Fehler oder Ausfälle im produktiven System führen oft zu Stress, Ärger und Missgunst. Fehler oder Ausfälle bewusst herbeizuführen und die Systeme dadurch stabiler und weniger anfällig zu machen führt immer zu Erfolg, Freude, Ansehen und Verbesserung!
Rückblick
Bereits in einem früheren TechUp hat Raffi über unsere We Celebrate Failure Kultur berichtet. Grundsätzlich geht darum, eine aktive Fehlerkultur zu leben, an Fehlern zu wachsen und Schlüsse daraus zu ziehen.
Im Cloud Umfeld gibt es sogenannte Chaos Engineering Tools wie beispielsweise Gremlin oder Litmus. Wenn Sie mehr über die theoretischen Hintergründe oder über Gremlin an sich erfahren wollen lege ich Ihnen das TechUp Wie Sie eine ‘We Celebrate Failure’-Kultur mit Chaos Engineering in ihr Daily Business einführen. sehr ans Herzen!
Mit Gremlin haben wir bereits einen closed-source, enterprise-facing Player im Chaos Engineering Teil der altbekannten CNCF Landscape kennengelernt. Heute wollen wir den Schritt in richtig Open Source Chaos Engineering wagen.
Litmus
Litmus ist ein open-source, CNCF Sandbox Chaos Engineering Projekt, welches direkt von der Cloud Native Computing Foundation (CNCF) entwickelt wird. Seit 2018 sorgen über 150 Contributors für regelmäßige Updates und Releases. Das Ziel, ein CNCF Incubating Project zu werden wird klar kommuniziert und verfolgt.
Litmus selbst startete als complete framwork for finding weaknesses in Kubernetes platforms and applications running on Kubernetes, betitelt sich nun aber mehr als Cloud Native Chaos Engineering platform.
Nichtsdestotrotz kann Litmus nur in einem Kubernetes Cluster verwendet werden, es gibt aber Anbindungen für andere Resource wie AWS, GCP oder Azure.
Ihre aktuelle Mission lautet:
|
|
Zu den bekannten Contributors gehören unter anderem ChaosNative, Intuit, Amazon, RedHat und Container Solutions.
Erst im August dieses Jahres wurde die berühmt-berüchtigte Version 2.0.0 veröffentlicht. Bei der Version 2 handelte es sich um einen Release mit sehr vielen, weitgehenden Feature-Erweiterungen. Grundlegend kann man sagen, dass bei Version 2 sehr viele enterprise-facing Funktionen dazu kamen. Hervorzugehen sind zwei grundsätzliche Neuerungen, neu gibt es ein GitOps Pattern mit einer Integration mit Argo Workflows und eine neue WebUi. So lässt sich nun das komplette Chaos via WebUi und nicht mehr nur via CLI steuern.
Litmus selbst setzt hier vollständig auf den Prinzipien des Cloud native Chaos Engineering chaosnative.com/ auf, welche beispielsweise folgende Eigenschaften beinhalten:
- Open Source
- Community Collaboration
- Open API
- GitOps
- Open Observability
Bevor wir uns Hands-On an Litmus wagen, wollen wir die einzelnen Komponenten und Features kennenlernen.
Chaos Experiments
Einfach gesagt beinhaltet ein Chaos Experiment die Anweisungen für das eigentliche Chaos. Die Kubernetes Custom Resource definiert Parameter wie das Image, die nötigen Permissions usw.
Ein klassisches Beispiel hier wäre ein sogenanntes pod-delete Experiment, welches einen bestimmten Pod abschalten.
So kann man beispielsweise die Ausfallsicherheit prüfen.
Aktuell gibt es über 50 Experiments in unterschiedlichen Gruppe wie generic, cordns, kube-aws, kafka, gcp und weitere.
In der Vergangenheit waren viele Experimente in Ansible geschrieben, diese wurden zum grössten Teil mit Version 2 auf Go Lang portiert. Dank einer SDK, welche aktuell für Go, Python und Ansible verfügbar ist lassen sich eigene Experiments schreiben.
