieses Keys ein Value aus einer Textdatei ausliest. Die Textdatei fungiert hier exemplarisch als unsere Datenbank, diesen Call wollen wir mithilfe von Redis cachen.
Die Cache-Integration in Spring Boot ist einfach und simple, man benötigt zwei Maven Dependencies, einige wenige Konfigurationen und eine Annotation.
Nachfolgend ist eine exemplarische Redis Cache Configuration zu sehen:
|
|
Wir definieren hier einen generellen Cache von 10-sekündiger Dauer und spezifizieren dann einen Custom Cache mit dem Namen “keyValueCache” mit einer Dauer von 20 Sekunden.
Standardmässig connected sich Redis über localhost:6379, selbstverständlich kann dieser Endpunkt angepasst werden.
In einem Real World Case würde hier z. B. ein dedizierter Endpunkt seine Anwendung finden.
Nun müssen wir noch unsere Methode, welche gecached werden soll, annotieren. Hier ist wichtig zu beachten, dass der Cache nur funktioniert, wenn die Methode von ausserhalb, nicht von innerhalb der Klasse, aufgerufen wird. Spring Cache setzt hier eine Proxy Class davor, um das Cache Handling zu steuern und zu implementieren.
So sieht unsere Dao Methoden, welche das File aufruft und liesst, nun aus:
|
|
Über diese Annotation steuern wir gleichzeitig, um welche Cache Spezifikation, hier “keyValueCache”, es sich handelt.
Im Log sehen wir bei einem Call zu http://localhost:8080/api/getvalue?key=abc dann, dass einmalig das Dao aufgerufen wird und anschliessend, für 20 Sekunden, nur noch der Service.
|
|
Cool, oder? So einfach und schnell haben wir einen distributed Cache mit Redis implementiert! 🚀
Primärer Datenspeicher
Nun wollen wir Redis als primären Datenspeicher nutzen und dort Daten über unsere Lieblingsfilme abspeichern.
Die Dependency spring-boot-starter-data-redis liefert uns sowohl die Spring Data Abstrahierung sowie den eigentlichen Redis Client.
Hierfür definieren wir uns zuerst ein Model und annotieren dies mit RedisHash um dies nutzen zu können:
|
|
Anschliessend nutzen wir das CrudRepository Interface von Spring Data und spezifizieren die Generics für unser eigenes Dao Interface.
Das Standardinterface liefert uns hier eine Abstraction für alle nötigen Operation wie Create Read Update Delete.
|
|
Und nun können wir unser Dao Interface direkt im Service nutzen, neue Filme anlegen und Filme abfragen:
|
|
Hier in diesem Beispiel nutzen wir die Standardkonfiguration von Spring Data Redis, selbstverständlich kann auch diese angepasst werden.
Nutzen wir das Redis CLI Command HGETALL Movie:1 können wir unser Model im Redis Datastore genauer unter die Lupe nehmen:
|
|
Hier ist schön zu sehen, dass hinter dem Key Movie:1 sich eine Art Liste befindet, wobei die Werte abwechselnd immer Key / Value Werte sind.
Aus diesen Informationen kann Redis dann mit dem Sprint Data Connector das eigentliche Java MovieModel wieder zusammenbauen.
Redis CLI
Zu guter Letzt wollen die den Redis Container noch etwas genauer anschauen und uns mit der CLI vertraut machen.
Connecten wir uns auf den Container können wir mit redis-cli direkt die CLI starten und mit Commands unser Redis genauer kennenlernen.
|
|
Im Order /data finden wir dann die Snapshot bzw. AOF Files und können diese z. B. genauer anschauen oder sichern.
Fazit
Sie brauchen eine Möglichkeit, ihre langsamen Datenbanken zu entlasten oder simple Daten einfach und schnell zu speichern? Redis! 🚀
Je nach UseCase bietet Redis Ihnen genau die Möglichkeiten an, die Sie benötigen!
Redis ist sicher nicht umsonst das dritte Mal hintereinander als Most loved database gekürt worden, es ist unglaublich schnell, einfach zu bedienen und bietet eine grosse Sicherheit dank Backup- & Rekonstruktionsmechanismen.
In einem weiteren TechUp wollen wir die Unterschiede zwischen Redis, Etcd und TiKV genauer erkunden.
Sie benötigen Unterstützung, haben Fragen oder möchten eine Diskussion anregen? Kontaktieren Sie uns!