Probes
Probes sind im Litmus Umfeld modulare Prüfungen, um den Zustand des Chaoses zu bewerten. Grundsätzlich können diese Checks für normale Health-Checks benutzt werden. Sie bestimmen, ob ein Experiment erfolgreich war oder ob es ungewollte Auswirkungen wie einen Ausfall einer Schnittstelle gab.
Aktuell gibt es vier unterschiedliche Arten von Probes:
- httpProbe – Aufruf einer URL, prüfen des Ergebnisses (z.B. anhand des HttpStatusCodes)
- cmdProbe – Ausführen eines Shell Commands, Exit Code wird beachtet
- k8sProbe – Ausführen einer CRUD Operation gegen native oder custom Kubernetes Ressourcen
- promProbe – Ausführen einer PromQL Query und Prometheus Metrics zu matchen
Selbstverständlich können verschiedene Probes kombiniert werden.
Hier ist zu beachten, dass man z. B. bei einer httpProbe den korrekten Endpunkt vom Kubernetes Service verwendet. Ist diese Probe falsch definiert, kann es schnell zu verfälschten Ergebnissen kommen.
Chaos Workflow
Ein Chaos Workflow ist ein Set an unterschiedlichen Chaos Operationen, welche gemeinsam ein Szenario im Kubernetes Cluster bilden. Diese Steps können entweder nacheinander oder parallel ausgeführt werden. Hinter all dem Steck ein Argo CD Workflow, welcher mehrere Experimente beinhaltet.
Grundlegend gibt es zwei Arten, normale Workflows, welche nur einmal laufen oder sogenannte CronWorkflows, welche automatisiert zu einer definierten Schedule laufen. So lässt sich ChaosEngineering zum Beispiel fest einplanen und automatisieren. Dies macht aus unterschiedlichsten Punkten Sinn, grundsätzlich sollte Chaos Engineering immer ein iterativer, wiederkehrender Prozesse sein. Mit einem Workflow können nicht nur Experiments installiert und damit Chaos ausgelöst werden, es gibt auch Steps, welche das Chaos wieder rückgängig machen können.
Ein solcher Workflow kann entweder per YAML geschrieben werden oder mittels der GUI im Chaos Center zusammengebaut werden.
Chaos Result
Ein Chaos Result stellt das eigentliche Resultat des Chaos Experiments dar. Hierbei handelt es sich ebenfalls um eine Kubernetes Custom Resource Definition, welche Informationen wie den Status usw. beinhaltet. Diese CR wird zur Laufzeit von unterschiedlichen Pods oder CronJobs aus aktualisiert, sodass immer der aktuellste Stand des einzelnen Experiments darin enthalten ist. Ausserdem wird es nicht als Teil des normalen Clean-Up Prozesses gelöscht und kann für weitere Auswertungen genutzt werden.
Chaos Hub
Das Chaos Hub fugiert als öffentlicher Market Place für Litmus Chaos Experiment. Konkret werden hier YAML Files für die sogenannten Litmus Chaos Experiments gehosted. Neben dem öffentlichen Hub gibt es auch eine Möglichkeit, einen oder mehrere privat Hubs zu betreiben und zu nutzen.
Technisch gesehen handelt es sich sowohl bei einem public als auch bei einem privaten Chaos Hub um ein Git Repository, welches angebunden wird.
Chaos Center
Der ChaosCenter ist das Herzstück von Litmus, er stellt die Single Source of Truth für die Kontrolle aller unterschiedlichen Chaos Aktivitäten dar.
Diese Web-UI ist Teil der eigentlichen Installation und lässt sich in einem Kubernetes Cluster einfach via Ingress, NodePort oder LoadBalancer verfügbar machen. Seit ver Version 2 erfreut sich diese UI grosser Beliebtheit, da sämtliche Administration, Auswertung usw. nicht mehr per CLI, wie in Version 1, gemacht werden muss. Durch die Multi-Cloud Fähigkeit mittels Chaos Agents kann der ChaosCenter unabhängig vom eigentliche Ziel-Chaos-Cluster deployed und genutzt werden.
Neben den Funktionalitäten für die Workflowerstellung und Ausführen bietet das ChaosCenter auch einen RBAC Administrationsbereich, eine Sektion für Monitoring & Observability sowie weitere Konfigurationsmöglichkeiten wie z.B. GitOps.
Chaos Agent
Der ChaosAgent fungiert als Prozess, welcher im Zielcluster, in dem Chaos ausgelöst werden soll, installiert wird und läuft. Hier gibt es zwei Arten von Agent, den Self und den External Agent. Beim Self Agent wird das Chaos in das “lokale” Cluster injected, wo auch der ChaosCenter deployed ist. Dies ist der simple Use Case, wo Litmus im selben Cluster wie die eigentliche Applikation installiert ist.
Mit dem External Agent lassen sich weitere Cluster bei unterschiedlichen Cloud-Providern (Multi Cloud) anbinden.
Hierfür wird mit der hauseigene litmusctl ein Agent im entsprechenden Zielcluster installiert.
Chaos Observability
Unter diesem Bereich versteht man alle Metriken und Statistiken, welche bei einem Chaos Durchlauf so gesammelt werden, Litmus bietet hier die Möglichkeit, all diese Daten in einem Prometheus Format zu exportieren.
Hands On
Installation
Um Litmus nun ausprobieren zu können benötigen wir ein Kubernetes Cluster, wir in unserem Fall nutzen miniKube.
Leider müssen wir aufgrund eines Fehlers eine veraltete Kubernetes Version nutzen (< v1.22.x):
|
|
Nachdem unser Kubernetes Cluster läuft, wollen wir Litmus via Helm Chart in einen speziellen Namespace installieren.
|
|
Anschliessend können wir via kubectl get pods -n litmus prüfen, ob unsere drei Litmus Pods laufen.
Hier sehen wir nun direkt drei Pods, ein Frontend, ein Server und eine MongoDB.
Litmus nutzt die MongoDB hier um alle relevanten Daten, Logs usw. zum eigentlichen Chaos zu speichern.
Das Frontend stellt den eigentlichen Chaos-Center dar und der Server Pod fungiert als API Zentrale.
Chaos Center
Sobald diese alle Running sind, wollen wir uns das ChaosCenter Dashboard genauer anschauen.
Hierfür nutzen wir die NodePort Adresse des litmusportal-frontend-service, mit MiniKube müssen wir hier aber erst noch mit folgendem Befehl einen Tunnel aufmachen:
|
|
Anschliessend können wir uns dann mit den Daten admin/litmus einloggen und sind erfolgreich im Chaos-Center gelandet!
Mit dem ersten Login startet Litmus einige weitere Pods, welche fürs Chaos benötigt werden. Technisch gesehen wurde ein Litmus Projekt (im Dashboard oben links) angelegt. All diese Pods werden für den Chaos Self Service benötigt, zusätzlich wird der Self Agent im Cluster installiert.
Glücklicherweise bietet Litmus ein komplettes Demoprojekt an, welches per Self Service installiert werden kann.
Dies können wir starten, in dem wir über den Button Schedule a workflow einen neuen Workflow starten.
Als Agent nutzen wir hier unseren Self Agent, anschliessend wählen wir den vordefinierten Chaos-Workflow podtato-head vom Litmus ChaosHub aus.
Im vierten Schritt wollen wir uns dann unsere Probe genauer anschauen.
Hier sehen wir beispielsweise, dass eine Variable für den Namespace genutzt wird und das Deployment mit dem Label name=podtato-main das Chaos abbekommen soll.
In den Einstellungen der httpProbe sehen wir dann weitere Informationen wie die URL, die eingestellten Timeouts und Intervalle und den erwarteten Response-Code von 200.
Im nächsten Schritt können wir dann mit dem Reliability Score das Gewicht dieses Workflows definieren. Da wir das Chaos sofort auslösen und austesten wollen wählen wir Schedule now und starten so das Chaos.
Nun wurde im Menü Litmus Workflows ein sogenannter Run dieses Workflows gestartet.
Über die Optionen können wir den Workflow im Details ansehen oder weitere Statistiken begutachten.
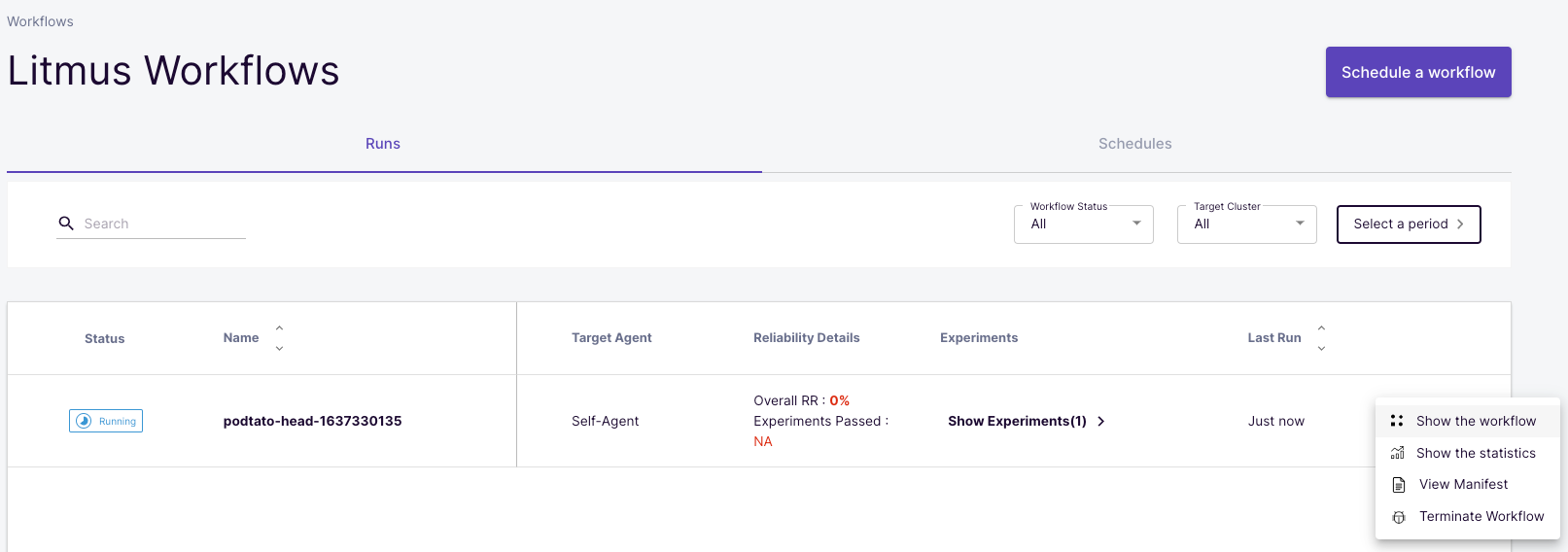
Dieser Workflow sollte erfolgreich durchlaufen und zeigt uns somit, dass das Löschen eines (oder mehrerer) Pods keinen Impact auf die Stabilität und Verfügbarkeit unserer Applikation hat!
Der erste eigene Workflow
Nun wollen wir aber einen eigenen Workflow für eine, aus anderen TechUps bekannte, Demoanwendung definieren.
Hierfür nutzen wir wieder die edgey-corp-nodejs-Applikation aus unsere Telepresence TechUp (Check it out!).
Diese starten wir via kubectl im default Namespace und öffnen anschliessend den Port um den K8s Service erreichen zu können.
|
|
Nachdem die Pods gestartet sind, können wir kurz über die URL aus dem MiniKube Befehl die einwandfreie Funktionalität der Anwendung prüfen, indem wir diese Url im Browser aufrufen.
Anschliessend fügen wir ein Label hinzu, um unsere Pods und Deployments eindeutig erkennen zu können. Hierfür nutzen wir ein auf dem Pods bereits vorhandenen Label auch für das Deployment.
|
|
Nun könnten wir zwar einen Workflow mit einer httpProbe mit der URL, welche wir via MiniKube im Browser aufrufen können, definieren.
Dies würde aber aus dem Cluster raus nicht funktionieren, daher müssen wir erst die korrekte URL für unseren Service herausfinden und dies aus dem litmus Namespace heraus verifizieren.
Technisch gesehen können wir hier nun entweder die interne IP der Services nehmen und wir nutzen den Kubernetes intern bekannten DNS Namen verylargejavaservice.default.svc.cluster.local.
Um einen kurzen Test zu machen, starten wir uns einen busybox Pod um einen curl aus dem litmus Namespace heraus absetzen zu können.
|
|
Den zweiten Befehl können wir nach kurzer Wartezeit ausführen, bekommen wir als Antwort eine HTML Struktur mit dem Title Welcome to the EdgyCorp WebApp sieht alles gut aus.
Nun aber schnell zu unserem ersten eigenen Litmus Workflow.
Wie bereits vorher starten wir einen neuen Workflow mit Schedule a workflow, wählen wieder den Self Agent und dann Create a new workflow using the experiments from ChaosHub.
Im vierten Schritt können wir nun ein Experiment hinzufügen und sehen hier einer Liste aller Experiment, welche aktuell auf dem öffentlichen ChaosHub verfügbar sind.
Der Einfachheit halber entscheiden wir uns wieder für das generic/pod-delete Szenario und konfigurieren dies wie folgt:
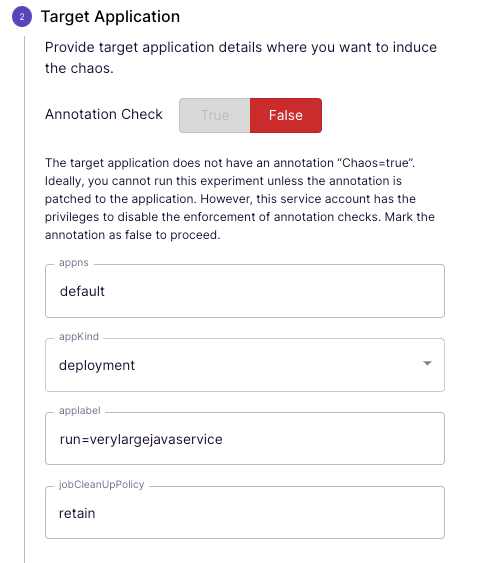
Sehr angenehm ist hier, dass Litmus die Namespaces, Labels usw. aus dem Cluster kennt und uns Vorschläge gibt.
Für die Probe nutzen wir wieder eine httpProbe und wollen die Calls auf den zuvor geprüften DNS Namen machen. Als Response erwarten wir in jedem Fall einen HTTP Response-Code von 200 (Success).
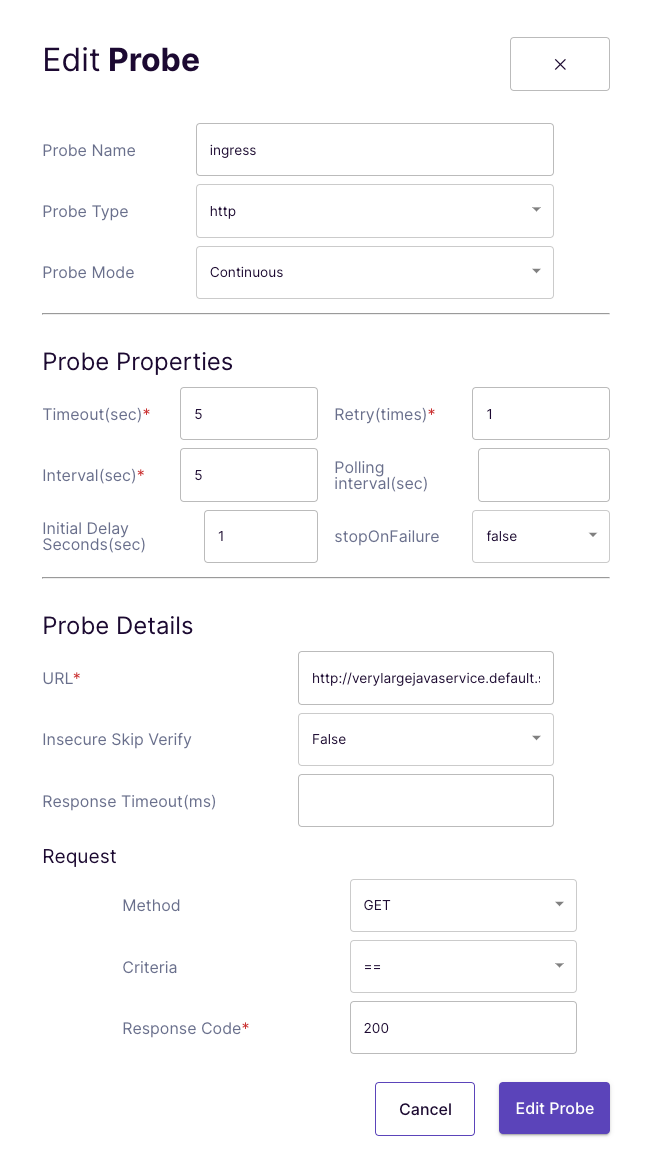
Wichtig ist hier, dass die Timeout entsprechend gesetzt sind, da die Probe sonst erkennt, dass Downtime vorliegt, obwohl eigentlich die Applikation “nur” zu langsam antwortet.
Die weiteren Schritte können wir alle mit Next bestätigen, im letzten Schritt können wir noch unser YAML genauer anschauen. Hier fällt sofort auf, dass es sich um ArgoCD Resource handelt. Bei einem GitOps Ansatz würde dieses YAML dann versioniert in ein Repository gepushed werden.
Ist unsere Applikation resilient?
Nachdem wir unseren Workflow angelegt haben wird dieser sofort gestartet. Nach kurzer Wartezeit sehen wir dann ernüchternd, dass das Resultat rot ist und wir einen Ausfall der Applikation hatten.

Über die Details des Workflows sehen wir die Logs sowie das Chaos Result und findet schnell raus, dass unsere httpProbe fehlgeschlagen ist.
Alleine durch das Ausführen des Befehls kubectl get deployments sehen wir den Grund für diesen Ausfall und die ausgebliebene Stabilität.
Sehen Sie es auch?
In unserem Experiment haben wir einen Pod gelöscht, da unser Deployment aber nur eine Replica hat kam es zu einem Ausfall.
Nun wollen wir aber ein Erfolgserlebnis haben und wollen unsere Applikation stabiler machen, hierfür skalieren die das Deployment auf insgesamt zwei Pods mit folgendem Befehl hoch:
|
|
Nach kurzer Wartezeit sehen wir, das nun zwei Pods unseres Services laufen. Im Menüpunkt Litmus Workflows können wir nun im Tab Schedules ein Rerun anstossen, um unser Chaos erneut auszulösen.

Nun sehen wir, dass der Workflow eine 100 % Stabilität anzeigt und wir somit unsere Applikation erfolgreich getestet und verbessert haben! 🚀
Vor & Nachteile
Ein ganz klarer Vorteil ist der GitOps Ansatz von Litmus. Oft hat man eine tolle, gut funktionierende Web Ui um Ressourcen anzulegen oder zu verwalten, die Changes werden meist aber direkt im Cluster appliziert und nirgends persistiert. Litmus bietet hier die Einstellungsmöglichkeit, sämtliche Resource via GitOps Prozess in einem Repository als Single Source of Truth zu speichern. Ein weiterer Vorteil ist der Einsatz von ArgoCD Workflows under the hood. Dies macht Litmus zuverlässig und stabil und sort ebenso für einen Yaml-basierten Ansatz.
Grundsätzlich ist sicher auch der Open Source Ansatz mit bekannten Contributors und wirklich breitem Funktionsumfang ein Vorteil.
Ein klarer Nachteil ist aktuell sicherlich die Kompatibilität, Litmus war in unserem Test nicht mit der neuesten Kubernetes Version nutzbar, hier muss klar nachgelegt werden. Ausserdem hört man oft das Argument, dass Litmus “nur” für Chaos Engineering im Kubernetes Umfeld, nicht aber in der Infrastruktur eingesetzt werden sollte. Hier wird eventuell auch noch nachgebessert, beispielsweise könnten noch mehr Experiments für die eigentliche Infrastruktur wie AWS o. ä. angeboten werden.
Fazit
Litmus will Grosses erreichen, das steht fest!
Leider kam es beim Ausprobieren immer wieder zu Problemen, welche im Guide nicht direkt beschrieben waren. Diese werden aber sicherlich zeitnah behoben, dann steht einem Open Source Chaos Engineering mit Litmus nichts mehr im Wege.
Stay tuned!